爬虫源码1
Posted zhoulixiansen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫源码1相关的知识,希望对你有一定的参考价值。
# -*- coding: utf-8 -*- import re import scrapy import datetime from scrapy.http import Request from urllib import parse from scrapy.loader import ItemLoader import time from ArticleSpider.items import JobBoleArticleItem, ArticleItemLoader from ArticleSpider.utils.common import get_md5 class JobboleSpider(scrapy.Spider): name = "jobbole" allowed_domains = ["python.jobbole.com"] start_urls = [‘http://python.jobbole.com/all-posts/‘] def parse(self, response): """ 1. 获取文章列表页中的文章url并交给scrapy下载后并进行解析 2. 获取下一页的url并交给scrapy进行下载, 下载完成后交给parse """ #解析列表页中的所有文章url并交给scrapy下载后并进行解析 post_nodes = response.css("#archive .floated-thumb .post-thumb a") for post_node in post_nodes: image_url = post_node.css("img::attr(src)").extract_first("") post_url = post_node.css("::attr(href)").extract_first("") yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url":image_url}, callback=self.parse_detail) #提取下一页并交给scrapy进行下载 next_url = response.css(".next.page-numbers::attr(href)").extract_first("") if next_url: yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse) def parse_detail(self, response): article_item = JobBoleArticleItem() #提取文章的具体字段 # title = response.xpath(‘//div[@class="entry-header"]/h1/text()‘).extract_first("") # create_date = response.xpath("//p[@class=‘entry-meta-hide-on-mobile‘]/text()").extract()[0].strip().replace("·","").strip() # praise_nums = response.xpath("//span[contains(@class, ‘vote-post-up‘)]/h10/text()").extract()[0] # fav_nums = response.xpath("//span[contains(@class, ‘bookmark-btn‘)]/text()").extract()[0] # match_re = re.match(".*?(d+).*", fav_nums) # if match_re: # fav_nums = match_re.group(1) # # comment_nums = response.xpath("//a[@href=‘#article-comment‘]/span/text()").extract()[0] # match_re = re.match(".*?(d+).*", comment_nums) # if match_re: # comment_nums = match_re.group(1) # # content = response.xpath("//div[@class=‘entry‘]").extract()[0] # # tag_list = response.xpath("//p[@class=‘entry-meta-hide-on-mobile‘]/a/text()").extract() # tag_list = [element for element in tag_list if not element.strip().endswith("评论")] # tags = ",".join(tag_list) #通过css选择器提取字段 # front_image_url = response.meta.get("front_image_url", "") #文章封面图 # title = response.css(".entry-header h1::text").extract()[0] # create_date = response.css("p.entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip() # praise_nums = response.css(".vote-post-up h10::text").extract()[0] # fav_nums = response.css(".bookmark-btn::text").extract()[0] # match_re = re.match(".*?(d+).*", fav_nums) # if match_re: # fav_nums = int(match_re.group(1)) # else: # fav_nums = 0 # # comment_nums = response.css("a[href=‘#article-comment‘] span::text").extract()[0] # match_re = re.match(".*?(d+).*", comment_nums) # if match_re: # comment_nums = int(match_re.group(1)) # else: # comment_nums = 0 # # content = response.css("div.entry").extract()[0] # # tag_list = response.css("p.entry-meta-hide-on-mobile a::text").extract() # tag_list = [element for element in tag_list if not element.strip().endswith("评论")] # tags = ",".join(tag_list) # # article_item["url_object_id"] = get_md5(response.url) # article_item["title"] = title # article_item["url"] = response.url # try: # create_date = datetime.datetime.strptime(create_date, "%Y/%m/%d").date() # except Exception as e: # create_date = datetime.datetime.now().date() # article_item["create_date"] = create_date # article_item["front_image_url"] = [front_image_url] # article_item["praise_nums"] = praise_nums # article_item["comment_nums"] = comment_nums # article_item["fav_nums"] = fav_nums # article_item["tags"] = tags # article_item["content"] = content #通过item loader加载item front_image_url = response.meta.get("front_image_url", "") # 文章封面图 item_loader = ArticleItemLoader(item=JobBoleArticleItem(), response=response) item_loader.add_css("title", ".entry-header h1::text") item_loader.add_value("url", response.url) item_loader.add_value("url_object_id", get_md5(response.url)) item_loader.add_css("create_date", "p.entry-meta-hide-on-mobile::text") item_loader.add_value("front_image_url", [front_image_url]) item_loader.add_css("praise_nums", ".vote-post-up h10::text") item_loader.add_css("comment_nums", "a[href=‘#article-comment‘] span::text") item_loader.add_css("fav_nums", ".bookmark-btn::text") item_loader.add_css("tags", "p.entry-meta-hide-on-mobile a::text") item_loader.add_css("content", "div.entry") article_item = item_loader.load_item() yield article_item
在scrapy中获取属性是::attr(src)
yield Request()中的callback指向需要处理的方法例如self.parse
注意:在scrapy中的items.py就好像django中的models
如下:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import datetime import re import scrapy from scrapy.loader import ItemLoader from scrapy.loader.processors import MapCompose, TakeFirst, Join from utils.common import extract_num from settings import SQL_DATETIME_FORMAT, SQL_DATE_FORMAT from w3lib.html import remove_tags class ArticlespiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass def add_jobbole(value): return value+"-bobby" def date_convert(value): try: create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date() except Exception as e: create_date = datetime.datetime.now().date() return create_date def get_nums(value): match_re = re.match(".*?(d+).*", value) if match_re: nums = int(match_re.group(1)) else: nums = 0 return nums def return_value(value): return value def remove_comment_tags(value): #去掉tag中提取的评论 if "评论" in value: return "" else: return value class ArticleItemLoader(ItemLoader): #自定义itemloader default_output_processor = TakeFirst() class JobBoleArticleItem(scrapy.Item): title = scrapy.Field() create_date = scrapy.Field( input_processor=MapCompose(date_convert), ) url = scrapy.Field() url_object_id = scrapy.Field() front_image_url = scrapy.Field( output_processor=MapCompose(return_value) ) front_image_path = scrapy.Field() praise_nums = scrapy.Field( input_processor=MapCompose(get_nums) ) comment_nums = scrapy.Field( input_processor=MapCompose(get_nums) ) fav_nums = scrapy.Field( input_processor=MapCompose(get_nums) ) tags = scrapy.Field( input_processor=MapCompose(remove_comment_tags), output_processor=Join(",") ) content = scrapy.Field() def get_insert_sql(self): insert_sql = """ insert into jobbole_article(title, url, create_date, fav_nums, front_image_url, front_image_path, praise_nums, comment_nums, tags, content) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE content=VALUES(fav_nums) """ fron_image_url = "" # content = remove_tags(self["content"]) if self["front_image_url"]: fron_image_url = self["front_image_url"][0] params = (self["title"], self["url"], self["create_date"], self["fav_nums"], fron_image_url, self["front_image_path"], self["praise_nums"], self["comment_nums"], self["tags"], self["content"]) return insert_sql, params class ZhihuQuestionItem(scrapy.Item): #知乎的问题 item zhihu_id = scrapy.Field() topics = scrapy.Field() url = scrapy.Field() title = scrapy.Field() content = scrapy.Field() answer_num = scrapy.Field() comments_num = scrapy.Field() watch_user_num = scrapy.Field() click_num = scrapy.Field() crawl_time = scrapy.Field() def get_insert_sql(self): #插入知乎question表的sql语句 insert_sql = """ insert into zhihu_question(zhihu_id, topics, url, title, content, answer_num, comments_num, watch_user_num, click_num, crawl_time ) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE content=VALUES(content), answer_num=VALUES(answer_num), comments_num=VALUES(comments_num), watch_user_num=VALUES(watch_user_num), click_num=VALUES(click_num) """ zhihu_id = self["zhihu_id"][0] topics = ",".join(self["topics"]) url = self["url"][0] title = "".join(self["title"]) content = "".join(self["content"]) answer_num = extract_num("".join(self["answer_num"])) comments_num = extract_num("".join(self["comments_num"])) if len(self["watch_user_num"]) == 2: watch_user_num = int(self["watch_user_num"][0]) click_num = int(self["watch_user_num"][1]) else: watch_user_num = int(self["watch_user_num"][0]) click_num = 0 crawl_time = datetime.datetime.now().strftime(SQL_DATETIME_FORMAT) params = (zhihu_id, topics, url, title, content, answer_num, comments_num, watch_user_num, click_num, crawl_time) return insert_sql, params class ZhihuAnswerItem(scrapy.Item): #知乎的问题回答item zhihu_id = scrapy.Field() url = scrapy.Field() question_id = scrapy.Field() author_id = scrapy.Field() content = scrapy.Field() parise_num = scrapy.Field() comments_num = scrapy.Field() create_time = scrapy.Field() update_time = scrapy.Field() crawl_time = scrapy.Field() def get_insert_sql(self): #插入知乎question表的sql语句 insert_sql = """ insert into zhihu_answer(zhihu_id, url, question_id, author_id, content, parise_num, comments_num, create_time, update_time, crawl_time ) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE content=VALUES(content), comments_num=VALUES(comments_num), parise_num=VALUES(parise_num), update_time=VALUES(update_time) """ create_time = datetime.datetime.fromtimestamp(self["create_time"]).strftime(SQL_DATETIME_FORMAT) update_time = datetime.datetime.fromtimestamp(self["update_time"]).strftime(SQL_DATETIME_FORMAT) params = ( self["zhihu_id"], self["url"], self["question_id"], self["author_id"], self["content"], self["parise_num"], self["comments_num"], create_time, update_time, self["crawl_time"].strftime(SQL_DATETIME_FORMAT), ) return insert_sql, params def replace_splash(value): return value.replace("/", "") def handle_strip(value): return value.strip() def handle_jobaddr(value): addr_list = value.split(" ") addr_list = [item.strip() for item in addr_list if item.strip() != "查看地图"] return "".join(addr_list) class LagouJobItemLoader(ItemLoader): #自定义itemloader default_output_processor = TakeFirst() class LagouJobItem(scrapy.Item): #拉勾网职位 title = scrapy.Field() url = scrapy.Field() salary = scrapy.Field() job_city = scrapy.Field( input_processor=MapCompose(replace_splash), ) work_years = scrapy.Field( input_processor=MapCompose(replace_splash), ) degree_need = scrapy.Field( input_processor=MapCompose(replace_splash), ) job_type = scrapy.Field() publish_time = scrapy.Field() job_advantage = scrapy.Field() job_desc = scrapy.Field( input_processor=MapCompose(handle_strip), ) job_addr = scrapy.Field( input_processor=MapCompose(remove_tags, handle_jobaddr), ) company_name = scrapy.Field( input_processor=MapCompose(handle_strip), ) company_url = scrapy.Field() crawl_time = scrapy.Field() crawl_update_time = scrapy.Field() def get_insert_sql(self): insert_sql = """ insert into lagou_job(title, url, salary, job_city, work_years, degree_need, job_type, publish_time, job_advantage, job_desc, job_addr, company_url, company_name, job_id) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE job_desc=VALUES(job_desc) """ job_id = extract_num(self["url"]) params = (self["title"], self["url"], self["salary"], self["job_city"], self["work_years"], self["degree_need"], self["job_type"], self["publish_time"], self["job_advantage"], self["job_desc"], self["job_addr"], self["company_url"], self["company_name"], job_id) return insert_sql, params
在这个类之中必须继承scrapy.Item
但是他的字段也是只有一种就是scrapy.Field()
在爬虫的文件中实例化之后像字典一样进行传至
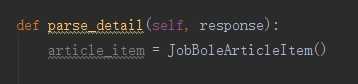
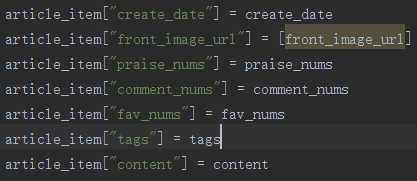
是不是和django似曾相识?
注意:在写完之后要加一句:
yield article_item
这时scrapy就会把数据传递到piplines.py中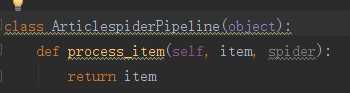
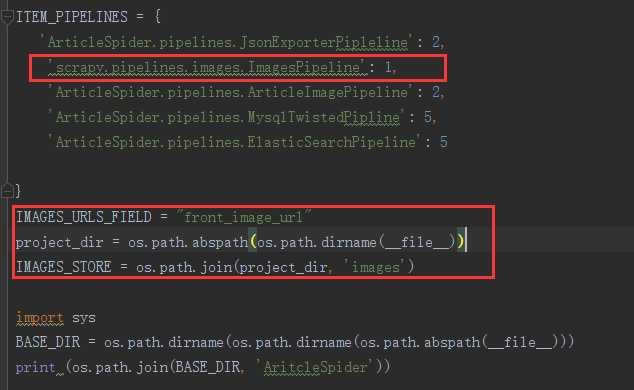
如何让scrapy自动下载图片?加上一句话!
‘scrapy.pipelines.images.ImagesPipeline‘: 1, #后面的数字越小,表明越先进入管道
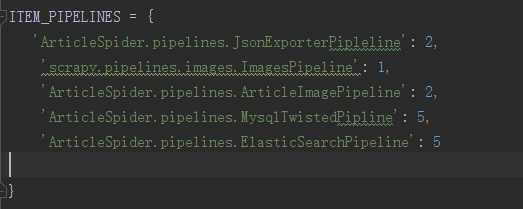
还需要告知哪个字段是url图片的字段,在settings中配置
IMAGES_URLS_FIELD = "front_image_url"
这个是固定写法,但是我的下载的图片我保存在哪??
在settings中再次配置
project_dir = os.path.abspath(os.path.dirname(__file__)) IMAGES_STORE = os.path.join(project_dir, ‘images‘)
完整版看截图:
那如何将下载到本地文件的路径保存起来?
自定义piplines
from scrapy.pipelines.images import ImagesPipeline class ArticleImagePipeline(ImagesPipeline): def item_completed(self, results, item, info): if "front_image_url" in item: for ok, value in results: image_file_path = value["path"] item["front_image_path"] = image_file_path return item
那如何过滤掉一些小图片呢?
在settings中配置
IMAGES_MIN_HEIGHT = 100
IMAGES_MIN_WIDTH = 100
如果想保存到数据库中就需要在piplines中定义一个类,用来处理item的方法是必须使用
process_item(self, item, spider)
return item
必须要return回去item,因为以后的piplines可能会需要使用item
以上是关于爬虫源码1的主要内容,如果未能解决你的问题,请参考以下文章