KNN
Posted geoffreyone
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KNN相关的知识,希望对你有一定的参考价值。
一、 k-近邻法
选择未知样本一定范围内确定个数的K个样本,该K个样本大多数属于某一类型,则未知样本判定为该类型。
粗暴性RNN实现:
1 #!/usr/bin/env python 2 # encoding: utf-8 3 4 """ 5 @version: python37 6 @author: Geoffrey 7 @file: KNN.py 8 @time: 18-11-12 下午2:53 9 """ 10 11 ‘‘‘ 12 需求:使用KNN预测分类 13 样本集: 14 1, 1, a 15 1, 2, a 16 1.5,1.5,a 17 3, 4, b 18 4, 4, b 19 预测数据: 20 2, 2 21 ‘‘‘ 22 23 import numpy as np 24 import pandas as pd 25 import matplotlib.pyplot as plt 26 # import matplotlib.font_manager as fm 27 28 # 计算距离函数 29 def Minkowski_distication(data, point, m=2): 30 num, dim = data.shape 31 result = 0 32 if len(point) == dim: 33 for i in range(dim): 34 result += ((abs(data[i] - point[i])) ** m) 35 return result ** (1 / m) 36 37 # KNN分类 38 def KNN_classify(data, distance, k): 39 index = np.argsort(distance, axis=0) 40 data[‘distance‘] = index 41 data = data.sort_values(‘distance‘).head(k)[2] 42 43 return data.value_counts().head(1).index 44 45 if __name__ == ‘__main__‘: 46 sample = [ 47 [1, 1, ‘a‘], 48 [1, 2, ‘a‘], 49 [1.5, 1.5, ‘a‘], 50 [3, 4, ‘b‘], 51 [4, 4, ‘b‘], 52 ] 53 df_sample = pd.DataFrame(sample) 54 point = (2, 2) 55 56 distance = Minkowski_distication(df_sample.drop(2, axis=1), point=point) 57 result = KNN_classify(df_sample, distance, k=4) 58 59 # 绘图 60 fig = plt.figure() 61 plt.scatter(df_sample[0], df_sample[1]) 62 plt.scatter(*point, color=‘red‘) 63 plt.show()
适用情况:
1) 样本容量比较大,切各个分类数量差异不大;
2) 类域重叠交叉较多;
缺点:
1)需要存储全部的训练样本,耗内存
2) 计算量较大
3)样本数量少或者各个种类数量不均衡,对稀有种类的预测性能差
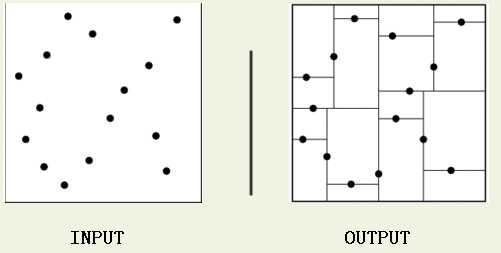
二、 KD树
kd树(K-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
以上是关于KNN的主要内容,如果未能解决你的问题,请参考以下文章