它们其实都是“图”
Posted timhy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了它们其实都是“图”相关的知识,希望对你有一定的参考价值。
2018-11-05 19:37:25
图是表示一些事物或者状态的关系表达方法。由于许多问题都可以归约为图的问题,人们提出了许多和图相关的算法。因此,在程序设计竞赛中有许多需要直接或者间接对图进行处理或者间接用图解决的问题。
一、图是什么
图由顶点(vertex)和边(edge)组成。一般来说,可以把图分成两类。边没有指向性的称为无向图,边具有指向性的称为有向图。
- 无向图
两个顶点之间如果有边连接,那么就视为两点相邻。相邻顶点的序列称为路径。起点和终点重合的路径称为圈。任意两点之间都有路径连接的图称为连通图。顶点连接的边数叫做这个顶点的度。
没有圈的连通图称为树。没有圈的非连通图称为森林。一棵树的边数恰好是顶点数 - 1。反之,边数等于顶点数 - 1的连通图就是一棵树。
如果我们在一棵树上选择一个顶点作为根(root),就可以把根提到最上面,而离根越远的顶点越往下安排其位置,我们可以认为有根树是给树的边加上了方向。
- 有向图
对于有向图,每个节点的度可以分为入度和出度。
没有圈的有向图叫做DAG(Directed Acyclic Graph)。对于DAG我们可以对其进行拓扑排序。
二、图的搜索
- 二分图判定
问题描述:
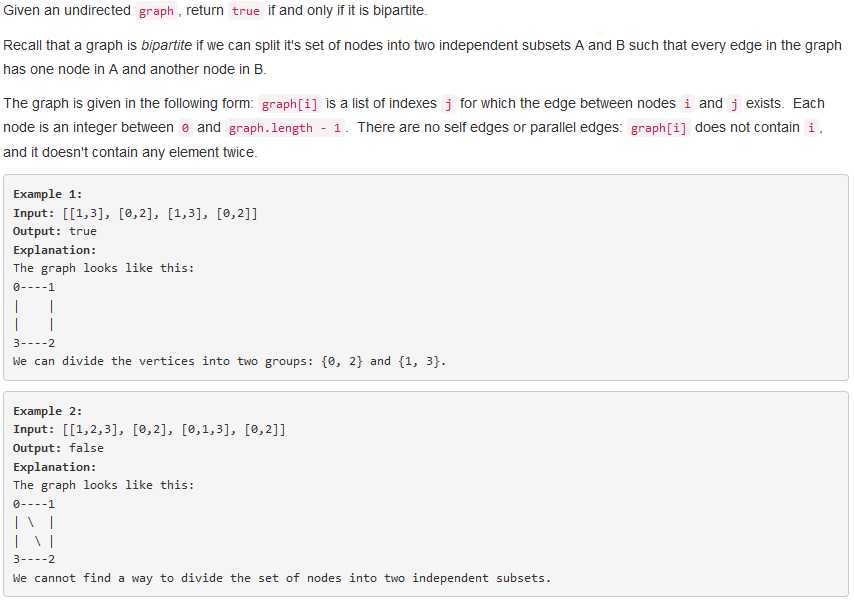
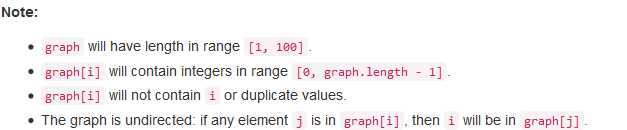
问题求解:
public boolean isBipartite(int[][] graph) {
int[] colors = new int[graph.length];
for (int i = 0; i < graph.length; i++) {
if (colors[i] == 0 && !helper(graph, colors, 1, i)) {
return false;
}
}
return true;
}
private boolean helper(int[][] graph, int[] colors, int color, int i) {
if (colors[i] != 0) return colors[i] == color;
colors[i] = color;
for (int j : graph[i]) {
if (!helper(graph, colors, -color, j)) return false;
}
return true;
}
三、最短路问题
最短路问题是图论中最基础的问题,在程序设计竞赛试题中也经常出现。最短路是给定两个顶点,在以这两个点为起点和终点的路径中,寻找边权值和最小的路径。如果把权值当作距离,考虑最短距离的就很容易理解了。智力游戏中求解最少步数也可以看成是求解最短路径的问题。
1、Bellman-Ford 算法
核心思路:Bellman-Ford算法是一个非常经典的求解最短路径的算法。这个算法的核心思路就是对路径中的每一条边进行松弛操作,很显然的是,每次松弛操作都会产生一个最短路径节点,所以,整个算法的最差的循环次数是n - 1。
算法分析:整个时间复杂度为O(VE)。在稠密图中E是V ^ 2量级的,在稀疏图中E是V量级的。另外值得一提的是BF算法是适用于含有负权边的图的,并且BF算法还可以用来判断一个有向图/无向图中是否包含负圈。
hihoCoder #1081
问题描述:
万圣节的早上,小Hi和小Ho在经历了一个小时的争论后,终于决定了如何度过这样有意义的一天——他们决定去闯鬼屋!
在鬼屋门口排上了若干小时的队伍之后,刚刚进入鬼屋的小Hi和小Ho都颇饥饿,于是他们决定利用进门前领到的地图,找到一条通往终点的最短路径。
鬼屋中一共有N个地点,分别编号为1..N,这N个地点之间互相有一些道路连通,两个地点之间可能有多条道路连通,但是并不存在一条两端都是同一个地点的道路。那么小Hi和小Ho至少要走多少路程才能够走出鬼屋去吃东西呢?
输入:
每个测试点(输入文件)有且仅有一组测试数据。
在一组测试数据中:
第1行为4个整数N、M、S、T,分别表示鬼屋中地点的个数和道路的条数,入口(也是一个地点)的编号,出口(同样也是一个地点)的编号。
接下来的M行,每行描述一条道路:其中的第i行为三个整数u_i, v_i, length_i,表明在编号为u_i的地点和编号为v_i的地点之间有一条长度为length_i的道路。
对于100%的数据,满足N<=10^3,M<=10^4, 1 <= length_i <= 10^3, 1 <= S, T <= N, 且S不等于T。
对于100%的数据,满足小Hi和小Ho总是有办法从入口通过地图上标注出来的道路到达出口。
问题求解:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Scanner;
public class BellmanFord {
int n;
List<Edge> edges;
int[] d;
int s;
int t;
public int bellmanFord() {
for (int i = 0; i < n; i++) {
boolean flag = false;
for (Edge e : edges) {
int u = e.u;
int v= e.v;
int w = e.w;
if (d[u] != Integer.MAX_VALUE && d[v] > d[u] + w) {
d[v] = d[u] + w;
flag = true;
}
}
if (i == n - 1 && flag) System.out.println("There is a cycle.");
}
return d[t];
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
BellmanFord bf = new BellmanFord();
bf.n = sc.nextInt();
int m = sc.nextInt();
bf.s = sc.nextInt();
bf.t = sc.nextInt();
bf.d = new int[bf.n + 1];
bf.edges = new ArrayList<>();
Arrays.fill(bf.d, Integer.MAX_VALUE);
bf.d[bf.s] = 0;
for (int i = 0; i < m; i++) {
int u = sc.nextInt();
int v = sc.nextInt();
int w = sc.nextInt();
Edge e1 = new Edge(u, v, w);
Edge e2 = new Edge(v, u, w);
bf.edges.add(e1);
bf.edges.add(e2);
}
System.out.println(bf.bellmanFord());
}
}
class Edge {
public int u;
public int v;
public int w;
public Edge(int u, int v, int w) {
this.u = u;
this.v = v;
this.w = w;
}
}
2、Dijkstra 算法
核心思路:谈最短路算法肯定是会提到Dijkstra算法的,这个算法相比于BF算法要高效很多,但是也是有其局限的,就是在图中含有负边的情况下,Dijkstra算法就不再适用了。
那么为什么Dijkstra会更加高效呢?
让我们考虑一下没有负边的情况,在BF算法中,如果d[i]还不是最短距离的话,那么即使进行d[j] = d[i] + w(i, j)的更新,d[j]依然是不会变成最短距离的。而且,即使d[i]没有发生变化,每次循环也会检查一遍所有从i出发的边,这边显然是很浪费时间的。因此,可以对算法进行如下的修改:
(1) 找到最短距离已经确定的点,从它出发更新相邻顶点的最短距离。
(2) 此后不需要再关心1中最短距离已经确定的点。
在1,2中提到的最短路径已经确定的顶点怎么得到是问题的关键。
在最开始的时候,只有起点的最短距离是确定的。而在尚未使用过的顶点中,d[i]最小的顶点就是最短距离已经确定的顶点。理由是由于不存在负边,所以不存在更大的d[j] + w(j, i) < d[i]的情况。
这个算法就是Dijkstra算法。
算法分析:
邻接矩阵 - > O(V ^ 2)
邻接表 + 优先队列 - > O(ElogV)
所以如果是稠密图的话直接使用邻接矩阵求解即可,如果是稀疏图的话,使用优化的算法更加高效。
hihoCoder #1081
问题描述:
万圣节的早上,小Hi和小Ho在经历了一个小时的争论后,终于决定了如何度过这样有意义的一天——他们决定去闯鬼屋!
在鬼屋门口排上了若干小时的队伍之后,刚刚进入鬼屋的小Hi和小Ho都颇饥饿,于是他们决定利用进门前领到的地图,找到一条通往终点的最短路径。
鬼屋中一共有N个地点,分别编号为1..N,这N个地点之间互相有一些道路连通,两个地点之间可能有多条道路连通,但是并不存在一条两端都是同一个地点的道路。那么小Hi和小Ho至少要走多少路程才能够走出鬼屋去吃东西呢?
输入:
每个测试点(输入文件)有且仅有一组测试数据。
在一组测试数据中:
第1行为4个整数N、M、S、T,分别表示鬼屋中地点的个数和道路的条数,入口(也是一个地点)的编号,出口(同样也是一个地点)的编号。
接下来的M行,每行描述一条道路:其中的第i行为三个整数u_i, v_i, length_i,表明在编号为u_i的地点和编号为v_i的地点之间有一条长度为length_i的道路。
对于100%的数据,满足N<=10^3,M<=10^4, 1 <= length_i <= 10^3, 1 <= S, T <= N, 且S不等于T。
对于100%的数据,满足小Hi和小Ho总是有办法从入口通过地图上标注出来的道路到达出口。
问题求解:
import java.util.*;
public class Dijkstra {
int n;
List<Edge> graph[];
int[] d;
int s;
int t;
PriorityQueue<int[]> pq;
public int dijkstra() {
while (!pq.isEmpty()) {
int[] cur = pq.poll();
int dis = cur[0];
int u = cur[1];
if (d[u] < dis) continue;
d[u] = dis;
for (Edge e : graph[u]) {
int v = e.v;
int w = e.w;
if (d[v] > d[u] + w) {
d[v] = d[u] + w;
pq.add(new int[]{d[v], v});
}
}
}
return d[t];
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
Dijkstra dij = new Dijkstra();
dij.n = sc.nextInt();
int m = sc.nextInt();
dij.s = sc.nextInt();
dij.t = sc.nextInt();
dij.pq = new PriorityQueue<>(new Comparator<int[]>() {
@Override
public int compare(int[] o1, int[] o2) {
return o1[0] - o2[0];
}
});
dij.pq.add(new int[]{0, dij.s});
dij.d = new int[dij.n + 1];
Arrays.fill(dij.d, Integer.MAX_VALUE);
dij.d[dij.s] = 0;
dij.graph = new ArrayList[dij.n + 1];
for (int i = 0; i < dij.n + 1; i++) dij.graph[i] = new ArrayList<>();
for (int i = 0; i < m; i++) {
int u = sc.nextInt();
int v = sc.nextInt();
int w = sc.nextInt();
dij.graph[u].add(new Edge(v, w));
dij.graph[v].add(new Edge(u, w));
}
System.out.println(dij.dijkstra());
}
}
class Edge {
int v;
int w;
Edge(int v, int w) {
this.v = v;
this.w = w;
}
}
3、Floyed-Warshall 算法
核心思路:Floyed算法也是最短路径算法里很经典的算法,经典的理由是算法好写,而且在求多源最短路的时候非常高效。
本质上来说Floyed算法使用的是动态规划算法,但是可以通过很简单的思路来理解,就是从A到B的最短路径是要么直达,要么就是需要经过跳板的,那么就对所有可能的跳板进行检索一遍,最终的结果就是A到B的最短距离。
另外,值得一提的是Floyed算法也是可以处理边是负数的情况(Dijkstra已经哭了ORZ),而且如果需要判断图中是否存在负圈,只需要检查一下是否存在d[i][i]是负数就可以了。
算法分析:Floyed算法是典型的三层循环结构,因此整个算法非常好实现。时间复杂度显然是O(n ^ 3)。
hihocoder #1089
问题描述:
万圣节的中午,小Hi和小Ho在吃过中饭之后,来到了一个新的鬼屋!
鬼屋中一共有N个地点,分别编号为1..N,这N个地点之间互相有一些道路连通,两个地点之间可能有多条道路连通,但是并不存在一条两端都是同一个地点的道路。
由于没有肚子的压迫,小Hi和小Ho决定好好的逛一逛这个鬼屋,逛着逛着,小Hi产生了这样的问题:鬼屋中任意两个地点之间的最短路径是多少呢?
输入:
每个测试点(输入文件)有且仅有一组测试数据。
在一组测试数据中:
第1行为2个整数N、M,分别表示鬼屋中地点的个数和道路的条数。
接下来的M行,每行描述一条道路:其中的第i行为三个整数u_i, v_i, length_i,表明在编号为u_i的地点和编号为v_i的地点之间有一条长度为length_i的道路。
对于100%的数据,满足N<=10^2,M<=10^3, 1 <= length_i <= 10^3。
对于100%的数据,满足迷宫中任意两个地点都可以互相到达。
问题求解:
这里有个小坑就是给的图中的边是有重复的,所以在生成邻接矩阵的时候需要进行判断。
import java.util.Scanner;
public class Floyed {
int n;
int[][] graph;
public void floyed() {
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (graph[i][k] != Integer.MAX_VALUE && graph[k][j] != Integer.MAX_VALUE)
graph[i][j] = Math.min(graph[i][j], graph[i][k] + graph[k][j]);
}
}
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
Floyed f = new Floyed();
f.n = sc.nextInt();
f.graph = new int[f.n][f.n];
for (int i = 0; i < f.n; i++) {
for (int j = 0; j < f.n; j++) {
if (i == j) f.graph[i][j] = 0;
else f.graph[i][j] = Integer.MAX_VALUE;
}
}
int m = sc.nextInt();
for (int i = 0; i < m; i++) {
int u = sc.nextInt() - 1;
int v = sc.nextInt() - 1;
int w = sc.nextInt();
if (f.graph[u][v] < w) continue;
f.graph[u][v] = w;
f.graph[v][u] = w;
}
f.floyed();
for (int i = 0; i < f.n; i++) {
for (int j = 0; j < f.n; j++) {
System.out.print(f.graph[i][j] + " ");
}
System.out.println();
}
}
}
四、最小生成树
给定一个无向图,如果它的某个子图中任意两个顶点都连通并且是一棵树,那么这棵树就叫做生成树(Spanning Tree)。如果边上有权值,那么使权值最低的生成树称作最小生成树(MST,Minimum Spanning Tree)。
例如我们有这样一个图:把顶点看作村庄,边看作计划要修建的道路。为了在所有的村庄间通行,恰好修建村庄数目-1条道路就对应了一棵生成树。修建道路需要投入建设费用,那么求解使得道路建设费用最小的生成树就是最小生成树问题。
常见的最小生成树的算法有Kruskal算法和Prim算法。很显然,生成树是否存在和图是否连通是等价的,因此我们假定图是连通的。
1、Prim算法
核心思路:首先,我们先介绍Prim算法。Prim算法和Dijkstra算法非常类似,都是从一个点出发,不断添加边的算法。
首先,我们假设一棵只包含一个顶点的树T。然后贪心的选取T和其他顶点之间相连的最小权值的边,并把它加入到T中。不断进行这个过程,就可以得到一棵生成树。
证明:
V : 顶点集合
X :已经求得MST的点集,并且存在V的MST使T是其子图
下面我们证明存在一棵最小生成树使得T是其子图,并且包含X到V/X的最小边e。
假设最小生成树中不包含e,那么将e加入就会生成一个环,这个时候必然包含一条边f从X到V/X,将f去掉将e加入显然能够得到更小的权重。因此得证。
算法分析:
算法的时间复杂度和Dijkstra一致。
邻接矩阵:O(V ^ 2)
邻接表 + 优先队列:O(ElogV)
hihocoder #1109
问题描述:
回到两个星期之前,在成功的使用Kruscal算法解决了问题之后,小Ho产生了一个疑问,究竟这样的算法在稀疏图上比Prim优化之处在哪里呢?
输入:
每个测试点(输入文件)有且仅有一组测试数据。
在一组测试数据中:
第1行为2个整数N、M,表示小Hi拥有的城市数量和小Hi筛选出路线的条数。
接下来的M行,每行描述一条路线,其中第i行为3个整数N1_i, N2_i, V_i,分别表示这条路线的两个端点和在这条路线上建造道路的费用。
对于100%的数据,满足N<=10^5, M<=10^6,于任意i满足1<=N1_i, N2_i<=N, N1_i≠N2_i, 1<=V_i<=10^3.
对于100%的数据,满足一定存在一种方案,使得任意两座城市都可以互相到达。
问题求解:
import java.util.*;
public class Prim {
int n;
List<int[]>[] graph;
boolean[] used;
PriorityQueue<int[]> pq;
public int prim() {
int res = 0;
while (!pq.isEmpty()) {
int[] cur = pq.poll();
int w = cur[0];
int u = cur[1];
if (used[u]) continue;
used[u] = true;
res += w;
for (int[] e : graph[u]) {
pq.add(new int[]{e[1], e[0]});
}
}
return res;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
Prim p = new Prim();
p.n = sc.nextInt();
p.graph = new ArrayList[p.n];
for (int i = 0; i < p.n; i++) p.graph[i] = new ArrayList<int[]>();
p.pq = new PriorityQueue<>(new Comparator<int[]>() {
@Override
public int compare(int[] o1, int[] o2) {
return o1[0] - o2[0];
}
});
p.pq.add(new int[]{0, 0});
p.used = new boolean[p.n];
int m = sc.nextInt();
for (int i = 0; i < m; i++) {
int u = sc.nextInt() - 1;
int v = sc.nextInt() - 1;
int w = sc.nextInt();
p.graph[u].add(new int[]{v, w});
p.graph[v].add(new int[]{u, w});
}
System.out.println(p.prim());
}
}
2、Kruskal算法
核心思路:Kruskal算法按照边的权重顺序从小到大查看一遍,如果不产生圈,就把当前这条边加入到树中。
算法分析:判圈可以使用UFS高效的实现,众所周知UFS可以O(1)完成操作,所以该算法的时间主要消耗在了排序上,总的时间复杂度是O(ElogE)。
hihocoder #1098
问题描述:
随着小Hi拥有城市数目的增加,在之间所使用的Prim算法已经无法继续使用了——但是幸运的是,经过计算机的分析,小Hi已经筛选出了一些比较适合建造道路的路线,这个数量并没有特别的大。
所以问题变成了——小Hi现在手上拥有N座城市,且已知其中一些城市间建造道路的费用,小Hi希望知道,最少花费多少就可以使得任意两座城市都可以通过所建造的道路互相到达(假设有A、B、C三座城市,只需要在AB之间和BC之间建造道路,那么AC之间也是可以通过这两条道路连通的)。
输入:
每个测试点(输入文件)有且仅有一组测试数据。
在一组测试数据中:
第1行为2个整数N、M,表示小Hi拥有的城市数量和小Hi筛选出路线的条数。
接下来的M行,每行描述一条路线,其中第i行为3个整数N1_i, N2_i, V_i,分别表示这条路线的两个端点和在这条路线上建造道路的费用。
对于100%的数据,满足N<=10^5, M<=10^6,于任意i满足1<=N1_i, N2_i<=N, N1_i≠N2_i, 1<=V_i<=10^3.
对于100%的数据,满足一定存在一种方案,使得任意两座城市都可以互相到达。
问题求解:
import java.util.Arrays;
import java.util.Comparator;
import java.util.Scanner;
public class Kruskal {
UFS ufs;
Edge[] edges;
public int kruskal() {
int res = 0;
Arrays.sort(edges, new Comparator<Edge>() {
@Override
public int compare(Edge o1, Edge o2) {
return o1.w - o2.w;
}
});
for (Edge e : edges) {
if (ufs.find(e.u) == ufs.find(e.v)) continue;
ufs.union(e.u, e.v);
res += e.w;
}
return res;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
Kruskal k = new Kruskal();
int n = sc.nextInt();
int m = sc.nextInt();
k.ufs = new UFS(n);
k.edges = new Edge[m];
for (int i = 0; i < m; i++) {
int u = sc.nextInt();
int v = sc.nextInt();
int w = sc.nextInt();
Edge e = new Edge(u, v, w);
k.edges[i] = e;
}
System.out.println(k.kruskal());
}
}
class Edge {
int u;
int v;
int w;
public Edge(int u, int v, int w) {
this.u = u;
this.v = v;
this.w = w;
}
}
class UFS {
int[] parent;
int[] rank;
UFS(int n) {
this.parent = new int[n + 1];
this.rank = new int[n + 1];
for (int i = 0; i <= n; i++) {
parent[i] = i;
rank[i] = 1;
}
}
public int find(int i) {
if (parent[i] != i) parent[i] = find(parent[i]);
return parent[i];
}
public boolean union(int i, int j) {
int pari = find(i);
int parj = find(j);
if (pari == parj) return false;
if (rank[pari] > rank[parj]) parent[parj] = pari;
else if (rank[parj] > rank[pari]) parent[pari] = parj;
else {
rank[pari]++;
parent[parj] = pari;
}
return true;
}
}
以上是关于它们其实都是“图”的主要内容,如果未能解决你的问题,请参考以下文章