Mahout canopy聚类
Posted ldxsuanfa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mahout canopy聚类相关的知识,希望对你有一定的参考价值。
Canopy 聚类
一、Canopy算法流程
Canopy 算法,流程简单,easy实现,一下是算法
(1)设样本集合为S,确定两个阈值t1和t2。且t1>t2。
(2)任取一个样本点p,作为一个Canopy,记为C,从S中移除p。
(3)计算S中全部点到p的距离dist
(4)若dist<t1。则将对应点归到C,作为弱关联。
(5)若dist<t2。则将对应点移出S,作为强关联。
(6)反复(2)~(5),直至S为空。
上面的过程能够看出。dist<t2的点属于有且仅有一个簇,t2<dist<t1 的点可能属于多个簇。可见Canopy是一种软聚类。
数据集合划分完后:
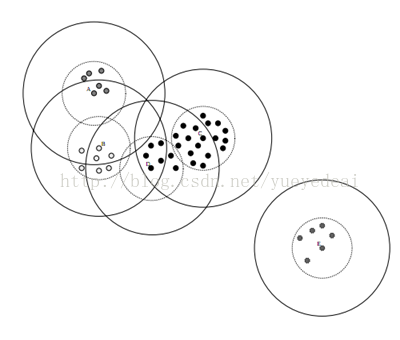
Canopy有消除孤立点的作用,而K-means在这方面却无能为力。建立canopies之后,能够删除那些包括数据点数目较少的canopy。往往这些canopy是包括孤立点的。依据canopy内点的数目,来决定聚类中心数目k,这样效果比較好。
当T1过大时,会使很多点属于多个Canopy,可能会造成各个簇的中心点间距离较近,各簇间差别不明显;当T2过大时。增加强标记数据点的数量,会降低簇个个数;T2过小,会增加簇的个数。同一时候增加计算时间。
二、MapReduce实现
在运行Canopy之前须要用将文本合并,然后用Mahout文本向量化模块计算TFIDF,作为文本向量。向量化之后再用Canopy算法聚类。
(一)簇定义
簇Cluster是一个实体,保存该簇的关键信息,canopy 就是一个cluster。
privateint id; 簇编号
核心參数:计算完数据后终于的簇属性
private long numPoints; 簇中点的个数
private Vector center; 中心向量 center=
private Vector radius; 半径向量 radius =
调整參数:簇中增加一个点后调整的參数
private double s0; s0= 权重和。对于canopy,w=1 ,全部s0=numPoints
private Vector s1; s1= x 为point,w为权重。对canopyw =1
private Vector s2 ; s2= x 为point。w为权重。对canopyw =1
(二)发现中心点
该Job 通过多个Map 寻找局部Canopy ,用1个reduce将map计算的canopy合并,终于输出全局的中心。
输入数据:SequenceFile 格式。key 文件路径。value TFIDF向量。
Map: key 文件路径 , value TFIDF 向量
Collection<Canopy> canopies = new ArrayList<Canopy>()
Map(WritableComparable<?> key, VectorWritable point){
CanopyClusterer 将Point 增加到canopies 集合中。增加集合的过程中计算T1,T2.增加到对应的Canopy中。
}
Close(){
遍历canopies 集合,计算每个Canopy的中心点。
For(canopy :canopies){
计算每个Canopy的中心点。
输出 key :Text(“centroid”)value: Canopy中心点向量。
}
}
Reduce:key Text(“centroid”) value VectorWritable
用1个reduce 将全部map 计算的canopy 中心合并。
Reduce中运行的代码和map的一样。
终于输出canopy 。
For(canopy c :canopys ){
输出:key c.getIdentifier() 。Value c
}
(三)划分数据
通过上一步找到中心点后,划分数据的过程就比較easy了。输入数据为向量化后的TFIDF向量。该过程仅仅需用Map 即可。
输入格式:key 文档路径 value TFIDF向量
Map:
Collection<Canopy>canopies = new ArrayList<Canopy>()
Map(WritableComparable<?
> key, VectorWritable point){
计算point 和全部中心点的距离。将其划分到距离近期的canopy中
CanopyClusterer.emitPointToClosestCanopy(point,canopyes)
输出 key: canopyid 。value:point
}
setup(){
读Canopy ,到 canopies
}
三、API说明
API
|
CanopyDriver.main(args); |
|
|
--input (-i) |
输入路径 |
|
--output(-o) |
输出路径 |
|
--distanceMeasure(-dm) |
距离度量类的权限命名。如:”org.apache.mahout.common.distance.CosineDistanceMeasure” |
|
--t1 (-t1) |
t1值 (t1>t2) |
|
--t2 (-t2) |
t2值 |
|
--t3 (-t3) |
t3值,默认t3=t1 |
|
--t4(-t4) |
t4值。默认t4=t2 |
|
--overwrite (-ow) |
是否覆盖上次操作的结果 |
|
--clustering (-cl) |
是否运行聚类操作。即划分数据 |
|
--method (-method) |
默认,mapreduce。 还可选sequential,运行单机模式 |
演示样例
|
String [] args ={“--input”,“vector/tfidf-vectors”, “--output”, “cluster/canopy”, “--method”, “mapreduce”, “--distanceMeasure”, “org.apache.mahout.common.distance .CosineDistanceMeasure”, “--t1”, “0.45”, “--t2”, 0.38”, “--overwrite”, “--clustering”} CanopyDriver.main(args); |
输出
|
结果文件 |
Key类型 |
Value类型 |
说明 |
|
clusters-* |
类id (org.apache.hadoop.io.Text) |
类中心 (org.apache.mahout. clustering.kmeans.Cluster) |
每条记录以类id和类中心表示一个类别 |
|
clusteredPoints |
类id (org.apache.hadoop.io.IntWritable) |
文档向量 (org.apache. mahout.clustering.WeightedVectorWritable) |
每条记录中,文档向量代表文档。类id代表该文档所属类别 |
注:clusters-*中*代表数字。第i次迭代产生的类信息即为clusters-i
四、參考文献
以上是关于Mahout canopy聚类的主要内容,如果未能解决你的问题,请参考以下文章