Kafka学习之路 Kafka的安装
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka学习之路 Kafka的安装相关的知识,希望对你有一定的参考价值。
zookeeper1:192.168.1.11
zookeeper2:192.168.1.12
zookeeper3:192.168.1.13
kafka1:192.168.1.14
kafka2:192.168.1.15
kafka3:192.168.1.16
kafka3:192.168.1.17
kafka-manager:192.168.1.18一、下载
下载地址:
http://kafka.apache.org/downloads.html
http://mirrors.hust.edu.cn/apache/
http://zookeeper.apache.org/releases.html
已经安装好java-1.8
[[email protected] ~]# yum install java-1.8.0二、Zookeeper安装
此处使用版本zookeeper-3.4.10.tar.gz
2.1 上传解压缩
# 下载 ZooKeeper
[[email protected] ~]# wget https://mirrors.aliyun.com/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
# 解压文件
[[email protected] ~]# tar -zxf zookeeper-3.4.10.tar.gz -C /opt/
[[email protected] ~]# cd /opt/
[[email protected] opt]# ln -s zookeeper-3.4.10 zookeeper
[[email protected] opt]# cd zookeeper
[[email protected] zookeeper]# cp ./conf/zoo_sample.cfg ./conf/zoo.cfg2.2 修改配置文件
zookeeper1,zookeeper2,zookeeper3都是同样的配置
[[email protected] zookeeper]# vim ./conf/zoo.cfg
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/opt/push/kafka-test/zookeeper/data
dataLogDir=/opt/push/kafka-test/zookeeper/logs
clientPort=2181
server.1=192.168.1.11:2888:3888
server.2=192.168.1.12:2888:3888
server.3=192.168.1.13:2888:3888
[[email protected] zookeeper]# mkdir data logs
[[email protected] zookeeper]# echo ‘1‘ > /opt/zookeeper/data/myid
# 其它两台此处需要修改
[[email protected] zookeeper]# echo ‘2‘ > /opt/zookeeper/data/myid
[[email protected] zookeeper]# echo ‘3‘ > /opt/zookeeper/data/myid三、Kafka安装
此处使用版本为kafka_2.11-1.1.0.tgz
3.1 上传解压缩
# 下载 Kafka
[[email protected] ~]# wget https://archive.apache.org/dist/kafka/1.1.0/kafka_2.11-1.1.0.tgz
# 解压tar文件
[[email protected] ~]# tar -zxf kafka_2.11-1.1.0.tgz.gz -C /opt/
[[email protected] ~]# cd /opt/
[email protected] opt]# ln -s kafka_2.11-1.1.0 kafka
[email protected] opt]# cd kafka3.2 修改配置文件
进入kafka的安装配置目录
[[email protected] kafka]# cp config/server.properties config/server.properties.bak # 备份kafka默认配置文件主要关注:server.properties 这个文件即可,我们可以发现在目录下:
有很多文件,这里可以发现有Zookeeper文件,我们可以根据Kafka内带的zk集群来启动,但是建议使用独立的zk集群
server.properties(broker.id和host.name每个节点都不相同)
//当前机器在集群中的唯一标识,和zookeeper的myid性质一样
broker.id=0
//Socket服务器侦听的地址,当前kafka对外提供服务的端口默认是9092
listeners = PLAINTEXT://your.host.name:9092
//代理将向生产者和消费者做广告的主机名和端口
advertised.listeners=PLAINTEXT://your.host.name:9092
//这个是borker进行网络处理的线程数
num.network.threads=3
//这个是borker进行I/O处理的线程数
num.io.threads=8
//发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.send.buffer.bytes=102400
//kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.receive.buffer.bytes=102400
//这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
socket.request.max.bytes=104857600
//消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,
//如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
log.dirs=/home/hadoop/log/kafka-logs
//默认的分区数,一个topic默认1个分区数
num.partitions=1
//每个数据目录用来日志恢复的线程数目
num.recovery.threads.per.data.dir=1
//默认消息的最大持久化时间,168小时,7天
log.retention.hours=168
//这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.segment.bytes=1073741824
//每隔300000毫秒去检查上面配置的log失效时间
log.retention.check.interval.ms=300000
//设置zookeeper的连接端口
zookeeper.connect=localhost:2181
//设置zookeeper的连接超时时间
zookeeper.connection.timeout.ms=6000kafka1:
[[email protected] kafka]# vim config/server.properties
broker.id=1 # 当前机器在集群中的唯一标识
listeners=PLAINTEXT://192.168.1.14:9092 # 监听端口
advertised.listeners=PLAINTEXT://192.168.1.14:9092 # 提供给生产者,消费者的端口号。可以不设置则使用listeners的值
zookeeper.connect=192.168.1.11:2181,192.168.1.12:2181,192.168.1.13:2181/kafka # 连接zookeeperkafka2:
[[email protected] kafka]# vim config/server.properties
broker.id=2 # 当前机器在集群中的唯一标识
listeners=PLAINTEXT://192.168.1.15:9092 # 监听端口
advertised.listeners=PLAINTEXT://192.168.1.15:9092 # 提供给生产者,消费者的端口号。可以不设置则使用listeners的值
zookeeper.connect=192.168.1.11:2181,192.168.1.12:2181,192.168.1.13:2181/kafka # 连接zookeeperkafka3:
[[email protected] kafka]# vim config/server.properties
broker.id=3 # 当前机器在集群中的唯一标识
listeners=PLAINTEXT://192.168.1.16:9092 # 监听端口
advertised.listeners=PLAINTEXT://192.168.1.16:9092 # 提供给生产者,消费者的端口号。可以不设置则使用listeners的值
zookeeper.connect=192.168.1.11:2181,192.168.1.12:2181,192.168.1.13:2181/kafka # 连接zookeeperkafka4:
[[email protected] kafka]# vim config/server.properties
broker.id=4 # 当前机器在集群中的唯一标识
listeners=PLAINTEXT://192.168.1.17:9092 # 监听端口
advertised.listeners=PLAINTEXT://192.168.1.17:9092 # 提供给生产者,消费者的端口号。可以不设置则使用listeners的值
zookeeper.connect=192.168.1.11:2181,192.168.1.12:2181,192.168.1.13:2181/kafka # 连接zookeeper四、启动
3.1 首先启动zookeeper集群
所有zookeeper节点都需要执行
[[email protected] kafka]# ./bin/zkServer.sh start3.2 启动Kafka集群服务
所有kafka节点都需要执行
[[email protected] kafka]# ./bin/kafka-server-start.sh config/server.properties
或者:
[[email protected] kafka]# ./bin/kafka-server-start.sh -daemon config/server.properties # 后台启动3.3 创建的topic
[[email protected] kafka]# bin/kafka-topics.sh --create --zookeeper kafka1:2181 --replication-factor 3 --partitions 3 --topic topic23.4 查看topic副本信息
[[email protected] kafka]# ./bin/kafka-topics.sh --describe --zookeeper kafka1:2181 --topic topic23.5 查看已经创建的topic信息
[[email protected] kafka]# ./bin/kafka-topics.sh --list --zookeeper kafka1:21813.6 生产者发送消息
kafka1显示接收到消息
[[email protected] kafka]# ./bin/kafka-console-producer.sh --broker-list kafka1:9092 --topic23.7 消费者消费消息
在kafka2上消费消息
[[email protected] kafka]# ./bin/kafka-console-consumer.sh --zookeeper kafka1:2181 --from-beginning --topic topic2五、kafka-manager安装
官网:https://github.com/yahoo/kafka-manager
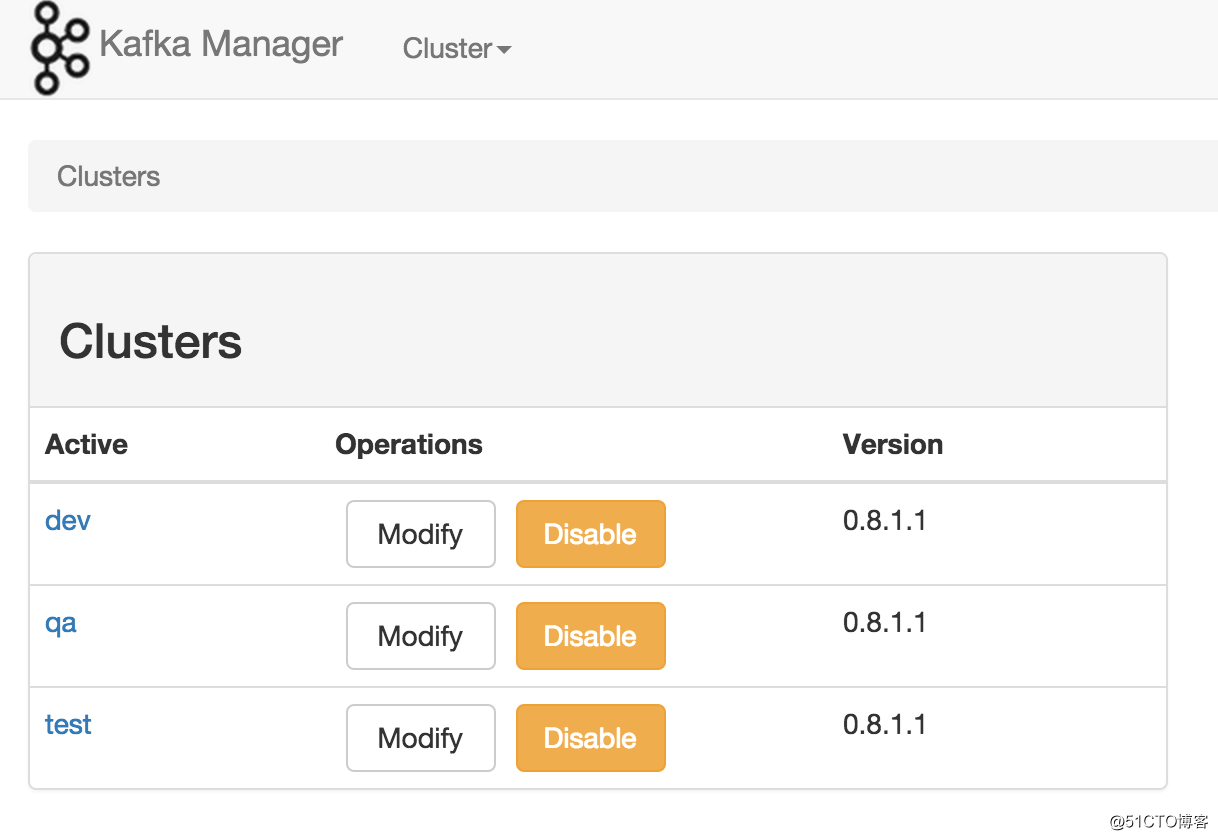
[[email protected] ~]# git clone https://github.com/yahoo/kafka-manager.git
[[email protected] ~]# cd kafka-manager
# 部署
[[email protected] kafka-manager]# ./sbt clean dist
解压缩生成的zip文件
# 启动
[[email protected] kafka-manager]# bin/kafka-manager
[[email protected] kafka-manager]# bin/kafka-manager -Dconfig.file=/path/to/application.conf -Dhttp.port=8080以上是关于Kafka学习之路 Kafka的安装的主要内容,如果未能解决你的问题,请参考以下文章