多线程,多进程和异步IO
Posted silence-cho
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多线程,多进程和异步IO相关的知识,希望对你有一定的参考价值。
1.多线程网络IO请求:


#!/usr/bin/python #coding:utf-8 from concurrent.futures import ThreadPoolExecutor import requests #线程池 # def get_page(url): # response = requests.get(url) # print response.url # return response # # urllist=["https://www.baidu.com/","https://www.jianshu.com/","https://i.cnblogs.com/"] # pool = ThreadPoolExecutor(5) #最多能运行5个线程 # for url in urllist: # pool.submit(get_page,url) #将线程(函数和参数)提交到线程池中 # pool.shutdownn(wait=True) #线程池加回调函数 def get_page(url): response = requests.get(url) print response.url return response def callback(future): print future.result urllist=["https://www.baidu.com/","https://www.jianshu.com/","https://i.cnblogs.com/"] pool = ThreadPoolExecutor(5) #最多能运行5个线程 for url in urllist: future = pool.submit(get_page,url) #将线程(函数和参数)提交到线程池中,返回Future对象 future.add_done_callback(callback) pool.shutdownn(wait=True)
2.多进程网络IO请求:
#!/usr/bin/python #coding:utf-8 from concurrent.futures import ProcessPoolExecutor import requests #进程池加会调函数 # def get_page(url): # response = requests.get(url) # print response.url # return response # # urllist=["https://www.baidu.com/","https://www.jianshu.com/","https://i.cnblogs.com/"] # pool = ProcessPoolExecutor(5) # # for url in urllist: # pool.submit(get_page,url) # pool.shutdown(wait=True) #进程池加回调函数 def get_page(url): response = requests.get(url) print response.url return response def callback(future): print future.result() urllist=["https://www.baidu.com/","https://www.jianshu.com/","https://i.cnblogs.com/"] pool = ProcessPoolExecutor(5) for url in urllist: future = pool.submit(get_page,url) future.add_done_callback(callback) pool.shutdown(wait=True)
上面执行结果如下:

每一个请求发出后等待结果而阻塞,造成了进程或线程资源浪费。异步IO能更好的解决问题,即请求发出后不等待结果,而继续处理其他业务,待网页结果返回后再进行处理。
3. 异步IO请求:
3.1,asyncio模块:asyncio是Python 3.4版本引入的标准库,直接内置了对异步IO的支持
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001432090954004980bd351f2cd4cc18c9e6c06d855c498000
asyncio是一个事件循环(EventLoop),通过装饰器@asyncio.coroutine将一个generator(需要完成的任务)标识为coroutine(协程)类型,然后将多个coroutine放入到EventLoop中执行就能实现异步IO了。
#!/usr/bin/python #coding:utf-8 import asyncio @asyncio.coroutine def get_page(host,url=‘/‘): print host reader,writer = yield from asyncio.open_connection(host,80) request_header = "Get %s HTTP/1.0 Host: %s "%(url,host) writer.write(bytes(request_header,encoding=‘utf-8‘)) yield from writer.drain() text = yield from reader.read() print(host,url,text) writer.close() tasks=[ get_page("www.cnblogs.com","silence-cho"), get_page("www.sina.com.cn"), get_page("www.163.com") ] loop = asyncio.get_event_loop() results = loop.run_until_complete(asyncio.gather(*tasks)) loop.close()
上面执行结果如下:
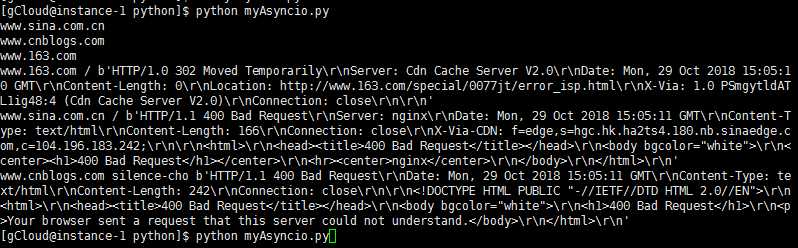
三个请求(协程)是在一个线程中执行的,但能够并发执行。即第一个协程碰到网络IO后切换到第二个协程,第二个协程同样碰到IO时切换到第三个协程,而当三个网络IO中有返回结果时,切回到该协程继续执行,从而实现异步IO和并发执行
3.2,asyncio+aiohttp: asyncio实现了实现了TCP、UDP、SSL等协议,aiohttp则是基于asyncio实现的http框架,aiohttp封装了web,request等方法。
aiohttp文档:https://aiohttp.readthedocs.io/en/stable/client_quickstart.html#make-a-request
3.3,asyncio+requests:
3.4,gevent+requests: gevent为python第三方库,提供了完善的协程支持。gevent通过greenlet实现协程。当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。
#!/usr/bin/python #coding:utf-8 import gevent import requests from gevent import monkey def get_page(method,url,kwargs): print(url,kwargs) response = requests.request(method=method,url=url,**kwargs) print(response.url,response.content) #发送请求 gevent.joinall([ gevent.spawn(get_page,method=‘get‘,url="https://www.baidu.com/",kwargs={}), gevent.spawn(get_page,method=‘get‘,url="https://www.sina.com.cn/",kwargs={}), ]) #发送请求:控制最大协程数量 # from gevent.pool import Pool # pool = Pool(None) # gevent.joinall([ # pool.spawn(get_page,method=‘get‘,url="https://www.baidu.com/",kwargs={}), # pool.spawn(get_page,method=‘get‘,url="https://www.sina.com.cn/",kwargs={}), # ])
3.5,grequests
#!/usr/bin/python #coding:utf-8 #grequests可以简单理解为结合了gevent和requests import grequests request_list = [ grequests.get(‘http://www.baidu.com/‘, timeout=0.001), grequests.get(‘http://sina.com.cn/‘), ]
3.6,Twisted框架
3.7, Tornado框架
使用顺序:gevent > Twisted >Tornado >asyncio
4, 自定义异步IO框架:
上面这些异步IO框架,本质上都是基于非阻塞socket + IO多路复用(select)实现的。
非阻塞socket:
在进行网络请求时,主要是客户端socket和服务端socket之间的通信,客户端socket的请求流程如下代码所示,包括建立连接,发送请求和接收数据。其中connect()和recv()方法都会发生阻塞,直到服务端有响应时才会结束阻塞而向下执行。而当利用setblocking(False)时,socket在connect()和recv()时都会变成非阻塞,但是会直接抛出异常(没有接受到服务端的响应),可以捕获这个异常来做其他的任务,同时监听connect的状态,连接成功时继续执行连接后的发送请求任务,select可以完成对socket状态的监听。
import socket #阻塞型 soc = socket.socket() soc.connect(("www.baidu.com",80)) #和服务端socket建立连接 request = """GET / HTTP/1.0 Host: www.baidu.com """ soc.send(request.encode(‘utf-8‘)) #向服务端发送请求头 response = soc.recv(8096) #接受服务端返回数据 print response #非阻塞型 # soc = socket.socket() # soc.setblocking(False) #socket变成非阻塞,但是执行connect()会直接抛出异常(BlockingIOError) # try: # soc.connect(("www.baidu.com",80)) # except Exception as e: # pass
IO多路复用(select):
select 可以同时监听多个文件描述符或socket对象的状态,接受四个参数rlist, wlist, xlist,timeout(可选),返回三个列表:r, w, e ;这里只谈论socket对象的部分:
r, w, e = select.select(rlist, wlist, xlist [, timeout] )
参数:
rlist: 包含socket对象的列表,select监听其是否可以被读取 (有数据传来)
wlist:包含socket对象的列表,select监听其是否可以被写入 (连接上服务器)
xlist:包含socket对象的列表,select监听其是否发生异常
timeout: 监听时最多等待时间
返回值
r : 返回rlist的子集,其包含的socket对象接收到了服务端发来的数据(可以读取了)
w:返回wlist的子集,其包含的socket对象连接上服务器,可以发送请求了(可以写入了)
x:返回wlist的子集,其包含的socket对象发生异常
监听列表中的元素除了为文件描述符和socket外,还可以为实现了fileno() (必须返回文件描述符)的任意对象,如下面的HttpContext对象。
class HttpContext(object): def __init__(self,socket): self.soc = socket def fileno(self): return self.soc.fileno()
基于异步IO的客户端:
#!/usr/bin/python #coding:utf-8 import socket import select class HttpResponse(object): def __init__(self,recv_data): self.data = recv_data self.headers = [] self.body = None self.initializa() def initializa(self): headers,body=self.data.split(‘ ‘,1) self.body=body self.headers=headers.split(‘ ‘) class HttpContext(object): def __init__(self,socket,task): self.host = task[‘host‘] self.port = task[‘port‘] self.url = task[‘url‘] self.method = task[‘method‘] self.data = task[‘data‘] self.callback = task[‘callback‘] self.soc = socket self.buffer = [] def fileno(self): return self.soc.fileno() def send_request(self): request = """%s %s HTTP/1.0 Host:%s %s"""%(self.method,self.url,self.host,self.data) self.soc.send(request.encode(‘utf-8‘)) def receive(self,size): return self.soc.recv(size) def finish(self): recv_data = ‘‘.join(self.buffer) self.soc.close() response = HttpResponse(recv_data) self.callback(self.host,response) class AsyncRequest(object): def __init__(self): self.connection=[] self.connected=[] def set_request(self,task): try: #必须进行异常捕获,否则会报错,[Errno 10035] soc = socket.socket() soc.setblocking(0) soc.connect((task[‘host‘],task[‘port‘])) except socket.error as e: pass request = HttpContext(soc,task) print request.host self.connected.append(request) self.connection.append(request) def run(self): while True: r, w, e = select.select(self.connected, self.connection, self.connected, 0.05) # w中存放的socket连接上了服务器 for request_obj in w: request_obj.send_request() self.connection.remove(request_obj) #r中存放的socket收到了服务器传递来的数据 for request_obj in r: while True: try: #必须进行异常捕获,否则会报错,[Errno 10035] res = request_obj.receive(8096) if not res: break else: request_obj.buffer.append(res) except socket.error as e: pass request_obj.finish() self.connected.remove(request_obj) if len(self.connected)==0: break def result(host,response): print host print response.headers #print response.body loop = AsyncRequest() url_list = [ {‘host‘:‘cn.bing.com‘,‘port‘:80,‘url‘:‘/‘,‘method‘:‘GET‘,‘data‘:‘‘,‘timeout‘:5,‘callback‘:result}, {‘host‘:‘www.baidu.com‘,‘port‘:80,‘url‘:‘/‘,‘method‘:‘GET‘,‘data‘:‘‘,‘timeout‘:5,‘callback‘:result}, {‘host‘:‘www.sina.com‘,‘port‘:80,‘url‘:‘/‘,‘method‘:‘GET‘,‘data‘:‘‘,‘timeout‘:5,‘callback‘:result}, ] for item in url_list: loop.set_request(item) loop.run()
执行结果如下,实现了一个线程中的并发,发送三个请求,并当有结果返回时,调用相应的回调函数处理请求。

基于异步IO的服务端:
#!/usr/bin/python #coding:utf-8 # 一个简单的异步IO服务端 import socket import select soc = socket.socket() soc.bind(("127.0.0.1",8080)) soc.listen(5) soc.setblocking(0) inputs = [soc,] outputs = [] while True: r,w,e = select.select(inputs,outputs,inputs) for sk in r: if sk==soc: # 服务端收到客户端的连接 ck,address = soc.accept() print "有连接来了:",address msg = ‘连接上了。。。。‘ ck.send(msg) ck.setblocking(0) inputs.append(ck) #将客户端socket加入监听队列 else: # 客户端发来数据 buffer=[] while True: try: #必须捕捉异常,否则会报错,[Errno 10035] data = sk.recv(1024) except socket.error as e: data=None if not data: break buffer.append(data) recv_data = ‘‘.join(buffer) print "接收到数据:%s" % recv_data inputs.remove(sk) sk.close() #客户端代码 # import socket # for i in range(3): # soc = socket.socket() # soc.connect((‘127.0.0.1‘,8080)) # response = soc.recv(8096) # print i,response.decode(‘utf-8‘) # soc.send(‘我是socket--%s‘%i)
import socket soc1 = socket.socket() soc1.connect((‘127.0.0.1‘,8080)) soc2 = socket.socket() soc2.connect((‘127.0.0.1‘,8080)) soc3 = socket.socket() soc3.connect((‘127.0.0.1‘,8080)) soc1.send(‘我是socket--%s‘%1) soc2.send(‘我是socket--%s‘%2) soc3.send(‘我是socket--%s‘%3)
对于测试客户端一,执行后,服务端结果如下,客户端三个socket都先连接上,随后发送的数据也成功接收,能实现一定的异步IO。
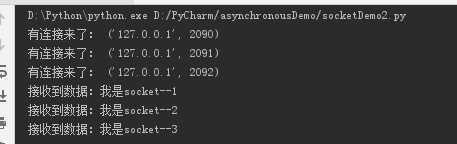
import socket for i in range(3): soc = socket.socket() soc.connect((‘127.0.0.1‘,8080)) response = soc.recv(8096) print i,response.decode(‘utf-8‘) soc.send(‘我是socket--%s‘%i)
对于测试客户端二,执行后,服务端结果如下,客户端三个socket都连接上,且发送的数据也成功接收,但是服务器依次处理每个请求,并不能异步,这是因为客户端和服务器间的数据交互期间会阻塞。

类似于tornado的异步非阻塞web框架(浏览器为客户端)
1. 版本一
#!/usr/bin/python #coding:utf-8 # 一个简单的异步IO服务端 import socket import select import time class HttpResponse(object): def __init__(self,content): self.content = content self.body = None self.method=‘‘ self.url=‘‘ self.protocol=‘‘ self.headers = {} self.initialize() def initialize(self): header,body = self.content.split(‘ ‘,1) header_list = header.split(‘ ‘) self.body=body #print header_list #[‘GET / HTTP/1.1‘, ‘Host: 127.0.0.1:8080‘, ‘User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:63.0) Gecko/20100101 Firefox/63.0‘, ‘Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, ‘Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2‘, ‘Accept-Encoding: gzip, deflate‘, ‘Connection: keep-alive‘, ‘Upgrade-Insecure-Requests: 1‘] for item in header_list: temp = item.split(‘:‘) if len(temp)==1: self.method,self.url,self.protocol=temp[0].split(‘ ‘) elif len(temp)==2: self.headers[temp[0]] = temp[1] soc = socket.socket() soc.bind(("127.0.0.1",8080)) soc.listen(5) soc.setblocking(0) inputs = [soc,] outputs = [] def main(request): time.sleep(10) return ‘main‘ def page(request): return ‘page‘ routers = [ (r‘/main‘,main), (r‘/page‘,page), ] while True: r,w,e = select.select(inputs,outputs,inputs) print r for sk in r: if sk==soc: # 服务端收到客户端的连接 print sk,‘sk‘ ck,address = soc.accept() print "有连接来了:",address # msg = ‘连接上了。。。。‘ # ck.send(msg) ck.setblocking(0) inputs.append(ck) #将客户端socket加入监听队列 else: # 客户端发来数据 print sk, ‘sk2‘ buffer=[] while True: try: #必须捕捉异常,否则会报错,[Errno 10035] data = sk.recv(8096) except socket.error as e: data=None if not data: break buffer.append(data) recv_data = ‘‘.join(buffer) # print recv_data response = HttpResponse(str(recv_data)) import re func=None for router in routers: ret = re.match(router[0], response.url) if ret: func = router[1] break if func: result = func(response) else: result=‘404‘ print result sk.sendall(result.encode(‘utf-8‘)) inputs.remove(sk) sk.close() # print "接收到数据:%s" % recv_data
上述代码运行时,若浏览器先访问‘/main’,再去访问‘/page’会阻塞,因为服务器在处理‘/main’的函数中,sleep出现阻塞,无法同时处理‘/page’请求。
下面两个版本,通过引入Future类,设置其属性result,对于需要阻塞的请求返回future对象,若future的result值为None,则继续阻塞,但当其值不会None时取消阻塞。但在其阻塞期间,其他的请求都可以正常访问。
2. 版本二
#!/usr/bin/python #coding:utf-8 # 一个简单的异步IO服务端 import socket import select import time class HttpRequest(object): def __init__(self,content): self.content = content self.body = None self.method=‘‘ self.url=‘‘ self.protocol=‘‘ self.headers = {} self.initialize() def initialize(self): splits = self.content.split(‘ ‘,1) if len(splits)==2: header, body=splits self.body = body elif len(splits)==1: header=splits[0] header_list = header.split(‘ ‘) #print header_list #[‘GET / HTTP/1.1‘, ‘Host: 127.0.0.1:8080‘, ‘User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:63.0) Gecko/20100101 Firefox/63.0‘, ‘Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, ‘Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2‘, ‘Accept-Encoding: gzip, deflate‘, ‘Connection: keep-alive‘, ‘Upgrade-Insecure-Requests: 1‘] for item in header_list: temp = item.split(‘:‘) if len(temp)==1: self.method,self.url,self.protocol=temp[0].split(‘ ‘) elif len(temp)==2: self.headers[temp[0]] = temp[1] class Future(object): def __init__(self,timeout=None): self.result=None self.timeout = timeout self.starttime = time.time() def set_result(self,result): self.result=result def delay_func(self,func,args): func(args) self.set_result(‘main‘) delay_socket={} def main(request): future=Future(10) return future def page(request): return ‘page‘ routers = [ (r‘/main‘,main), (r‘/page‘,page), ] def run(): soc = socket.socket() soc.bind(("127.0.0.1",8080)) soc.listen(5) soc.setblocking(0) inputs = [soc,] #r中的每一个socket数据接收后一定记得移除和关闭,不然后面每次循环还会循环到该socket,拿到的都将是空数据 while True: r,w,e = select.select(inputs,[],inputs,0.05) #timeout时间得设置,会一直阻塞 for sk in r: if sk==soc: # 服务端收到客户端的连接 ck,address = soc.accept() print "有连接来了:",address # msg = ‘连接上了。。。。‘ # ck.send(msg) ck.setblocking(0) inputs.append(ck) #将客户端socket加入监听队列 else: # 客户端发来数据 buffer=[] while True: try: #必须捕捉异常,否则会报错,[Errno 10035] data = sk.recv(8096) except socket.error as e: data=None if not data: break buffer.append(data) recv_data = ‘‘.join(buffer) response = HttpRequest(str(recv_data)) import re func=None for router in routers: ret = re.match(router[0], response.url) if ret: func = router[1] break if func: result = func(response) else: #其他url访问,如GET /favicon.ico HTTP/1.1(浏览器自动访问?) result=‘404‘ print result if isinstance(result, Future): delay_socket[sk] = result else: sk.sendall(result.encode(‘utf-8‘)) inputs.remove(sk) sk.close() for sk in delay_socket.keys(): future = delay_socket[sk] timeout = future.timeout start = future.starttime ctime = time.time() if (timeout+start)<=ctime: future.result=‘main‘ if future.result: sk.sendall(future.result) inputs.remove(sk) sk.close() del delay_socket[sk] if __name__ == ‘__main__‘: run()
上述代码运行时,若浏览器先访问‘/main’,再去访问‘/page’不会阻塞,而时立即返回,‘/main’请求在十秒后超时返回
3. 版本三
#!/usr/bin/python #coding:utf-8 # 一个简单的异步IO服务端 import socket import select import time class HttpRequest(object): def __init__(self,content): self.content = content self.body = None self.method=‘‘ self.url=‘‘ self.protocol=‘‘ self.headers = {} self.initialize() def initialize(self): splits = self.content.split(‘ ‘,1) if len(splits)==2: header, body=splits self.body = body elif len(splits)==1: header=splits[0] header_list = header.split(‘ ‘) #print header_list #[‘GET / HTTP/1.1‘, ‘Host: 127.0.0.1:8080‘, ‘User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:63.0) Gecko/20100101 Firefox/63.0‘, ‘Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, ‘Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2‘, ‘Accept-Encoding: gzip, deflate‘, ‘Connection: keep-alive‘, ‘Upgrade-Insecure-Requests: 1‘] for item in header_list: temp = item.split(‘:‘) if len(temp)==1: self.method,self.url,self.protocol=temp[0].split(‘ ‘) elif len(temp)==2: self.headers[temp[0]] = temp[1] class Future(object): def __init__(self,timeout=None): self.result=None self.timeout = timeout self.starttime = time.time() def set_result(self,result): self.result=result def delay_func(self,func,args): func(args) self.set_result(‘main‘) delay_socket={} future_list=[] def index(request): future=Future() future_list.append(future) return future def stopindex(request): f = future_list.pop() f.set_result(‘stop‘) return ‘stopindex‘ routers = [ (r‘/index‘,index), (r‘/stopindex‘,stopindex), ] def run(): soc = socket.socket() soc.bind(("127.0.0.1",8080)) soc.listen(5) soc.setblocking(0) inputs = [soc,] #r中的每一个socket数据接收后一定记得移除和关闭,不然后面每次循环还会循环到该socket,拿到的都将是空数据 while True: r,w,e = select.select(inputs,[],inputs,0.05) #timeout时间得设置,会一直阻塞 for sk in r: if sk==soc: # 服务端收到客户端的连接 ck,address = soc.accept() print "有连接来了:",address # msg = ‘连接上了。。。。‘ # ck.send(msg) ck.setblocking(0) inputs.append(ck) #将客户端socket加入监听队列 else: # 客户端发来数据 buffer=[] while True: try: #必须捕捉异常,否则会报错,[Errno 10035] data = sk.recv(8096) except socket.error as e: data=None if not data: break buffer.append(data) recv_data = ‘‘.join(buffer) response = HttpRequest(str(recv_data)) import re func=None for router in routers: ret = re.match(router[0], response.url) if ret: func = router[1] break if func: result = func(response) else: #其他url访问,如GET /favicon.ico HTTP/1.1(浏览器自动访问?) result=‘404‘ print result if isinstance(result, Future): delay_socket[sk] = result else: sk.sendall(result.encode(‘utf-8‘)) inputs.remove(sk) sk.close() for sk in delay_socket.keys(): future = delay_socket[sk] if future.result: sk.sendall(future.result) inputs.remove(sk) sk.close() del delay_socket[sk] if __name__ == ‘__main__‘: run()
上述代码运行时,若浏览器先访问‘/index’,会阻塞,而再去访问‘/stopindex’,两个请求都会立即访问
参考博客:
http://www.cnblogs.com/wupeiqi/p/6536518.html
http://www.cnblogs.com/wupeiqi/articles/6229292.html
https://www.cnblogs.com/aylin/p/5572104.html
以上是关于多线程,多进程和异步IO的主要内容,如果未能解决你的问题,请参考以下文章