聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
Posted ljy28
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用相关的知识,希望对你有一定的参考价值。
1.用python实现K均值算法
K-means是一个反复迭代的过程,算法分为四个步骤:
(x,k,y)
1) 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心;
def initcenter(x, k): kc
2) 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类;
def nearest(kc, x[i]): j
def xclassify(x, y, kc):y[i]=j
3) 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值;
def kcmean(x, y, kc, k):
4) 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)。
while flag:
y = xclassify(x, y, kc)
kc, flag = kcmean(x, y, kc, k)
2. 鸢尾花花瓣长度数据做聚类并用散点图显示。
3. 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类并用散点图显示.
4. 鸢尾花完整数据做聚类并用散点图显示.
#1.用python实现K均值算法
#K-means是一个反复迭代的过程,算法分为四个步骤:
import numpy as np
x = np.random.randint(1,50,[20,1])
y = np.zeros(20)
k = 3
#1) 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心;
def initcenter(x,k):
return x[:k]
#2) 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类;
def nearest(kc,i):
d = abs(kc -i)
w = np.where(d == np.min(d))
return w[0][0]
def xclassify(x, y, kc):
for i in range(x.shape[0]):
y[i] = nearest(kc, x[i])
return y
kc = initcenter(x,k)
y = xclassify(x,y,kc)
print(kc,y)
#3) 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值;
def kcmean(x,y,kc,k):
l = list(kc)
flag = False
for c in range(k):
m = np.where(y ==0)
n = np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True
print(l,flag)
return (np.array(l),flag)
#4) 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)
kc = initcenter(x,k)
flag = True
print(x,y,kc,flag)
while flag:
y = xclassify(x,y,kc)
kc,flag = kcmean(x,y,kc,k)
print(y,kc)

#2. 鸢尾花花瓣长度数据做聚类并用散点图显示
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data[:, 1]
y = np.zeros(150)
def initcent(x, k): # 初始聚类中心数组
return x[0:k].reshape(k)
def nearest(kc, i): # 数组中的值,与聚类中心最小距离所在类别的索引号
d = (abs(kc - i))
w = np.where(d == np.min(d))
return w[0][0]
def kcmean(x, y, kc, k): # 计算各聚类新均值
l = list(kc)
flag = False
for c in range(k):
m = np.where(y == c)
n = np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True # 聚类中心发生变化
return (np.array(l), flag)
def xclassify(x, y, kc):
for i in range(x.shape[0]): # 对数组的每个值分类
y[i] = nearest(kc, x[i])
return y
k = 3
kc = initcent(x, k)
flag = True
print(x, y, kc, flag)
while flag:
y = xclassify(x, y, kc)
kc, flag = kcmean(x, y, kc, k)
print(y, kc, type(kc))
import matplotlib.pyplot as plt
plt.scatter(x,x,c=y,s=50,cmap=‘rainbow‘,marker=‘p‘,alpha=0.5)
plt.show()
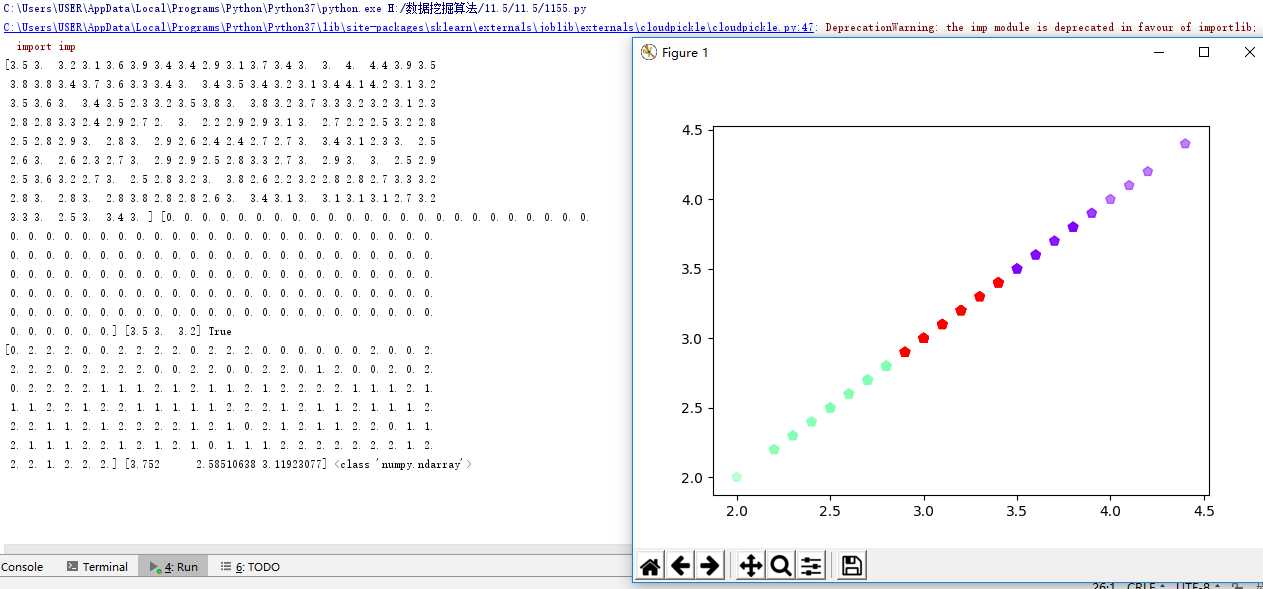
#3.用sklearn.cluster.KMeans,鸢尾花完整数据做聚类并用散点图显示. import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import load_iris iris=load_iris() print(iris) X=iris.data print(X) from sklearn.cluster import KMeans est = KMeans(n_clusters=3) est.fit(X) kc = est.cluster_centers_ y_kmeans = est.predict(X) #预测每个样本的聚类索引 print(y_kmeans,kc) print(kc.shape,y_kmeans.shape) plt.scatter(X[:,0],X[:,1],c=y_kmeans,s=50,cmap=‘rainbow‘) plt.show()
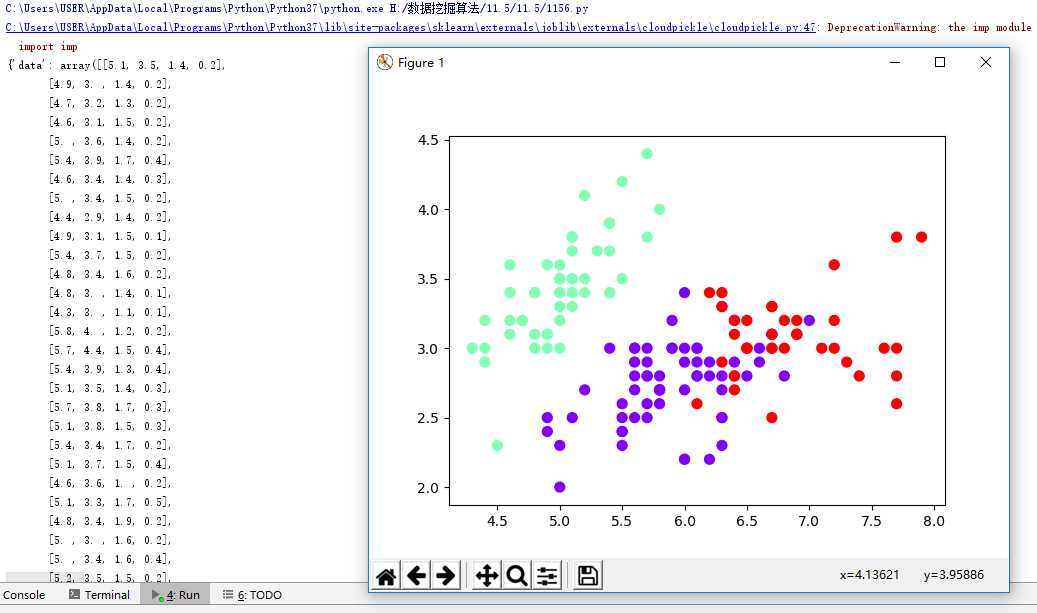


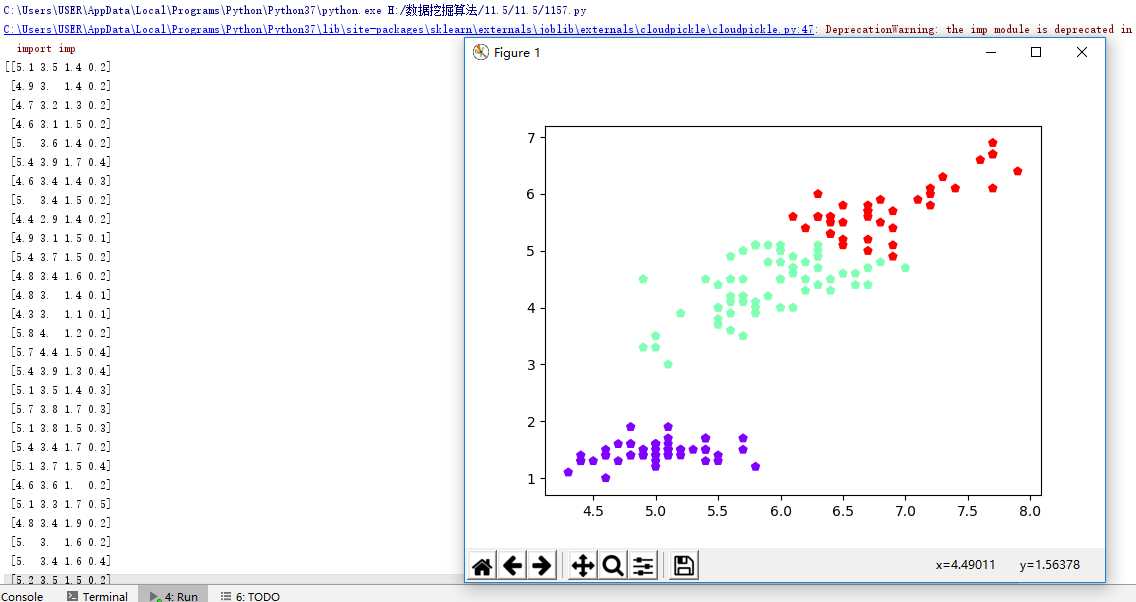
#4. 鸢尾花完整数据做聚类并用散点图显示. from sklearn.cluster import KMeans import numpy as np from sklearn.datasets import load_iris import matplotlib.pyplot as plt data = load_iris() iris = data.data petal_len = iris print(petal_len) k_means = KMeans(n_clusters=3) #三个聚类中心 result = k_means.fit(petal_len) #Kmeans自动分类 kc = result.cluster_centers_ #自动分类后的聚类中心 y_means = k_means.predict(petal_len) #预测Y值 plt.scatter(petal_len[:,0],petal_len[:,2],c=y_means, marker=‘p‘,cmap=‘rainbow‘) plt.show()
以上是关于聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用的主要内容,如果未能解决你的问题,请参考以下文章
聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用