寄存器与代码段
Posted kksjs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了寄存器与代码段相关的知识,希望对你有一定的参考价值。
汇编语言系列学习笔记:
- 汇编语言初探
- 寄存器与代码段(本文)
- 寄存器与数据段(待完成)
- 寄存器与栈段(待完成)
在上一篇博文中主要介绍了学习汇编语言的一些必备知识。其中和这篇文章联系比较紧密的是内存地址单元与 CPU 的概念,不熟悉的可以先行阅读上一篇博文。
在学习寄存器这两章内容的时候,首先要牢记一个观点:指令和数据在内存单元中没有任何区别,它们都是一些二进制信息。
CPU 在读取内存中二进制信息的时候,将有的信息看作指令,有的信息看作数据。
在接下来的三篇博文中将具体介绍 CPU 到底是根据什么来做出的这种区分的。
一、寄存器的概念
寄存器是位于 CPU 内部的一种带有存储性质的器件。寄存器在汇编语言中有着举足轻重的地位,因为程序员可以通过改变寄存器中的内存来实现对 CPU 的控制。
8086CPU 中总有有 14 种不同种类的寄存器,它们分别是:AX、BX、CX、DX、SI、DI、SP、BP、IP、CS、SS、DS、ES、PSW。
它们最大能存储 16bit 的数据。
接下来的几篇文章将逐个的介绍这些寄存器的作用。
(一)通用寄存器
8086CPU 中的通用寄存器有下面四种:
- AX(accumulator):累加寄存器,常用于运算。
- BX(base):基址寄存器,常用于地址索引。
- CX(count):计数寄存器。
- DX(data):数据寄存器,常用于数据传递。
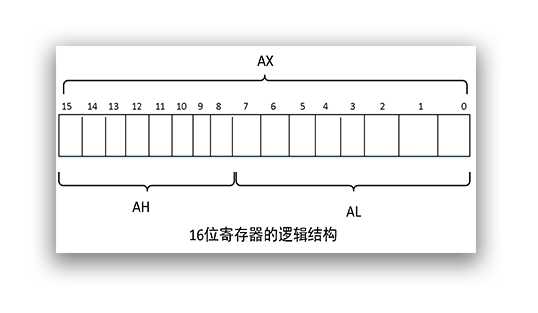
从上图可知,一个 16 位寄存器可以存储一个 16 位数据。由于 8086CPU 上一代的寄存器都是 8 位的,为了保证兼容性,一个 16 位通用寄存器通常还能当做两个独立的 8 位寄存器使用。
比如,AX 可以分为 AH 和 AL,见下图:
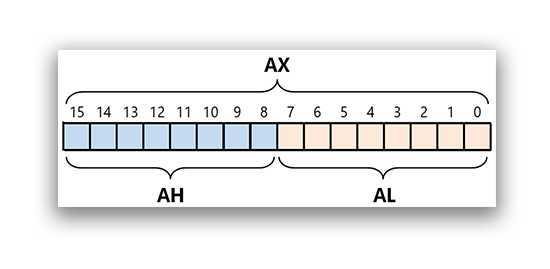
AX 的低 8 位(0 位 ~ 7 位)构成了 AL 寄存器,高 8 位(8 位 ~ 15 位)构成了 AH 寄存器。
8086CPU 可以一次性处理这两种不同长度的数据,分别称为:
- 字(word):16 位
- 字节(byte):8 位
(二)段寄存器和指针寄存器
8086CPU 中的段寄存器和指针寄存器有下面四种:
- CS(code segment):代码段寄存器
- DS(data segment):数据段寄存器
- SS(stack segment):栈段寄存器
- ES(extra segment):附加段寄存器
- IP(instruction pointer):指令指针寄存器
- SP(stack pointer):栈指针寄存器
- BP(base pointer):基址指针寄存器
其中 CS 和 IP 是本文着重要介绍的,其余的将在后面学习到。
首先想一想 “ 段 ” 这个概念从何而来?这就要从 8086CPU 与内存之间的地址总线宽度说起了。
8086CPU 的地址总线宽度是 20 位,即一次性可以传送 20 位的地址,理论上能达到 1MB 的寻址能力。但是我们上面介绍的寄存器最高也只有 16 位,无法直接生成 20 位的地址。
为了不白白的浪费 4 位地址总线,在 8086CPU 中采用一种将两个 16 位地址合成一个 20 位地址的方法。
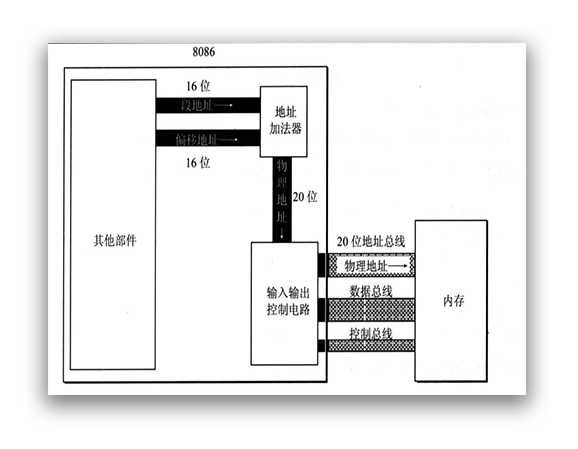
如图所示,在 8086 中是通过一个地址加法器来完成的这种转换:物理地址(20 bit) = 段地址(16 bit) × 16 + 偏移地址(16 bit)。其中段地址就存储在段寄存器中。而偏移地址则保存在指针寄存器中。
这个公式隐含着两个注意点:
- 因为 段地址 × 16 的大小必然是 16 的倍数,所以一个段内存空间的起始地址必然也是 16 的倍数。
- 因为偏移地址为 16 位,所以一个段的最大空间只有 216 B = 64 KB。
这里有一个因果关系要明确:首先是因为 CPU 与内存之间的地址总线的宽度(1MB)高于 CPU 一次性能处理、传输、暂存的最大宽度(64KB),为了不浪费 CPU 的寻址能力,才会有 物理地址(20 bit) = 段地址(16 bit) × 16 + 偏移地址(16bit) 这样的一个转换机制。
所以我在想,要是做个假设,CPU 中的寄存器都是 20 bit,或者地址总线只有 16 bit 的话,是不是也许就没有段地址这个说法了(这是我个人的思考,如果有不对的地方,烦请指正~)。
二、代码段
上面讲了一些比较常用的寄存器,其中 CS 和 IP 寄存器是两个最为关键的寄存器,它们这两个寄存器中的值组合起来 CS:IP 表示了 CPU 当前要读取指令的地址。
也就是说:在 8086PC 机中,任意时刻,CPU 将 CS:IP 指向的内容当做指令执行。
为了接下来的讲解,先学习几条会用到的汇编指令:
- mov ax,4E20H:将 4E20H 这个数送入寄存器 AX。
- add ax,1406H:将寄存器 AX 中的数值加上 1406H。
假设现在有下面四条汇编指令:
- mov ax,0123H
- mov bx,0003H
- mov ax,bx
- add ax,bx
对应的机器指令为:
- B8H 23H 01H
- BBH 03H 00H
- 89H D8H
- 01H D8H
现在的一个编程需要是想让 CPU 顺序执行上面四条指令,可以将这四条指令的机器码存放在一组连续的、起始地址为 16 的倍数的一组内存单元中,如下图:
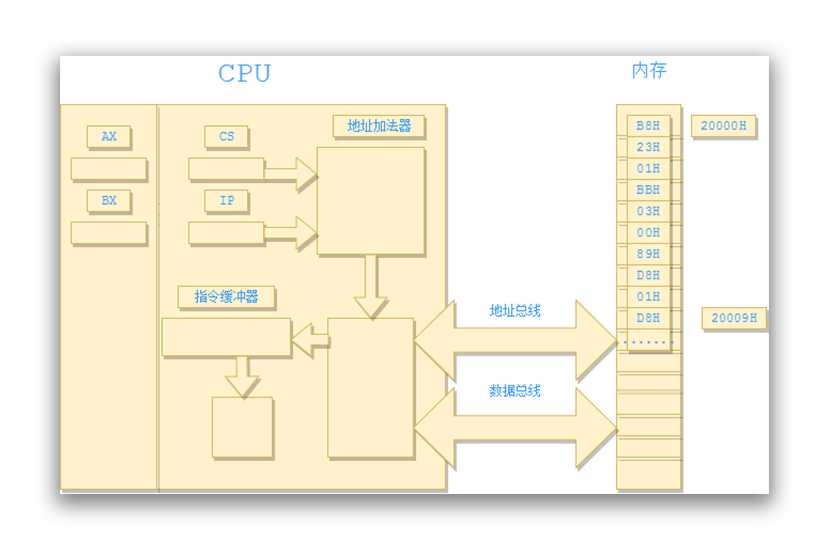
这样我们就定义了一个所谓的代码段,这个代码段从内存的第 20000H 号单元开始,存放了 10 字节的指令。
要想让 CPU 执行这段代码,首先需要将 CS 的内容置为 2000H,IP 的内容置为 0000H。这样 CPU 就从内存单元的 20000H 处开始执行。
下面以一张动图来演示 CPU 执行第一条指令时 CPU 与内存的信息交互情况:
(动图演示)
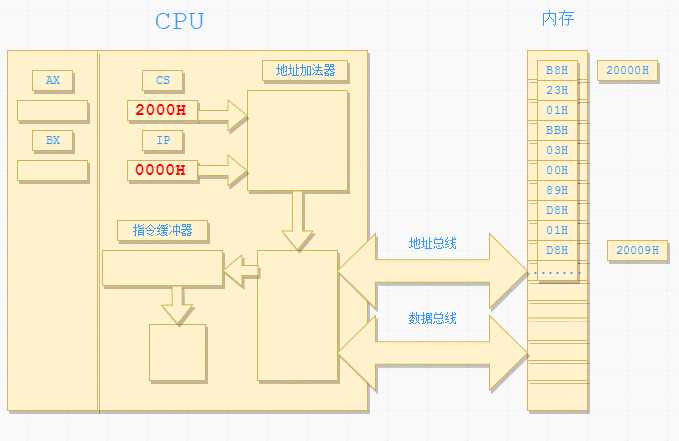
这张动图清晰的展示了 CPU 是如何执行处于上面内存代码段中的第一条指令(隐藏了很多的细节)。由于指令的执行过程类似,加上制作动图比较耗费时间,就省略了剩余的三条指令的执行过程(- -!)。
三、总结
本篇博文首先介绍了 CPU 中的寄存器种类,通过一个地址转换公式引出了两个重要的寄存器 CS 和 IP。有了这两个寄存器的功能做支持,就可以定义一个存放代码的代码段,并让 CPU 去执行这个代码段。
最后还是引出文章开始的一句话:指令和数据在内存中没有区别,它们都是一些二进制信息,把这些二进制信息看作指令还是数据,是让编程人员通过控制 CPU 中的寄存器来完成的。
(完)
以上是关于寄存器与代码段的主要内容,如果未能解决你的问题,请参考以下文章