支持向量机-引入及原理
Posted gezhuangzhuang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了支持向量机-引入及原理相关的知识,希望对你有一定的参考价值。
支持向量机(Support Vector Machines, SVM):是一种监督学习算法。处理二分类
- 支持向量(Support Vector)就是离分隔超平面最近的那些点。
- 机(Machine)就是表示一种算法,而不是表示机器。
线性可分数据集:将数据集分隔开的直线称为分隔超平面。我们希望找到离分隔超平面最近的点,确保它们离分隔面的距离尽可能远,这里点到分隔面的距离被称为间隔(margin)。
线性不可分数据集:利用核函数(kernel)将数据映射到高维,转化成线性可分
支持向量机 场景
- 要给左右两边的点进行分类
- 明显发现:选择D会比B、C分隔的效果要好很多。
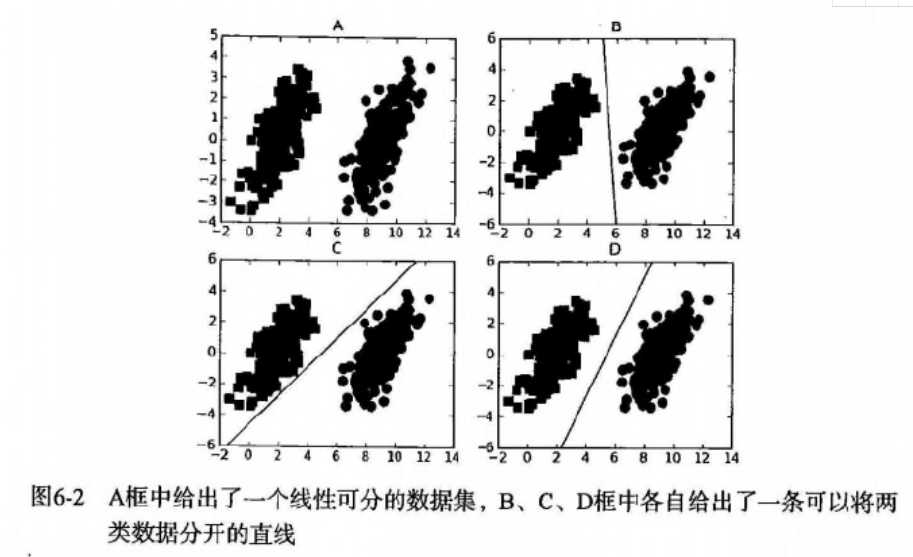
寻找最大间隔
分隔超平面是一条直线,点到超平面的距离 == 点到直线的距离
点到直线的距离公式
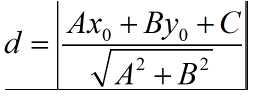
理论推导(李航的统计学习方法):

定义拉格朗日函数:
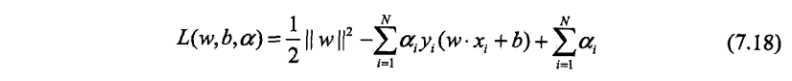

将目标函数有极大转换成求极小,就得到下面与之等价的对偶最优化问题

但是几乎所有数据都不那么“干净”,引入松弛变量,允许数据点可以处于分隔面的错误一侧
此时新的约束条件则变为:
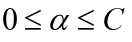
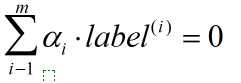
总的来说:
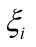 表示松弛变量
表示松弛变量
常量C是 惩罚因子, 表示离群点的权重(用于控制“最大化间隔”和“保证大部分点的函数间隔小于1.0” )
- C值越大,表示离群点影响越大,就越容易过度拟合;反之有可能欠拟合。
- 我们看到,目标函数控制了离群点的数目和程度,使大部分样本点仍然遵守限制条件。
- 例如:正类有10000个样本,而负类只给了100个(C越大表示100个负样本的影响越大,就会出现过度拟合,所以C决定了负样本对模型拟合程度的影响!,C就是一个非常关键的优化点!)
SVM中的主要工作就是要求解 alpha.
以上是关于支持向量机-引入及原理的主要内容,如果未能解决你的问题,请参考以下文章