Meta 推出大型语言模型 LLaMA,比 GPT3.5 性能更高
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Meta 推出大型语言模型 LLaMA,比 GPT3.5 性能更高相关的知识,希望对你有一定的参考价值。

整理 | 禾木木 责编 | 梦依丹
出品 | CSDN(ID:CSDNnews)
ChatGPT 的爆火使得大家对 AI 进行了深度的讨论,大厂们也都在向公众展示他们所谓的 "生成性人工智能"已经准备好进入黄金时代。
近日,Meta 宣布推出大型语言模型 LLaMA(Large Language Model Meta AI),加入到由微软、谷歌等科技巨头主导的 AI“军备竞赛”中。同 ChatGPT、New Bing 不同,LLaMA 并不是一个任何人都可以与之对话的产品,也并未接入任何 Meta 应用。
公司 CEO 扎克伯格表示,LLaMA 旨在帮助研究人员推进研究工作,LLM(大型语言模型)在文本生成、问题回答、书面材料总结,以及自动证明数学定理、预测蛋白质结构等更复杂的方面也有很大的发展前景。能够降低生成式 AI 工具可能带来的“偏见、有毒评论、产生错误信息的可能性”等问题。

Meta 表示,LLaMA 可以在非商业许可下提供给政府、社区和学术界的研究人员和实体工作者,正在接受研究人员的申请。
此外,LLaMA 将提供底层代码供用户使用,因此用户可以自行调整模型,并将其用于与研究相关的用例。
目前 Meta 在 GitHub 上提供了精简版 LLaMA。


比 GPT3.5 性能更高:参数规模小、训练数据多
Meta 目前提供有 70 亿、130 亿、330 亿和 650 亿四种参数规模的 LLaMA 模型。
在一些测试中,仅有 130 亿参数的 LLaMA 模型,性能表现超过了拥有 1750 亿参数的 GPT-3,而且能跑在单个 GPU 上;拥有 650 亿参数的 LLaMA 模型,能够媲美 700 亿参数的 Chinchilla 和拥有 5400 亿参数的 PaLM。
与此同时,所有规模的 LLaMA 模型,都至少经过了 1T(1万亿)个 token 的训练,这比其他相同规模的模型要多得多。例如,LLaMA 65B 和 LLaMA 33B 在 1.4 万亿个 tokens 上训练,而最小的模型 LLaMA 7B 也经过了 1 万亿个 tokens 的训练。
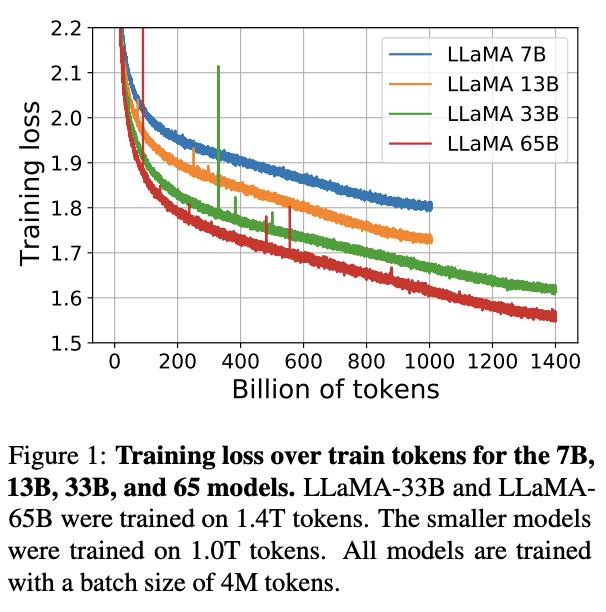
与其他大型语言模型一样,LLaMA 的工作原理是将一系列 tokens 作为输入,并预测下一个单词以递归生成文本,Meta 使用了 20 种语言对其进行训练。

AI 能力结果评估
在常识推理方面 LLaMA 涵盖了八个标准常识性数据基准。这些数据集包括完形填空、多项选择题和问答等。
结果显示,拥有 650 亿参数的 LLaMA 在 BoolQ 以外的所有报告基准上均超过拥有 700 亿参数的 Chinchilla。
同时,除 BoolQ 和 WinoGrande 外,该模型测试中均超过拥有 5400 亿参数的 PaLM。拥有 130 亿参数的 LLaMA 模型在大多数基准测试上也优于拥有 1750 亿参数的 GPT-3。
闭卷答题和阅读理解方面,LLaMA-65B 几乎在所有基准上和 Chinchilla-70B 和 PaLM-540B 不相上下。
在数学推理方面,它在 GSM8k上 的表现依然要优于 Minerva-62B。
在代码生成测试上,基于编程代码开源数据集 HumanEval 和小型数据集 MBPP,被评估的模型将会收到几个句子中的程序描述以及输入输出实例,然后生成一个符合描述并能够完成测试的Python程序。
LLaMA-62B 优于 cont-PaLM(62B)以及 PaLM-540B。
此外, 在大规模多任务语言理解和训练期间的能力进化上,都有不错的表现

结语
Meta 的目标是在未来发布更大的模型,这些模型在更广泛的预训练数据集上进行训练,同时它观察到随着规模的扩大,性能也在稳步提高。
在这场争夺 AI 霸主地位的竞赛中,OpenAI 率先发布了 ChatGPT,谷歌很快以其 "实验性 "聊天机器人 Bard 紧随其后,而中国科技巨头百度正计划以 Ernie Bot- ERNIE 3.0 进入战场。更不用说微软声称正建立在 "新的下一代 OpenAI 大型语言模型 "基础上的 Bing Chat(又名Sydney),它比 ChatGPT 更先进,而且还与 Bing 搜索整合。
大家也都在等待下一位官方声明,虽然 Meta 在这一领域进行了多次失败的尝试,但并没有被吓倒,它继续试验基于 LLM 的模型,成功推出 LLaMA。
随着其以前的模型在历史的尘埃中结束,每个人心中的问题是:Meta 这次真的能站出来吗?
AI 霸主之争还在持续升温,所有的目光都再次集中在 Meta 上,看看它是否有能力与大炮交锋。它是否能作为一个强有力的竞争者出现,还是像以前的模型那样,随着 LLaMA 的出现而逐渐消失?
未来,只有时间能证明。
参考链接:
https://analyticsindiamag.com/meta-launches-new-llm-llama-which-outperforms-gpt-3-at-a-fraction-of-the-size/
https://www.theverge.com/2023/2/24/23613512/meta-llama-ai-research-large-language-model
https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
www.facebook.com

以上是关于Meta 推出大型语言模型 LLaMA,比 GPT3.5 性能更高的主要内容,如果未能解决你的问题,请参考以下文章