[转帖]InfiniBand 主流厂商 和 产品分析
Posted jinanxiaolaohu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[转帖]InfiniBand 主流厂商 和 产品分析相关的知识,希望对你有一定的参考价值。
InfiniBand 主流厂商 和 产品分析

Mellanox成立于1999年,总部设在美国加州和以色列,Mellanox公司是服务器和存储端到端连接InfiniBand解决方案的领先供应商。2010年底Mellanox完成了对著名Infiniband交换机厂商Voltaire公司的收购工作,使得Mellanox在HPC、云计算、数据中心、企业计算及存储市场上获得了更为全面的能力。
还有一家InfiniBand技术厂商就是Intel,Intel拿出1.25亿美元收购QLogic的InfiniBand交换机和适配器产品线发力于高性能计算领域,但今天我们重点讨论Mellanox的产品、技术和趋势。
IB 网络和拓扑组成
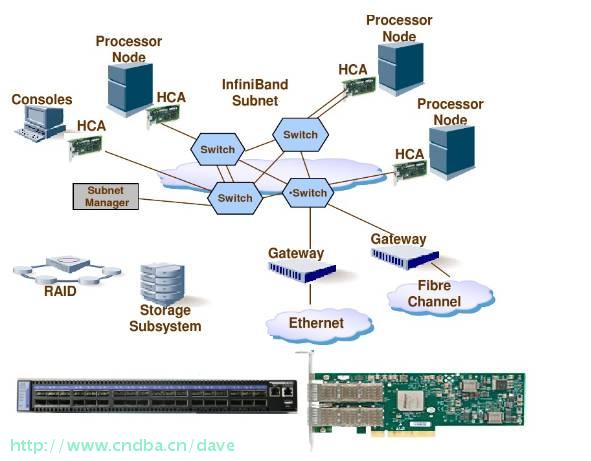
InfiniBand结构基于信道的串口替代共用总线,从而使I/O子系统和CPU/内存分离。所有系统和节点可通过信道适配器逻辑连接到该结构,它们可以是主机、适配器(HCA)或目标适配器(TCA),还包括InfiniBand交换机和路由器扩展,从而满足不断增长的需求。
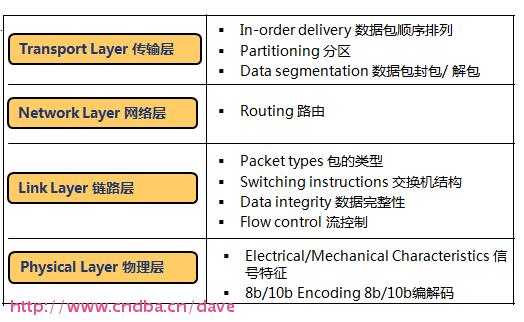
InfiniBand也是一种分层协议(类似TCP/IP协议),每层负责不同的功能,下层为上层服务,不同层次相互独立,每一层提供相应功能。InfiniBand协议可满足各种不同的需求,包括组播、分区、IP兼容性、流控制和速率控制等。
InfiniBand网络路由算法包括最短路径算法、基于Min Hop的UPDN 算法和基于Fat Tree组网FatTree算法。
算法在一定程度上也决定了InfiniBand网络拓扑结构,尤其在高性能计算、大型集群系统,必须要考虑网络之间的拓扑结构,网络上行和下行链路阻塞情况也决定着整个网络性能。由于树形拓扑结构具备清晰、易构建和管理的有点,故而胖树网络拓扑结构常常被采用,以便能够发挥出InfiniBand网络优势,也通常应用在无阻塞或阻塞率很低的应用场景,所以我们下面我们重点讨论下。
在传统的三层组网架构中(二层架构也经常用到),由于接入层节点数量庞大,所以要求汇聚层或核心层的网络带宽和处理能力与之匹配,否则设计出来的网络拓扑结构就会产生一定的阻塞比。

为了解决这一问题,在汇聚层和核心层就要采用胖节点组网(如果采用瘦节点就一定发生阻塞,且三层组网阻塞比二层组网更加严重),如上图胖二叉树事例,胖节点(Fat Tree)必须提供足够的网络端口和带宽与叶子节点匹配。
采用胖树拓扑网络的结构一般由叶子(Leaf)和主干(Spine)交换机组成,叶子交换机与服务器或存储等信道适配卡相连,分配一部分端口给节点,另一部分端口被接入网络中。在InfiniBand网络中Fat Tree组网结构具有下面几个特点。
1) 连接到同一端Switch的端口叫端口组,同一Rank级别的Switch必须有相同的上行端口组,且根Rank没有上行端口组;除了Leaf Switch,同一Rank的Switch必须有相同的下行端口组。
2) 同一Rank的每个上行端口组中端口个数相同;且同一Rank的每个下行端口组中端口个数也相同。
3) 所有终端节点的HCA卡都在同一Rank级别上。
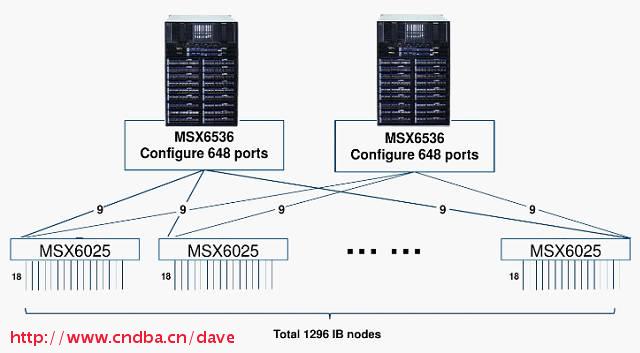
上图是一个采用二层架构的无阻塞Fat Tree组网事例,接入层下行提供1296个IB端口给服务器或存储适配卡,上行也提供适配器给汇聚层。但从一个接入IB交换机来看,上行和下行分别提供18个接口实现无阻塞组网。胖树拓扑结构一方面提供费阻塞数据传输,另一方面提供网络冗余增强网络可靠性。
软件协议栈OFED
为服务器和存储集群提供低延迟和高带宽的企业数据中心(EDC),高性能计算(HPC)和嵌入式应用环境。 Mellanox所有适配卡与基于Open Fabrics的RDMA协议和软件兼容。2004年OpenFabrics Alliance成立,该组织致力于促进RDMA 网络交换技术的发展。2005年,OpenFabrics Alliance发布了第一个版本的OFED(OpenFabrics Enterprise Distribution)。
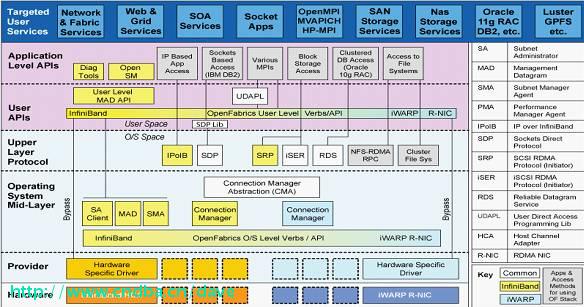
Mellanox OFED是一个单一的软件堆栈,包括驱动、中间件、用户接口,以及一系列的标准协议IPoIB、SDP、SRP、iSER、RDS、DAPL(Direct Access Programming Library),支持MPI、Lustre/NFS over RDMA等协议,并提供Verbs编程接口;Mellanox OFED由开源OpenFabrics组织维护。
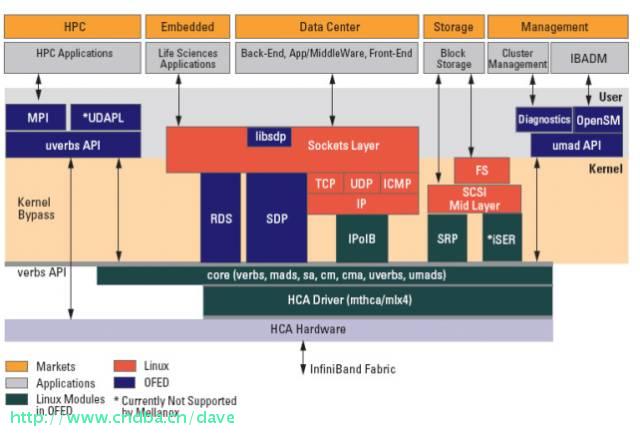
如果前面的软件堆栈逻辑图过于复杂,可以参考上面的简明介绍图。Mellanox OFED for Linux (MLNX_OFED_LINUX) 作为ISO映像提供,每个Linux发行版,包括源代码和二进制RPM包、固件、实用程序、安装脚本和文档。
InfiniBand网络管理
OpenSM软件是符合InfiniBand的子网管理器(SM),运行在Mellanox OFED软件堆栈进行IB 网络管理,管理控制流走业务通道,属于带内管理方式。
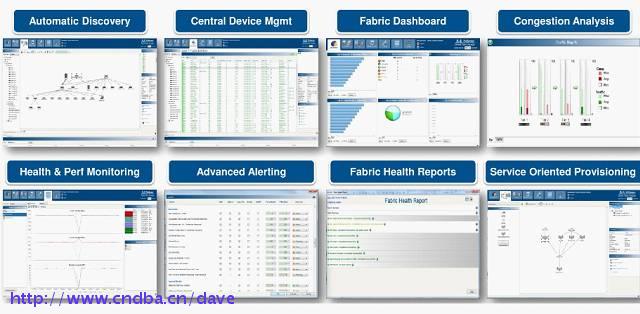
OpenSM包括子网管理器、背板管理器和性能管理器三个组件,绑定在交换机内部的必备部件。提供非常完备的管理和监控能力,如设备自动发现、设备管理、Fabric可视化、智能分析、健康监测等等。
并行计算集群能力
MPI (Message Passing Interface) 用于并行编程的一个规范,并行编程即使用多个CPU来并行计算,提升计算能力。Mellanox OFED for Linux的InfiniBand MPI实现包括Open MPI和OSU MVAPICH。
Open MPI是基于Open MPI项目的开源MPI-2实现,OSU MVAPICH是基于俄亥俄州立大学的MPI-1实施。下面列出了一些有用的MPI链接。

RDS (Reliable Datagram Socket)是一种套接字API,在sockets over RC or TCP/IP之间提供可靠的按顺序数据报传送,RDS适用于Oracle RAC 11g。
基于socket网络应用能力
IPoIB/ EoIB (IP/Eth over InfiniBand) 是通过InfiniBand实现的网络接口实现,IPoIB封装IP数据报通过InfiniBand连接或数据报传输服务。
SDP (Socket Direct Protocol) 是提供TCP的InfiniBand字节流传输协议流语义,利用InfiniBand的高级协议卸载功能,SDP可以提供更低的延迟更高带宽。
存储支持能力
支持iSER (iSCSI Extensions for RDMA)和NFSoRDMA (NFS over RDMA),SRP (SCSI RDMA Protocol) 是InfiniBand中的一种通信协议,在InfiniBand中将SCSI命令进行打包,允许SCSI命令通过RDMA(远程直接内存访问)在不同的系统之间进行通信,实现存储设备共享和RDMA通信服务。
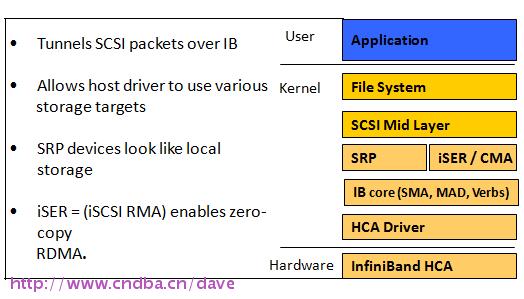
RDMA (Remote Direct Memory Access)技术是为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA通过网络把数据直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就不需要用到多少计算机的处理功能。它消除了外部存储器复制和文本交换操作,因而释放内存带宽和CPU周期用于改进应用系统性能。
Mellanox产品介绍
Mellanox是服务器和存储端到端连接解决方案的领先供应商,一直致力于InfiniBand和以太网互联产品的研发工作,也是业界公认的超高速网络典型代表。下面我们重点看看InfiniBand和相关产品介绍。
InfiniBand产品搭配先进的VPI技术使得单端口适配业务需求,主要产品包括VPI系列网卡、交换机。芯片产品也是保障所有系列产品的可靠基石。种类丰富的线缆是实现高速互联网络的重要保证。除了硬件外,InfiniBand配套加速软件和统一管理软件丰富整个产品家族。
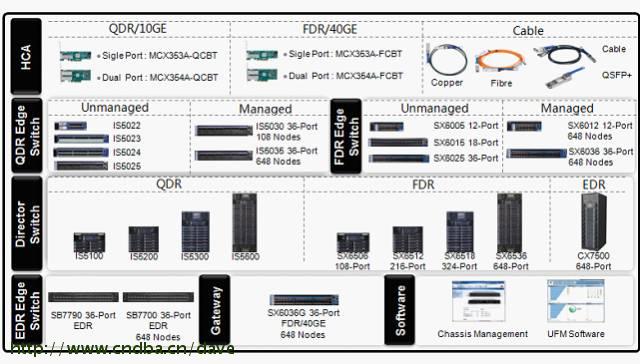
Infiniband交换机
在IB网络内提供点到点高速通信;基于LID技术将数据从一个端口送到另外一个端口 ,当前单个交换机支持从18到864节点等规模不等,支持SDR(10Gbps)、DDR(20Gbps)、QDR(40Gbps)、FDR10(40Gbps)、FDR(56Gbps)等。
从SwitchX 到Switch IB,SwitchX是支持10、20、40、56 G IB主流的芯片,下一代芯片Switch IB支持IB EDR 100Gb/s,并且向前兼容,后面还有SwitchX3支持100G和IB EDR。
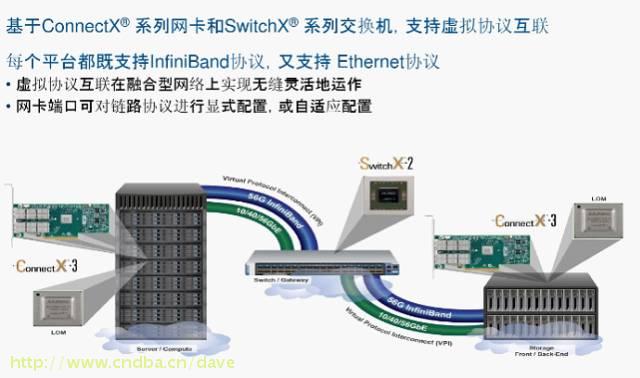
基于ConnectX系列网卡和SwitchX交换机可以实现以太网和IB网络的虚拟协议互联(VPI),实现链路协议显示或自动适配,一个物理交换机实现多种技术支持。虚拟协议互联支持整机VPI、端口VPI和VPI桥接,整机VPI实现交换机所有端口运行在InfiniBand或以太网模式,端口VPI实现交换机部分端口运行InfiniBand、部分端口运行以太网模式,VPI桥接模式实现InfiniBand和以太网桥接。
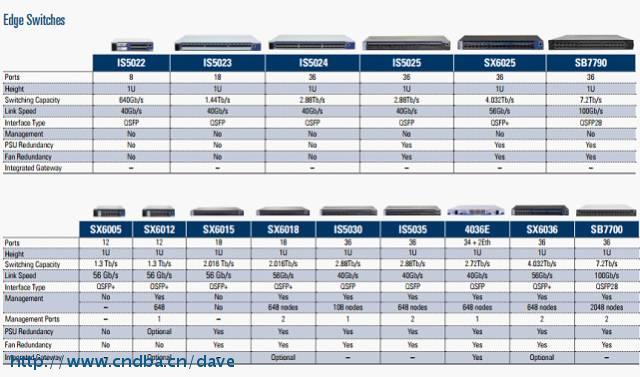
边缘(机架) InfiniBand交换机系统支持8到36端口,提供非阻塞40到100Gb 端口,在1U的空间可提供7.2Tb的带宽,这些边缘交换机是组成中小型费阻塞网络集群Leaf节点的理想选择。边缘交换机使用先进的InfiniBand交换技术(如自适应路由、拥塞控制和服务质量等)旨在构建最有效的交换矩阵。
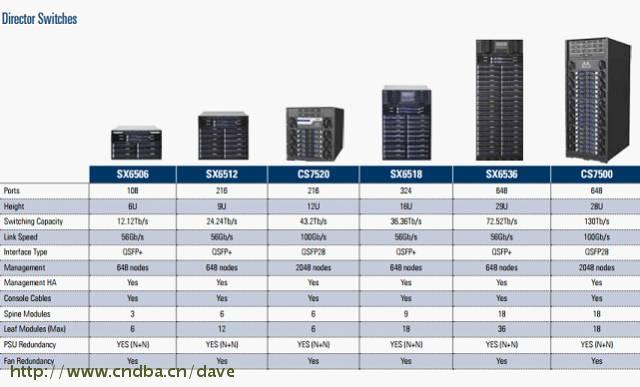
核心InfiniBand交换机系统支持108至648端口,提供全双向40至100Gb端口, InfiniBand核心交换机系统提供高密的解决方案,在一个机框内带宽可以8.4Tb至130Tb之间灵活扩展,可达数千个端口。针对关键任务应用,InfiniBand核心交换机提供核心级可用性,系统所有部件都采用冗余技术设计。
InfiniBand适配器
Inifiniband的主机信道适配器HCA(网络接口卡),通常通过PCIE接口与主机连接,插在或集成在服务器内;支持PCI-E 8X插槽(双端口和单端口)。提供Inifiniband的网络链路接入能力。等同于以太网的NIC。HCA包含三代芯片:目前主流的QDR,FDR使用的芯片为ConnectX3,OSCA使用的也是ConnectX3

目标信道适配器(TCA)提供InfiniBand到I/O设备的连接,绑定在存储或网关设备等外设。
Infiniband路由器和网关设备
Infiniband路由器完成不同子网的infiniband报文的转发。Mellanox的SB7780是基于Switch-IB交换机ASIC实现的InfiniBand路由器,提供EDR 100Gb s端口可以连接不同类型的拓扑。因此,它能够使每个子网拓扑最大化每个应用程序的性能。例如,存储子网可以使用Fat Tree拓扑,而计算子网可以使用最适合本地应用程序的环路拓扑。

SX6036G是采用Mellanox第六代SwitchX 2 InfiniBand构建的交换机网关设备,提供高性能、低延迟的56Gb FDR Infiniband到40Gb以太网的网关,支持InfiniBand和以太网连接的虚拟协议互连(VPI)技术,VPI通过一个硬件平台能够在同一机箱上运行InfiniBand和以太网网络协议。
Infiniband线缆和收发器
Mellanox LinkX互连产品包括10、25、40、50和100 Gb/s丰富铜缆、有源光缆以及针对单模光纤和多模光纤应用的收发器。

LinkX系列提供200Gb/s和400Gb/s电缆和收发器等关键组件,对于InfiniBand互连基础设施来说,让端到端的200Gb/s解决方案成为可能。
以上是关于[转帖]InfiniBand 主流厂商 和 产品分析的主要内容,如果未能解决你的问题,请参考以下文章
[转帖]InfiniBand, RDMA, iWARP, RoCE , CNA, FCoE, TOE, RDMA, iWARP, iSCSI等概念