过去一年有哪些值得关注的时间序列工作?
Posted fareise
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了过去一年有哪些值得关注的时间序列工作?相关的知识,希望对你有一定的参考价值。
在我的公众号“圆圆的算法笔记”中,为大家整理了数十篇一文贯通干货算法笔记,每一篇笔记详细梳理了一个子方向的顶会工作和它们的关系,涉及序预测、元学习、推荐系统、NLP、多模态、表示学习等多个领域,感兴趣的同学可以公众号后台回复【CSDN干货】获取笔记~
2022年是深度学习在时间序列中应用最为广泛深入的一年,很多NLP、CV中的深度学习方法,越来越多被应用到时间序列领域。同时,在时间序列中应用深度学习方法,也从原来的照搬模型,这篇文章汇总了一些2022年出现的顶会经典时间序列建模方法,供大家参考,论文来自ICML、ICLR、NIPS、IIJCAI、AAAI等。
TS2Vec: Towards Universal Representation of Time Series(AAAI 2022)
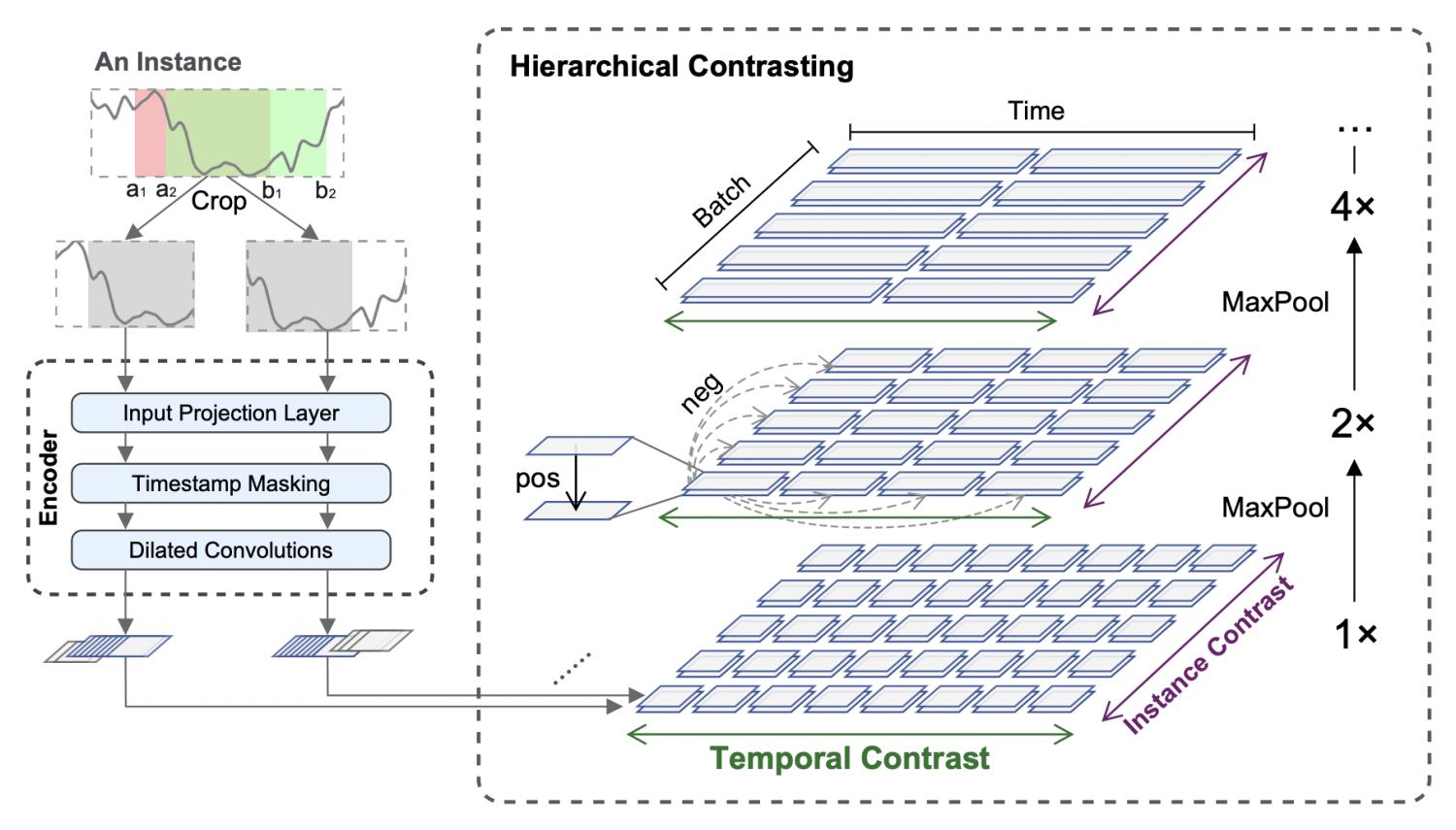
TS2Vec是一种时间序列表示学习方法,核心思路是无监督表示学习,通过数据增强的方式构造正样本对,通过对比学习的优化目标让正样本对之间距离,负样本之间距离远。本文的核心点主要在两个方面,第一个是针对时间序列特点的正样本对构造和对比学习优化目标的设计,第二个是结合时间序列特点提出的层次对比学习。
在数据构造上,本文提出了适合时间序列的正样本对构造方法:Contextual Consistency。Contextual Consistency的核心思路是,两个不同增强视图的时间序列,在相同时间步的表示距离更接近。文中提出两种构造Contextual Consistency正样本对的方法。第一种是Timestamp Masking,在经过全连接后,随机mask一些时间步的向量表示,再通过CNN提取每个时间步的表示。第二种是Random Cropping,选取有公共部分的两个子序列互为正样本对。这两种方法都是让相同时间步的向量表示更近。
TS2Vec的另一个核心点是层次对比学习。对于两个互为正样本对的时间序列,最开始通过CNN生成每个时间步向量表示,然后循环使用maxpooling在时间维度上进行聚合,文中使用的聚合窗口为2。每次聚合后,都计算对应时间步聚合向量的距离,让相同时间步距离近。聚合的粒度不断变粗,最终聚合成整个时间序列粒度,逐渐实现instance-level的表示学习。
CoST: Contrastive Learning of Disentangled Seasonal-Trend Representations for Time Series Forecasting(ICLR 2022)
CoST巧妙将分解学习的思路,以及在NLP、CV表示学习中的对比学习方法,应用到了时间序列预测问题上,取得了非常好的效果。
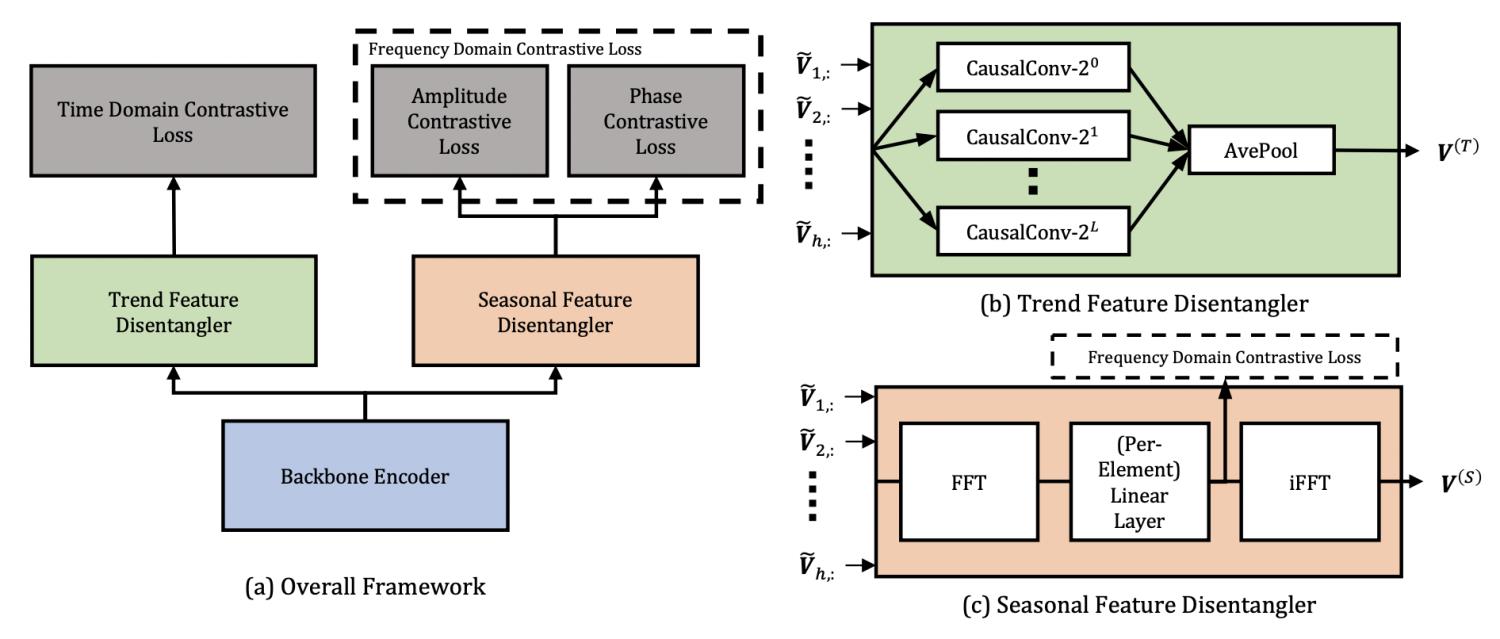
一般我们会把时间序列拆分成3个因素:趋势项(Trend)、季节项(Seasonal)、噪声。其中,趋势项和季节项决定了无噪声的时间序列,加上噪声后得到最终的时间序列,噪声部分是不可预估的。CoST基于分解学习的思想,通过观测数据学习到趋势项和季节项两个解耦的特征表示。为了应对噪声在这个过程中带来的干扰,CoST利用对比学习的方法,在一个时间序列不同的变换形态上进行学习。
对于Trend部分的特征表示,CoST提出 mixture of auto-regressive experts方法。对于一个长度为h的历史观测时间序列,使用L = log2(h/2)个不同尺寸的一维因果卷积生成多个特征图,每个卷积的尺寸是2的指数次方。最后通过pooling的方法将所有表示进行融合。
对于Seasonal部分的表示学习,CoST将问题转换到频域,通过离散傅里叶变换,将原始的时间序列从时域转换到频域,从原来的每个时刻t的序列值,转换成了整个序列不同频率的强度。接下来,对于每个频率使用一个全连接进行映射。最后,再通过逆傅里叶变换将其转换为时域。
Non-stationary Transformers: Rethinking the Stationarity in Time Series Forecasting(NIPS 2022)
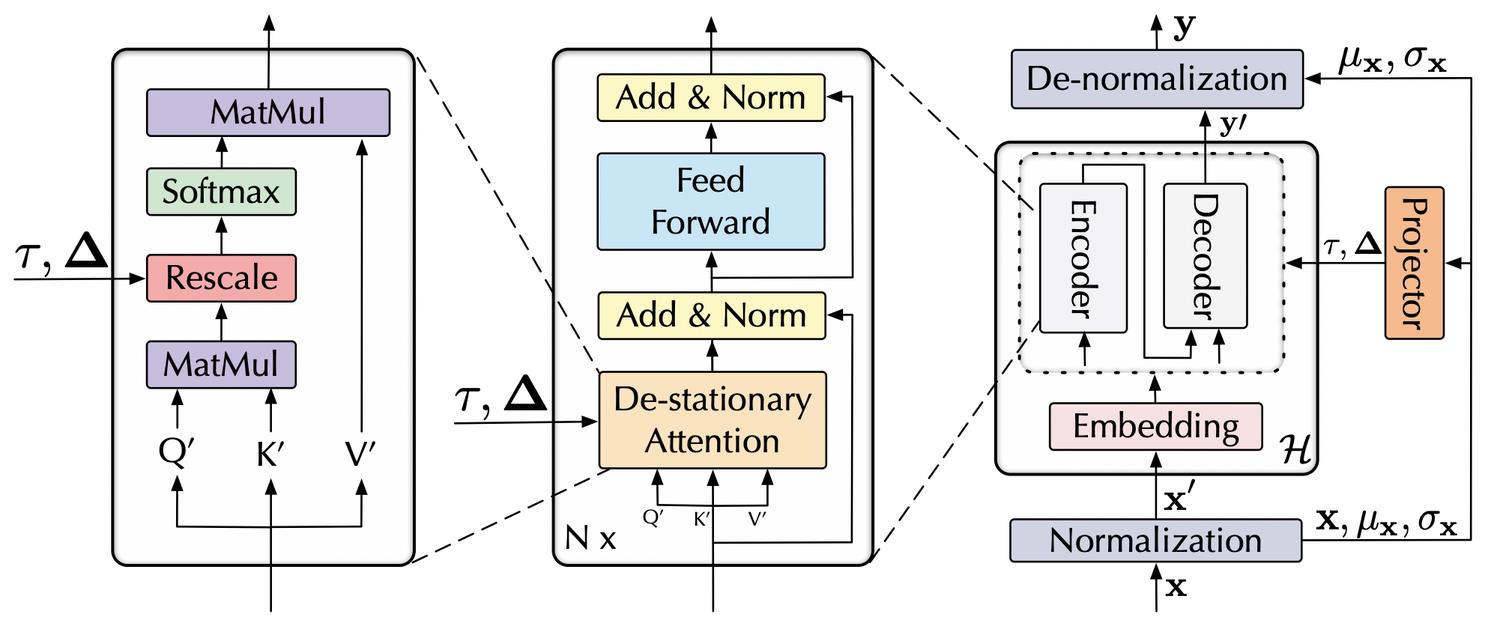
本文提出一种对Transformer模型的改造来让其适用于不平稳的时间序列预测问题。
时间序列的不平稳性是一个比较难处理,且真实世界中很常见的问题。时间序列的不平稳性指的是随着时间的变化,观测值的均值、方差等统计量发生变化。一般对于不平稳时间序列的处理方法是使用z-score normalization归一化。但是这样处理的弊端是让数据损失了一些个性化的信息,导致不同序列的Transformer中的attention矩阵趋同。本文重点解决的是,如何实现序列平稳化的同时,不让个性化信号损失对Transformer的拟合带来负向影响。
为了让Transformer能够直接从平稳化前的时间序列中学习attention pattern,本文提出了De-stationary Attention。利用MLP拟合平稳化前的的关键信息,实现这部分信息的补充,让模型即使拟合的是平稳化后的结果,也能在计算attention的时候考虑到平稳化前的信息。
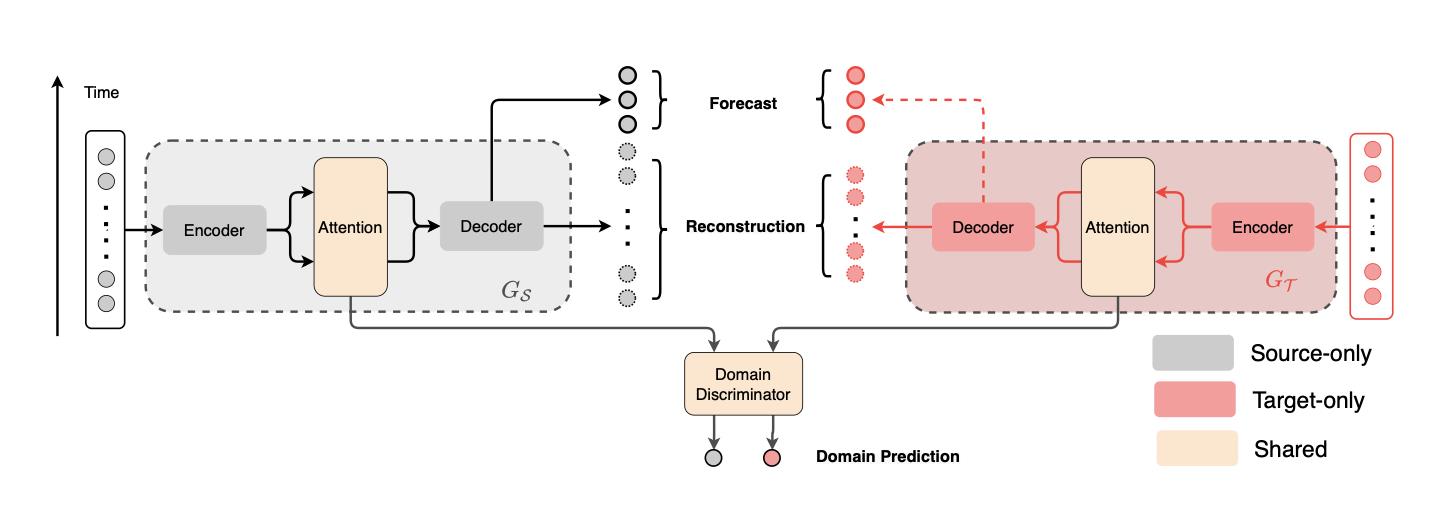
Domain Adaptation for Time Series Forecasting via Attention Sharing(ICML 2022)
这篇文章使用Domain Adaptation解决小样本场景下时间序列预测问题。本文的一个核心假设是:在基于attention的时间序列预测模型中(如Transformer),不同域的时间序列数据在与猜测当前值时,计算历史序列attention的key和query是可迁移的。这个假设的确非常合理,比如两个域的数据周期性不同,但是计算attention score时都是去寻找局部信息和历史序列的哪些pattern最相似,这个规律在不同域是可迁移的,也正是本文所利用的核心点。因此,本文后续就围绕着在基于attention的时许预估模型中,如何对齐source domain和target domain的query和key展开。
Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting(ICLR 2022)
在长周期的时间序列预测问题中,如何平衡运算复杂度以及缩短两个时间点之间的交互距离一直是研究的焦点(如下表为各个模型的运算复杂度及两点最长路径)。RNN、CNN这种模型对于输入长度为L的序列,两个时间点的最长路径为L,在长周期中节点之间信息交互比较困难。而Transformer引入了Attention机制,让两两节点之间可以直接交互,但是提升了时间复杂度。
本文提出了一种树形结构的Transformer,用于解决长周期时间序列预测问题。从下到上,时间序列的粒度逐渐变粗。最底层为原始输入的时间序列,上层为使用卷积聚合得到的粗粒度序列。每个节点和3种节点做attention:该节点的子节点、该节点的相邻邻居节点、该节点的父节点。通过这种方式,任何两个节点之间都可以直接交互,并且时间复杂度大幅降低。
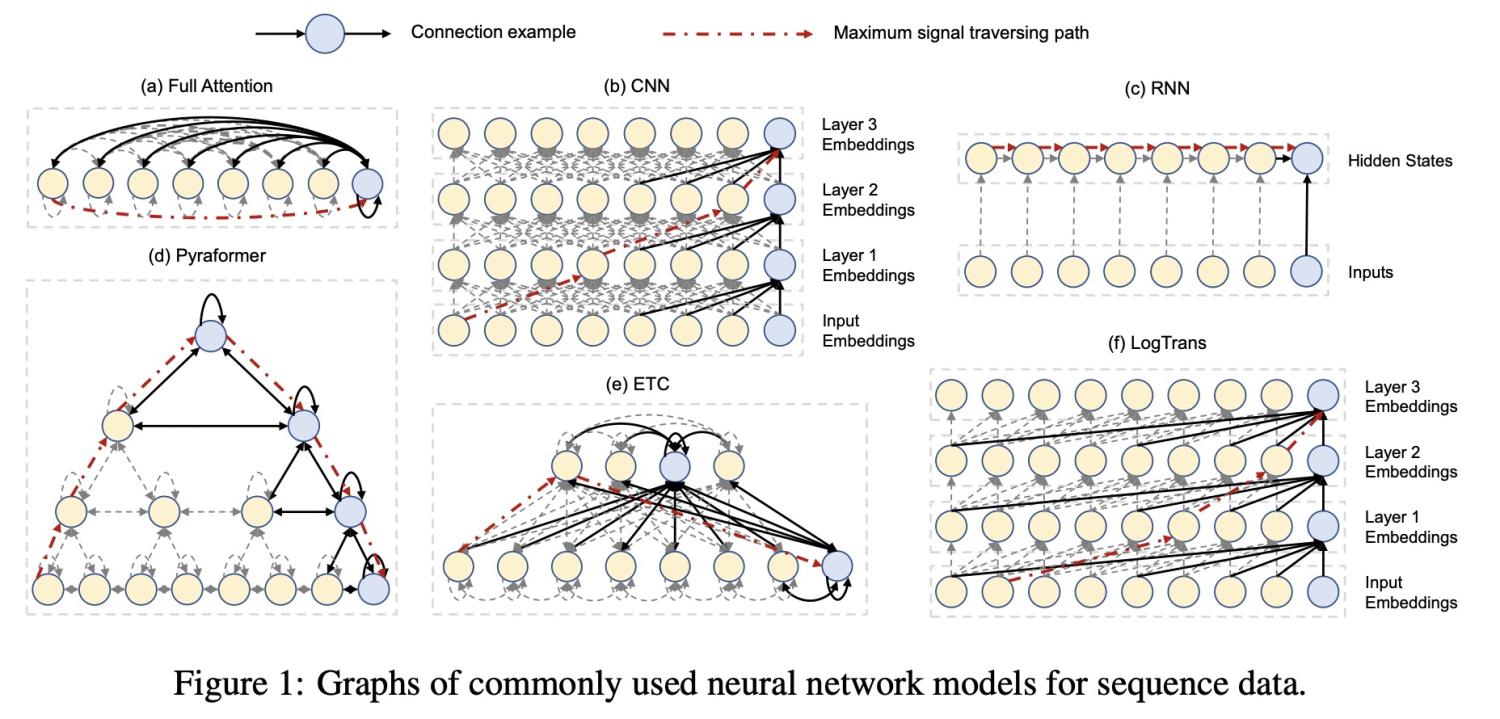
FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting(2022)
FEDformer的主要思路也是将Transformemr和 seasonal-trend decomposition结合起来。使用普通的Transformer进行时间序列预测时,经常会出现预测的数据分布和真实分布存在比较大的gap。这主要是由于Transformer在进行预测每个时间点是独立的利用attention预测的,这个过程中可能会忽略时间序列整体的属性。为了解决这个问题,本文采用了两种方法,一种是在基础的Transformer中引入 seasonal-trend decomposition,另一种是引入傅里叶变换,在频域使用Transformer,帮助Transformer更好的学习全局信息。
FEDformer的核心模块是傅里叶变换模块和时序分解模块。傅里叶变换模块将输入的时间序列从时域转换到频域,然后将Transformer中的Q、K、V替换成傅里叶变换后的频域信息,在频域中进行Transformer操作。
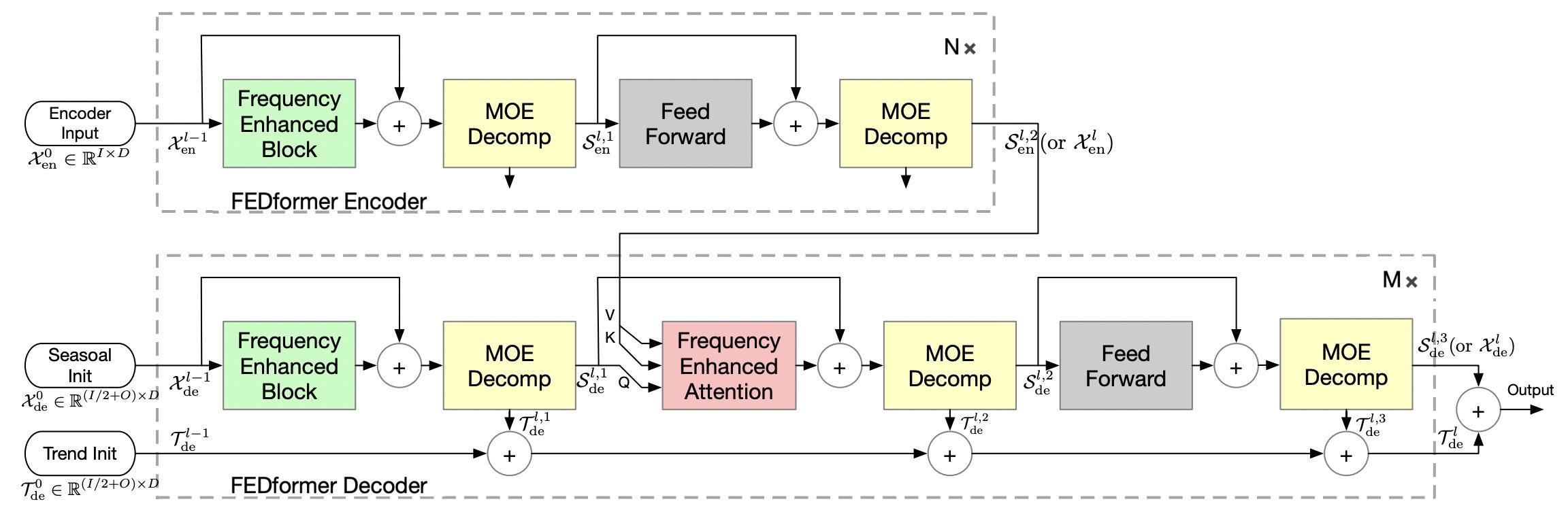
Expressing Multivariate Time Series as Graphs with Time Series Attention Transformer(IJCAI 2022)
这篇工作的核心主要包括多变量序列构图和Transformer改进两个部分。
多变来那个序列构图利用SMD对原时间序列进行分解,根据SMD提取出的特征信息进行构图。通过SMD可以把原始序列拆分成多个子序列,这些子序列会作为后续建模的重要特征。第二个核心点是Transformer模型的应用。首先对于每个节点使用一个RNN生成embedding,通过RNN的时序建模能力取代position embedding,增强Transformer对序列中各个点位置关系的感知。本文将self-attention模块的计算方法修改为如下公式,同时考虑节点序列信息、节点间关系信息、图结构信息。
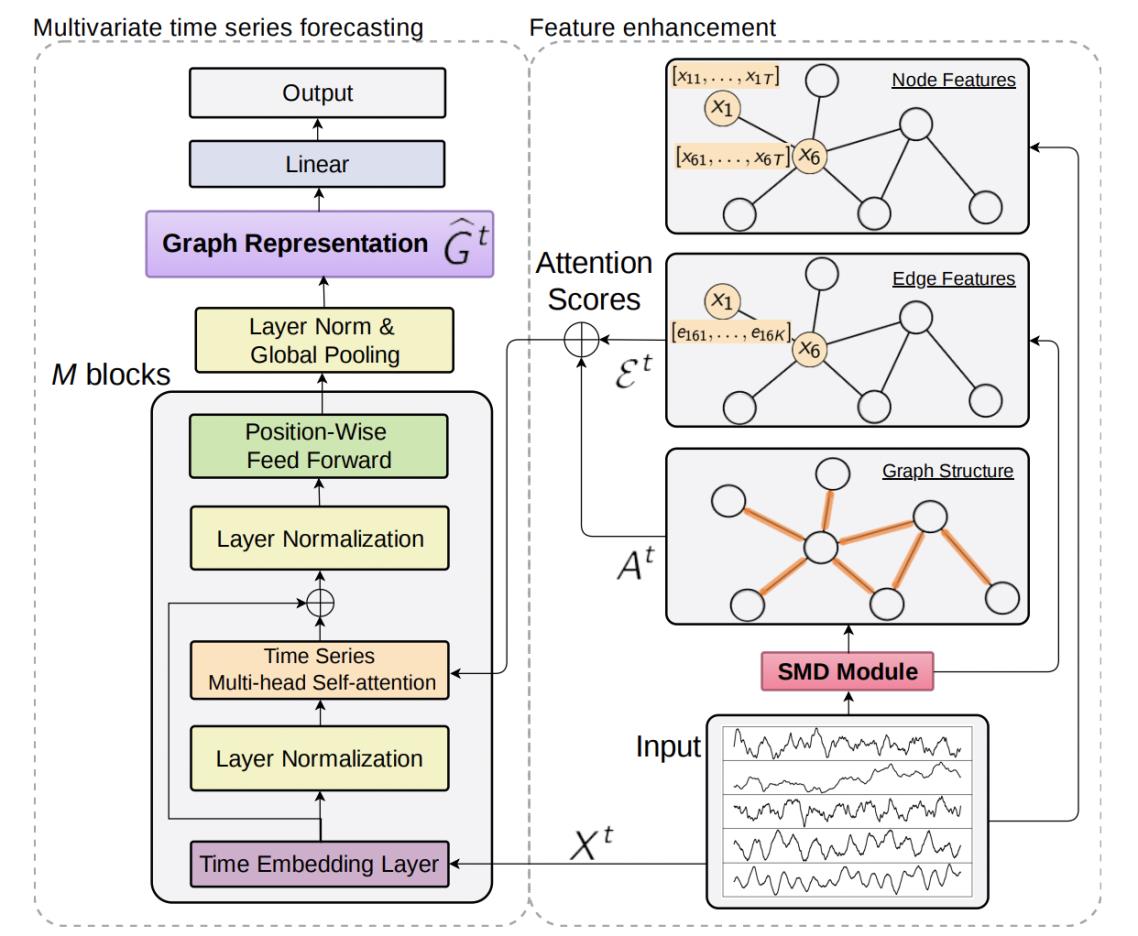
Self-Supervised Contrastive Pre-Training For Time Series via Time-Frequency Consistency(2022)
本文的核心思路是,无监督预训练的核心是将先验引入模型学习强泛化性的参数,本文引入的先验是同一个时间序列在频域的表示和在时域的表示应该相近,以此为目标利用对比学习进行预训练。
NLP、CV领域的预训练方法,在时间序列中并不完全适用。不同数据集的频率、周期性、平稳性差异都很大。以往的预训练方法现在一些数据集pretrain再在目标数据集finetune。如果预训练的数据集和finetune数据集的时间序列相关特征差异很大,就会出现迁移效果不好的问题。
为了解决这个问题,本文找到了一种不论在什么样的时间序列数据集中都存在的规律,那就是一个时间序列的频域表示和时域表示应该相似。在时间序列中,时域和频域就是同一个时间序列的两种表示,因此如果存在一个时域频域共享的隐空间,二者的表示应该是相同的,在任何时间序列数据中都应该有相同的规律。
基于上述思考,本文提出了Time-Frequency Consistency (TF-C)的核心架构,以对比学习为基础,让时域的频域的序列表示尽可能接近。
以上是关于过去一年有哪些值得关注的时间序列工作?的主要内容,如果未能解决你的问题,请参考以下文章