elstaticsearch 入门(五)
Posted jiataoq
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elstaticsearch 入门(五)相关的知识,希望对你有一定的参考价值。
它是一个面向文档的数据库,既然是数据库那就来说一下它和数据库的对应关系:
关系数据库 ? 数据库 ? 表 ? 行 ? 列(Columns)
Elasticsearch(非关系型数据库) ? 索引(index) ? 类型(type) ? 文档 (document)? 字段(Fields)
Elasticsearch是如何做到快速索引的呢?
Elasticsearch采用了倒排索引的方式,这种方式比传统的关系型数据库中采用的B-Tree和B+Tree要快。
倒排索引:
例如,假设我们有两个文档,每个文档的 content 域包含如下内容:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
为了创建倒排索引,我们首先将每个文档的 content 域拆分成单独的 词(我们称它为 词条 或 tokens ),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。结果如下所示:

假设doc1的ID为1,doc2的ID为2,这个ID是Elasticsearch自建的文档ID,那么经过上面的倒排索引我们就可以得到一个对应关系:
Term Posting List
The 【1】
quick 【1,2】
brown 【1,2】
fox 【1】
....... ......
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:
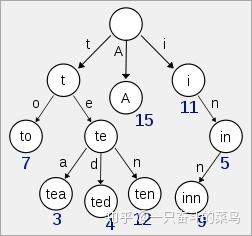
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
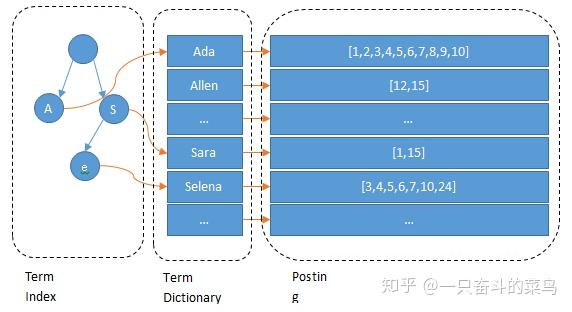
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
elasticsearch里除了上面说到用FST压缩term index外,对posting list也有压缩技巧,针对posting list的压缩,采用增量编码压缩,将大数变小数,按字节存储。
posting list中的ID都是有序的,这也是为了提高搜索性能,下图清晰的展示了压缩原理:
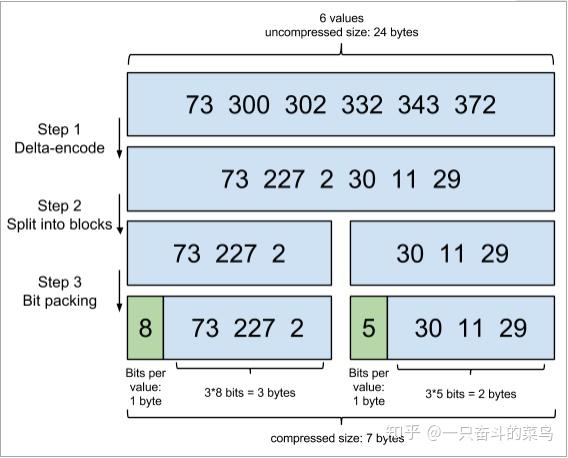
原理就是通过增量,将原来的大数变成小数仅存储增量值,再精打细算按bit排好队,最后通过字节存储,而不是大大咧咧的尽管是2也是用int(4个字节)来存储。
综上所述,Elasticsearch提高检索效率的方式为:
1、将磁盘里的东西尽量搬到内存,减少磁盘随机读取次数;
2、结合各种奇特的压缩算法,用及其苛刻的态度使用内存。
Elasticsearch的写
Elasticsearch采用多Shard方式,通过配置routing规则将数据分成多个数据子集,每个数据子集提供独立的索引和搜索功能。当写入文档的时候,根据routing规则,将文档发送给特定Shard中建立索引。这样就能实现分布式了。
此外,Elasticsearch整体架构上采用了一主多副的方式:
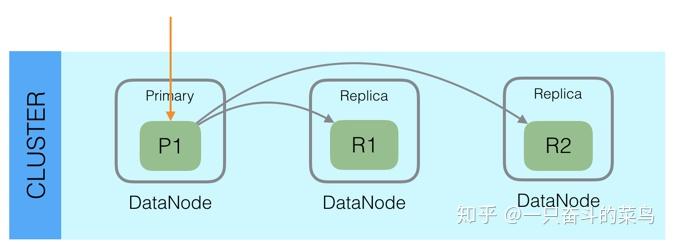
每个Index由多个Shard组成,每个Shard有一个主节点和多个副本节点,副本个数可配。但每次写入的时候,写入请求会先根据_routing规则选择发给哪个Shard,Index Request中可以设置使用哪个Filed的值作为路由参数,如果没有设置,则使用Mapping中的配置,如果mapping中也没有配置,则使用_id作为路由参数,然后通过_routing的Hash值选择出Shard(在OperationRouting类中),最后从集群的Meta中找出出该Shard的Primary节点。
请求接着会发送给Primary Shard,在Primary Shard上执行成功后,再从Primary Shard上将请求同时发送给多个Replica Shard,请求在多个Replica Shard上执行成功并返回给Primary Shard后,写入请求执行成功,返回结果给客户端。
这种模式下,写入操作的延时就等于latency = Latency(Primary Write) + Max(Replicas Write)。只要有副本在,写入延时最小也是两次单Shard的写入时延总和,写入效率会较低,但是这样的好处也很明显,避免写入后,单机或磁盘故障导致数据丢失,在数据重要性和性能方面,一般都是优先选择数据,除非一些允许丢数据的特殊场景。
采用多个副本后,避免了单机或磁盘故障发生时,对已经持久化后的数据造成损害,但是Elasticsearch里为了减少磁盘IO保证读写性能,一般是每隔一段时间(比如5分钟)才会把Lucene的Segment写入磁盘持久化,对于写入内存,但还未Flush到磁盘的Lucene数据,如果发生机器宕机或者掉电,那么内存中的数据也会丢失,这时候如何保证?
对于这种问题,Elasticsearch学习了数据库中的处理方式:增加CommitLog模块,Elasticsearch中叫TransLog。
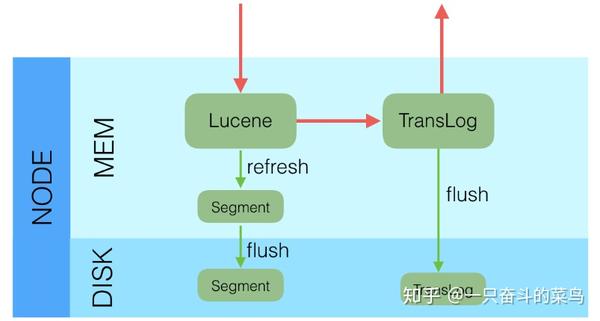
在每一个Shard中,写入流程分为两部分,先写入Lucene,再写入TransLog。
写入请求到达Shard后,先写Lucene文件,创建好索引,此时索引还在内存里面,接着去写TransLog,写完TransLog后,刷新TransLog数据到磁盘上,写磁盘成功后,请求返回给用户。这里有几个关键点,一是和数据库不同,数据库是先写CommitLog,然后再写内存,而Elasticsearch是先写内存,最后才写TransLog,一种可能的原因是Lucene的内存写入会有很复杂的逻辑,很容易失败,比如分词,字段长度超过限制等,比较重,为了避免TransLog中有大量无效记录,减少recover的复杂度和提高速度,所以就把写Lucene放在了最前面。二是写Lucene内存后,并不是可被搜索的,需要通过Refresh把内存的对象转成完整的Segment后,然后再次reopen后才能被搜索,一般这个时间设置为1秒钟,导致写入Elasticsearch的文档,最快要1秒钟才可被从搜索到,所以Elasticsearch在搜索方面是NRT(Near Real Time)近实时的系统。三是当Elasticsearch作为NoSQL数据库时,查询方式是GetById,这种查询可以直接从TransLog中查询,这时候就成了RT(Real Time)实时系统。四是每隔一段比较长的时间,比如30分钟后,Lucene会把内存中生成的新Segment刷新到磁盘上,刷新后索引文件已经持久化了,历史的TransLog就没用了,会清空掉旧的TransLog。
上面介绍了Elasticsearch在写入时的两个关键模块,Replica和TransLog,接下来,我们看一下Update流程:
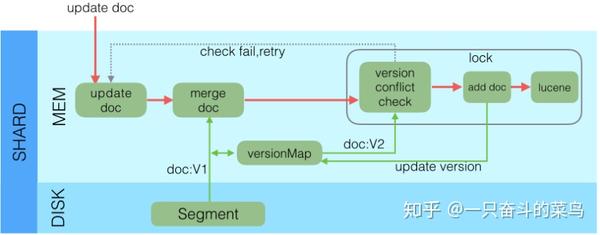
Lucene中不支持部分字段的Update,所以需要在Elasticsearch中实现该功能,具体流程如下:
- 收到Update请求后,从Segment或者TransLog中读取同id的完整Doc,记录版本号为V1。
- 将版本V1的全量Doc和请求中的部分字段Doc合并为一个完整的Doc,同时更新内存中的VersionMap。获取到完整Doc后,Update请求就变成了Index请求。
- 加锁。
- 再次从versionMap中读取该id的最大版本号V2,如果versionMap中没有,则从Segment或者TransLog中读取,这里基本都会从versionMap中获取到。
- 检查版本是否冲突(V1==V2),如果冲突,则回退到开始的“Update doc”阶段,重新执行。如果不冲突,则执行最新的Add请求。
- 在Index Doc阶段,首先将Version + 1得到V3,再将Doc加入到Lucene中去,Lucene中会先删同id下的已存在doc id,然后再增加新Doc。写入Lucene成功后,将当前V3更新到versionMap中。
- 释放锁,部分更新的流程就结束了。
转自 https://zhuanlan.zhihu.com/p/48429223
以上是关于elstaticsearch 入门(五)的主要内容,如果未能解决你的问题,请参考以下文章