C-C 法混沌时间序列 Matlab与Python代码
Posted Walker@Bruce Lee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C-C 法混沌时间序列 Matlab与Python代码相关的知识,希望对你有一定的参考价值。
混沌时间序列
简单的来讲,就是处于混沌系统的时间序列,这是可以预测的。
理论上来说,一个非线性复杂的现实环境中,时间序列是不可预测的,或则说预测的结果是不可信的。
但在混沌系统,由于吸引子结构特性的存在,将一个混沌时间序列进行重构之后,恢复到它应有的系统中就是可以预测的,这一点至关重要。
这与其他不了解该理论做单独的时间序列预测有着本质上的区别,因为我们知道大都数现在的时间序列预测采用传统方法过于线性,预测不准确,而采用非线性的方法如机器学习、深度学习等,调参复杂,可解释性不强。
且受限于时间窗口的大小等不可控的因素存在,没有一个统一的处理方法,混沌时间序列相空间重构则可以改变此种情况。
时间序列重构方法:导数重构法和坐标延迟法。本质上是将一维的时间序列来延迟时间时间τ,并重构为m维的向量
X(i)=(x(i),x(i+τ),...,x(i+(m−1)τ))
其中,1⩽i⩽M,M=N−(m−1)τ
Takens嵌入定理:对于无限长,无噪声的,dˊ维混沌吸引子的一维标量时间序列x(i):1⩽i⩽n都可以找到在拓扑不变的意义下找到一个d维的嵌入相空间, 只要维数d满足d≥2dˊ+1,于是根据Takens定理,我们就可以将一维的混沌时间序列重构为一个与原动力系统在拓扑意义下一样的相空间。
相空间重构
关键求解两个量
延迟时间τ
嵌入维数m
两种思路的解法
第一种:τ与m无关
延迟时间τ的求解
自相关法
优点计算简单
缺点:只是邻近的线性相关判断,在非线性领域适应能力不强
平均位移法
复相关法
互信息法:信息论的熵来求解
嵌入维数m的求解
几何不变量方法:延迟时间τ确定后逐渐增加维数m,直到他们停止变化-->根据Takens 嵌入定理,几何不变量具有吸引子的几何性质,当维数超过最小嵌入维数时,几何性质发生变化,导致与嵌入维数无关。基于此理论,可以选择吸引子的几何不变量停止变化时的嵌入维数 �
虚假最近方法
Cao方法
原时间序列经过时间延迟之后可以作为独立的坐标来使用
第二种:τ与m相关
C-C法:使用关联积分估计出延迟时间和嵌入维数
C-C法适用于较小的数据集并且计算要求较低
关联维数用于刻画吸引子
关联积分
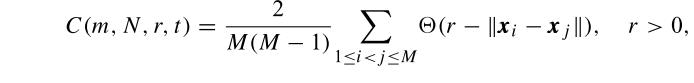
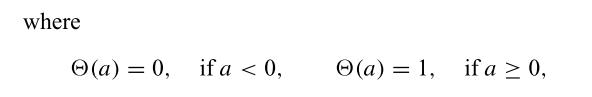
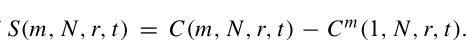
S用来刻画非线性时间序列的相关性
m取2到5
r为sigma/2 到2sigma
C-C法相空间重构代码
Matlab
function [Smean,Sdeltmean,Scor,tau,tw]=CCMethod(data,max_d)
% 本函数用于求延迟时间tau和时间窗口tw
% data:输入时间序列
% max_d:最大时间延迟
% Smean,Sdeltmean,Scor为返回值
% tau:计算得到的延迟时间
% tw:时间窗口
N=length(data);
%时间序列的长度
Smean=zeros(1,max_d);
%初始化矩阵
Scmean=zeros(1,max_d);
Scor=zeros(1,max_d);
sigma=std(data);
%计算序列的标准差
% 计算Smean,Sdeltmean,Scor
for t=1:max_d
S=zeros(4,4);
Sdelt=zeros(1,4);
for m=2:5
for j=1:4
r=sigma*j/2;
Xdt=disjoint(data,t);
% 将时间序列data分解成t个不相交的时间序列
s=0;
for tau=1:t
N_t=floor(N/t);
% 分成的子序列长度
Y=Xdt(:,tau);
% 每个子序列
%计算C(1,N/t,r,t),相当于调用Cs1(tau)=correlation_integral1(Y,r)
Cs1(tau)=0;
for ii=1:N_t-1
for jj=ii+1:N_t
d1=abs(Y(ii)-Y(jj));
% 计算状态空间中每两点之间的距离,取无穷范数
if r>d1
Cs1(tau)=Cs1(tau)+1;
end
end
end
Cs1(tau)=2*Cs1(tau)/(N_t*(N_t-1));
Z=reconstitution(Y,m,1);
% 相空间重构
M=N_t-(m-1);
Cs(tau)=correlation_integral(Z,M,r);
% 计算C(m,N/t,r,t)
s=s+(Cs(tau)-Cs1(tau)^m);
% 对t个不相关的时间序列求和
end
S(m-1,j)=s/tau;
end
Sdelt(m-1)=max(S(m-1,:))-min(S(m-1,:));
% 差量计算
end
Smean(t)=mean(mean(S));
% 计算平均值
Sdeltmean(t)=mean(Sdelt);
% 计算平均值
Scor(t)=abs(Smean(t))+Sdeltmean(t);
end
% 寻找时间延迟tau:即Sdeltmean第一个极小值点对应的t
for i=2:length(Sdeltmean)-1
if Sdeltmean(i)<Sdeltmean(i-1)&Sdeltmean(i)<Sdeltmean(i+1)
tau=i;
break;
end
end
% 寻找时间窗口tw:即Scor最小值对应的t
for i=1:length(Scor)
if Scor(i)==min(Scor)
tw=i;
break;
end
end
%%
%时间序列分解
function Data=disjoint(data,t)
% 此函数用于将时间序列分解成t个不相交的时间序列
% data:输入时间序列
% t:延迟,也是不相交时间序列的个数
% Data:返回分解后的t个不相交的时间序列
N=length(data);
%data的长度
for i=1:t
for j=1:(N/t)
Data(j,i)=data(i+(j-1)*t);
end
end
%%
%相空间重构
function Data=reconstitution(data,m,tau)
%该函数用来重构相空间
% m:嵌入空间维数
% tau:时间延迟
% data:输入时间序列
% Data:输出,是m*n维矩阵
%m=tw/tau+1
N=length(data);
% N为时间序列长度
M=N-(m-1)*tau;
%相空间中点的个数
Data=zeros(m,M);
for j=1:M
for i=1:m
%相空间重构
Data(i,j)=data((i-1)*tau+j);
end
end
%关联积分计算
function C_I=correlation_integral(X,M,r)
%该函数用来计算关联积分
%C_I:关联积分的返回值
%X:重构的相空间矢量,是一个m*M的矩阵
%M::M是重构的m维相空间中的总点数
%r:Heaviside 函数中的搜索半径
sum_H=0;
for i=1:M-1
for j=i+1:M
d=norm((X(:,i)-X(:,j)),inf);
%计算相空间中每两点之间的距离,其中NORM(V,inf) = max(abs(V)).
if r>d
%sita=heaviside(r,d);%计算Heaviside 函数之值n
sum_H=sum_H+1;
end
end
end
C_I=2*sum_H/(M*(M-1));%关联积分的值上述代码要求,有一段时间序列data,max-d 可设置为100
在matlab程序窗口输入:[Smean,Sdeltmean,Scor,tau,tw]=CCMethod(data,max_d)即可返回相应的结果如延迟时间tau, 时间窗口tw
根据(m-1)*tau = tw-->m = tw/tau +1
最后根据Data=reconstitution(data,m,tau)返回重构后的数据矩阵
运行时间50.3281

m = tw/tau +1 = 6(超出了设定的值范围2:5,可直接假定为最大值m = 5)
python版
import numpy as np
import time
import pandas as pd
def CCMethod(data, max_d):
"""
该函数用于计算延迟时间tau和时间窗口tw
data:输入的时间序列-->1维向量
max_d:最大延迟时间
"""
N = len(data)
S_mean = np.zeros([1, max_d]) # 重构的每个维度的均值初始化
Sdelta_mean = np.zeros([1, max_d])
Scor = np.zeros([1, max_d])
sigma = np.std(data) # 标准差
r_division = list(range(1,5))
m_list = list(range(2,6))
# r的取值是自己定的
# m-->[2,5]
# r-->[sigma/2, 2sigma]
# 将sigma拆分成4等分:[sigma/2,sigma,3sigma/2,2sigma]=sigma/2*[1,2,3,4]
for t in range(1, max_d+1):#1到100
S = np.zeros([len(m_list), len(r_division)]) # (4,4)
S_delta = np.zeros([1, len(m_list)]) # (1,4)
for m in m_list:#2到5
for r_d in r_division:#1到4
r = sigma/2 * r_d
# 分解成t个不相交的时间序列
sub_data = subdivide(data, t) # 对的(int(N/t), t)
s = 0
Cs1 = np.zeros([t]) # t个
# Cs1 = np.zeros([t+1])
Cs = np.zeros([t])
# Cs = np.zeros([t+1])
# 索引为t+1
# for tau in range(t):# t=0-->1,t=4-->5
for tau in range(1, t+1): # 1,..,t
N_t = int(N/t)
# Y = sub_data[:, tau]
Y = sub_data[:, tau-1] # 索引值为tau-1-->(N_t, 1)
for i in range(N_t-1):
for j in range(i, N_t):
d1 = np.abs(Y[i] -Y[j])
if r>d1:
# Cs1[tau] += 1
Cs1[tau-1] += 1
# Cs1[tau] = 2*Cs1[tau] / (N_t*(N_t-1)) # 延迟为tau的关联积分
Cs1[tau-1] = 2*Cs1[tau-1] / (N_t*(N_t-1))
Z = reconstruction(Y,m,1) # (m, N_t-(m-1))
# 相空间重构
M = N_t-(m-1)
# print(M)
# 计算C(m, N/t, r, t)
# Cs[tau] = correlation_integral(Z, M, r)
Cs[tau-1] = correlation_integral(Z, M, r)
# 对t个不相关的时间序列求和
s += Cs[tau-1] - Cs1[tau-1]**m
# 计算每个m和r下的统计量s(m,r,t)
# 对应的索引m-2, r_d-1
S[m-2, r_d-1] = s/tau
# 差量计算
S_delta[0,m-2] = max(S[m-2,:])-min(S[m-2,:])
# 计算平均值,索引其实是t-1
# S_mean[1, t] = np.mean(np.mean(S_delta))
S_mean[0, t-1] = np.mean(np.mean(S))
# Sdelta_mean[1, t]=np.mean(S_delta)
Sdelta_mean[0, t-1]=np.mean(S_delta)
# Scor[1, t] = abs(S_mean[1, t]+Sdelta_mean[1, t])
Scor[0, t-1] = np.abs(S_mean[0, t-1]+Sdelta_mean[0, t-1])
return Sdelta_mean, Scor
# 拆分t个不相交的时间序列
def subdivide(data, t): # t=t+1
"""
将长度为n的时间序列拆分成n/t * t的矩阵,
"""
# t = t+1
n = len(data)
Data = np.zeros([int(n/t), t])
for i in range(t):
assert t != 0
for j in range(int(n/t)):
Data[j, i] = data[i+ j*t]
return Data
# 相空间重构
def reconstruction(data, m, tau):
"""
该函数用来重构相空间
m:嵌入维数
tau:时间延迟
return:Data-->(m,n)
"""
n = len(data)
M = n - (m-1) * tau
Data = np.zeros([m, M])
for j in range(M):
for i in range(m):
Data[i, j] = data[i*tau+j]
return Data
def correlation_integral(Z, M , r):
"""
该函数用来计算关联积分
return:C_I-->关联积分值
"""
sum_H = 0
for i in range(M-1):
for j in range(i+1, M):
# 求范数,无穷大
d = np.linalg.norm(Z[:, i]-Z[:, j],ord=np.inf)
if r>d:
sum_H += 1
C_I = 2*sum_H/(M*(M-1))
return C_I
def get_tau(Sdelta_mean): # 有可能是局部最小值,相当于第一次找到
Sdelta_mean = Sdelta_mean.reshape(-1)
for i in range(1, len(Sdelta_mean)-1):
if Sdelta_mean[i] < Sdelta_mean[i-1] and Sdelta_mean[i]<Sdelta_mean[i+1]:
tau = i
return tau+1
else:
continue
def get_tw(Scor):
Scor = Scor.reshape(-1)
return np.argmin(Scor)+1
def get_embedding_m(tau, t_w):
assert tau != 0
return int(t_w / tau) + 1
if __name__ == "__main__":
data = pd.read_csv('lorenz.csv',header=None)
data = data[1].values[3000:7000]
max_d = 100
start = time.time()
Sdelta_mean, Scor = CCMethod(data, max_d)
print(f"统计量计算用时:time.time()-start")
tau = get_tau(Sdelta_mean)
t_w = get_tw(Scor)
m = get_embedding_m(tau, t_w)
print(f"延迟时间tau:tau,时间窗口tw:t_w,嵌入维数m:m")max_d的维度是可以调的, 由于计算是线性增加,可减小相应的值

可以看到matlab的计算速度远远高于python,且计算结果也有一定的差距,但python最后计算的结果是较为准确的
计算速度方面的原因在于,matlab在矩阵向量等科学计算独有的优势(直接编译)
结果方面的差距尚且不明
参考
以上是关于C-C 法混沌时间序列 Matlab与Python代码的主要内容,如果未能解决你的问题,请参考以下文章
优化算法混沌单纯形法算子布谷鸟搜索优化算法含Matlab源码 1193期
图像加密基于matlab logistic混沌图像加密与解密含Matlab源码 1216期