迁移学习
Posted missidiot
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了迁移学习相关的知识,希望对你有一定的参考价值。
十岁的小男孩
目录
背景
理论
实践
很感谢这位博主,他做了超级详细的关于迁移学习的归纳整理,从最新文章到可以上手的代码,应有尽有:Transfer Learning
经典论文:A Survey on Deep Transfer Learning
背景
吴恩达(Andrew Ng)曾说:迁移学习将会是继监督学习之后的下一个机器学习商业成功的驱动力。
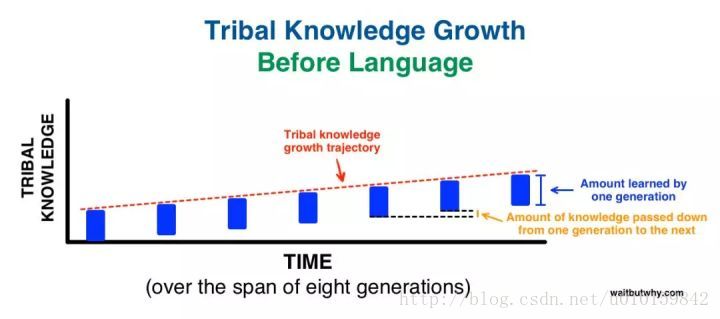
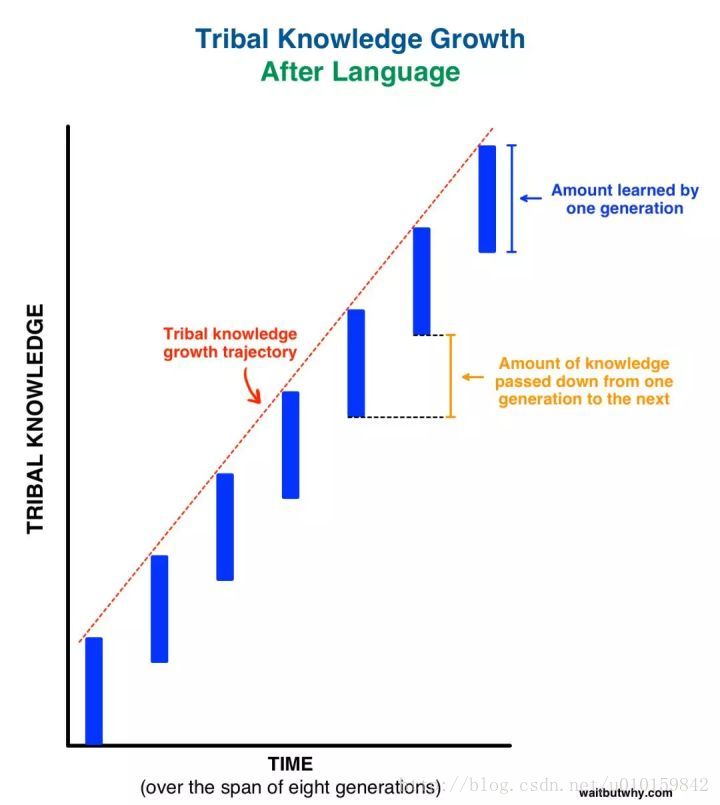
人类的语言使得代际之间的迁移学习变得可能,在语言出现之前,每一代能够教给下一代的东西极其有限,而有了语言,人类的知识得以爆炸性的增长。而随着现代科学的进步,每门学科都产生了很多术语,这些术语相当于抽象层次更高的表述,所需的学习时间也会变长,这使得童年这个文化概念得以产生。迁移学习的道理应用到现实生活中,还意味着教育和娱乐的区别。教育要有阐释,有背景,有对情境复杂性的分析,追求的是宽度,而当前娱乐式的知识传授,则只追求深度,从一个有趣的案例,一路衍生出看似深刻的道理,或者停留在事实本身,将知识变成一个个孤岛而不是网络。
回到技术问题。迁移学习相当于让神经网络有了语言,新一代的神经网络可以站在前人的基础上更进一步,而不必重新发明轮子。使用一个由他人预先训练好,应用在其他领域的网络,可以作为我们训练模型的起点。不论是有监督学习,无监督学习还是强化学习,迁移学习的概念都有广泛的应用。
迁移学习是什么?
迁移学习(Transfer Learning)是一种机器学习方法,是把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。
迁移学习过程
一般的迁移学习是这样的:训练好一个网络(我们称它为base network)------→把它的前n层复制到target network的前n层------→target network剩下的其他层随机初始化-------→开始训练target task。其中,在做backpropogate(反向传播)的时候,有两种方法可以选择:
(1)把迁移过来的这前n层frozen(冻结)起来,即在训练target task的时候,不改变这n层的值;
(2)不冻结这前n层,而是会不断调整它们的值,称为fine-tune(微调)。
这个主要取决于target数据集的大小和前n层的参数个数,如果target数据集很小,而参数个数很多,为了防止overfitting(过拟合),通常采用frozen方法;反之,采用fine-tune。
解决什么问题?
通常,源领域数据量充足,而目标领域数据量较小,这种场景就很适合做迁移学习,例如我们我们要对一个任务进行分类,但是此任务中数据不充足(目标域),然而却又大量的相关的训练数据(源域),但是此训练数据与所需进行的分类任务中的测试数据特征分布不同(例如语音情感识别中,一种语言的语音数据充足,然而所需进行分类任务的情感数据却极度缺乏),在这种情况下如果可以采用合适的迁移学习方法则可以大大提高样本不充足任务的分类识别结果。
-
复用现有知识域数据,已有的大量工作不至于完全丢弃;
-
不需要再去花费巨大代价去重新采集和标定庞大的新数据集,也有可能数据根本无法获取;
-
对于快速出现的新领域,能够快速迁移和应用,体现时效性优势。
既然上文说迁移学习是机器学习的一种方法,那么和传统的机器学习方法有什么区别?
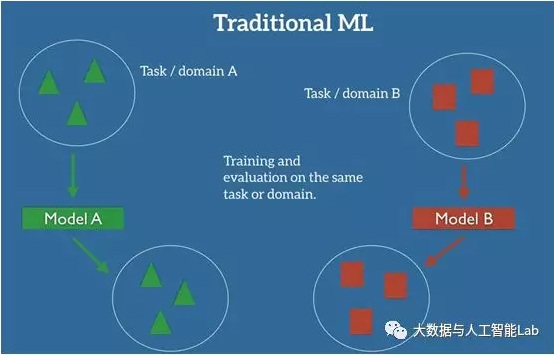
在机器学习的经典监督学习场景中,如果我们要针对一些任务和域 A 训练一个模型,我们会假设被提供了针对同一个域和任务的标签数据。如下图所示,其中我们的模型 A 在训练数据和测试数据中的域和任务都是一样的。
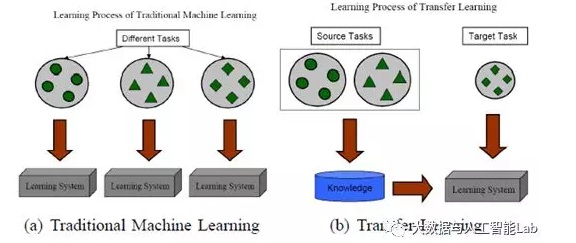
即使是跟迁移学习比较相似的多任务学习,多任务学习是对目标域和源域进行共同学习,而迁移学习主要是对通过对源域的学习解决目标域的识别任务。下图就展示了传统的机器学习方法与迁移学习的区别:
和传统的方法相比,迁移学习的另一个好处其可以做多任务目标的学习,传统的模型面对不同类型的任务,需要训练多个不同的模型。而有了迁移学习,可以先去实现简单的任务,将简单任务中的得到的知识应用到更难的问题上,从而解决标注数据缺少,标注不准确等问题。
what to transfer?
(1)Instance-based TL(样本迁移)
源领域(source domain)中的数据(data)的某一部分可以通过reweighting的方法重用,用于target domain的学习。尽管source domain数据不可以整个直接被用到target domain里,但是在source domain中还是找到一些可以重新被用到target domain中的数据。对它们调整权重,使它能与target domain中的数据匹配之后可以进行迁移。如下图,比如在这个例子中就是找到例子3,然后加重它的权值,这样在预测的时候它所占权重较大,预测也可以更准确。
instance reweighting(样本重新调整权重)和importance sampling(重要性采样)是instance-based TL里主要用到的两项技术。

(2)Feature-representation-transfer(特征迁移)
找到一些好的有代表性的特征,通过特征变换把source domain和target domain的特征变换到同样的空间,使得这个空间中source domain和target domain的数据具有相同的分布,然后进行传统的机器学习就可以了。通过source domain学习一个好的(good)的特征表示,把知识通过特征的形式进行编码,并从suorce domain传递到target domain,提升target domain任务效果。
可参考大佬博文:迁移学习理论与应用
3)Parameter-transfer(参数/模型迁移)
假设source tasks和target tasks之间共享一些参数,或者共享模型hyperparameters(超参数)的先验分布。这样把原来的模型迁移到新的domain时,也可以达到不错的精度。
下面这个项目感觉用到就是这个parameter-transfer:基于深度学习和迁移学习的识花实践。
(4)Relational-knowledge-transfer(关系迁移)
把相似的关系进行迁移,比如生物病毒传播到计算机病毒传播的迁移,比如师生关系到上司下属关系的迁移。相关领域之间的知识迁移,假设source domain和target domain中,数据(data)之间联系关系是相同的。
小结:前三类迁移学习方式都要求数据(data)独立同分布假设。同时,四类迁移学习方式都要求选择的sourc doma与target domain相关。下表给出了迁移内容的迁移学习分类:

怎么用?
下图说明了迁移学习的适用场景:
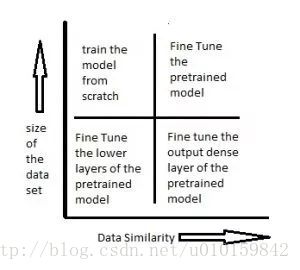
1)右下角场景,待训练的数据集较小,已训练的模型和当前任务相似。此时可以只是重新训练已有模型的靠近输出的几层,例如将ImageNet中输出层原来可以判别一万种输出的网络改的只能判别猫的品种,从而利用已有网络来做低层次的特征提取。
2)左下角场景,待训练的数据集较小,已训练的模型和当前任务场景差距较大。例如你有的已训练网络能识别出白天高速路上的违章车辆,你需要训练一个能识别出夜间违章车辆的模型,由于不管白天夜晚,交通规则是没有变化的,所以你需要将网络靠近输入的那几层重新训练,等到新的网络能够提取出夜间车辆的基本信息后,就可以借用已有的,在大数据集下训练好的神经网络来识别违章车辆,而不用等夜间违章的车辆的照片积累的足够多之后再重新训练。
3)左上角场景,待训练的数据集较大,已有的模型和新模型的数据差异度很高。此时应该做的是从头开始,重新训练。
4)右上角场景,待训练的数据集较大,已有模型的训练数据和现有的训练数据类似。此时应该使用原网络的结构,并保留每一层的节点权重,再逐层微调。
知识应该是开源的,欢迎斧正,[email protected]
以上是关于迁移学习的主要内容,如果未能解决你的问题,请参考以下文章