Zookeeper源码阅读 Server端Watcher
Posted gongcomeon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper源码阅读 Server端Watcher相关的知识,希望对你有一定的参考价值。
前言
前面一篇主要介绍了Watcher接口相关的接口和实体类,但是主要是zk客户端相关的代码,如前一篇开头所说,client需要把watcher注册到server端,这一篇分析下server端的watcher。
主要分析Watchmanager类。
Watchmanager
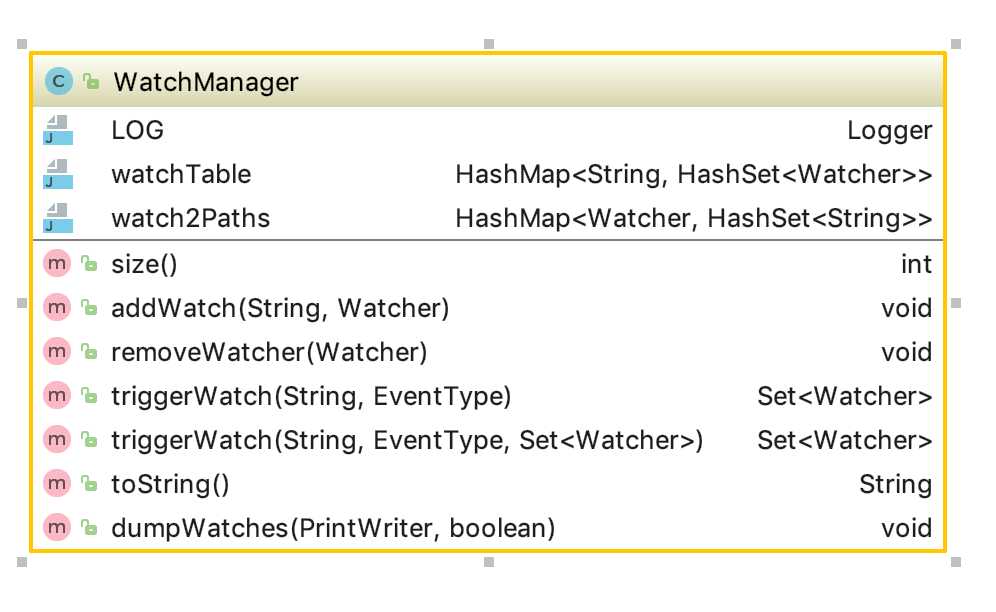
这是WatchManager的类图介绍。来看看代码:
/**
* This class manages watches. It allows watches to be associated with a string
* and removes watchers and their watches in addition to managing triggers.
*/
//如注释所言,这个类主要负责管理watcher
public class WatchManager {
private static final Logger LOG = LoggerFactory.getLogger(WatchManager.class);
//路径->watcher的映射
private final HashMap<String, HashSet<Watcher>> watchTable =
new HashMap<String, HashSet<Watcher>>();
//watcher->路径的映射
private final HashMap<Watcher, HashSet<String>> watch2Paths =
new HashMap<Watcher, HashSet<String>>();size
public synchronized int size(){
int result = 0;
for(Set<Watcher> watches : watchTable.values()) {//遍历路径->watcher的映射
result += watches.size();//把所有的watch个数加起来,但这里是不是会有重复???
}
return result;
}addWatch
//为某个path注册watcher
public synchronized void addWatch(String path, Watcher watcher) {
HashSet<Watcher> list = watchTable.get(path);//获得路径对应的watcher的set
if (list == null) {//之前没有watcher
// don't waste memory if there are few watches on a node
// rehash when the 4th entry is added, doubling size thereafter
// seems like a good compromise
list = new HashSet<Watcher>(4);//这里有优化,只建立为4的set,可能是考虑到实际使用中同一个znode不会有过多的watcher,节省了memory
watchTable.put(path, list);//更新watchtable
}
list.add(watcher);//添加watcher进入set
HashSet<String> paths = watch2Paths.get(watcher);//在watcher->路径中查找对应的路径
if (paths == null) {
// cnxns typically have many watches, so use default cap here
paths = new HashSet<String>();//同理,同一个watcher可能被加到多个znode上
watch2Paths.put(watcher, paths);
}
paths.add(path);//加入set
}其实这个方法总的来说就是两大步,第一是更新路径->watcher的映射,第二步是更新watcher->路径的映射,很好理解。
removeWatcher
//与上面方法相反,remove对应的watcher
public synchronized void removeWatcher(Watcher watcher) {
HashSet<String> paths = watch2Paths.remove(watcher);//从watcher->路径的映射中把整个watcher和它对应的所有path删掉
if (paths == null) {//paths是否为空
return;
}
for (String p : paths) {//不为空的话就取出来一个一个在路径->watcher的映射里扫描
HashSet<Watcher> list = watchTable.get(p);//取出watcher的set
if (list != null) {
list.remove(watcher);//remove对应的watcher
if (list.size() == 0) {//如果之前只有一个watcher,那么相应的path就没有watcher了,应该删掉
watchTable.remove(p);
}
}
}
}这里其实也是两大步,第一是更新watcher->路径的映射,第二步更新路径->watcher的映射,只是第二步的时候需要遍历所有path。
triggerWatch
//根据事件类型和路径触发watcher,supress是指定的应该被过滤的watcher集合
public Set<Watcher> triggerWatch(String path, EventType type, Set<Watcher> supress) {
WatchedEvent e = new WatchedEvent(type,
KeeperState.SyncConnected, path);//新建watchedEvent对象,这时一定是连接状态的
HashSet<Watcher> watchers;
synchronized (this) {
watchers = watchTable.remove(path);//把对应路径所有的watcher删除并返回
if (watchers == null || watchers.isEmpty()) {//watcher为空直接打log
if (LOG.isTraceEnabled()) {
ZooTrace.logTraceMessage(LOG,
ZooTrace.EVENT_DELIVERY_TRACE_MASK,
"No watchers for " + path);
}
return null;
}
for (Watcher w : watchers) {//watcher不为空
HashSet<String> paths = watch2Paths.get(w);
if (paths != null) {
paths.remove(path);//把所有的路径删掉
}
}
}
for (Watcher w : watchers) {//遍历前面获得的所有watcher
if (supress != null && supress.contains(w)) {//如果watcher在supress的set中跳过
continue;
}
w.process(e);//不在set中就触发
}
return watchers;
}这里有两点需要特别说一下:
为啥这里需要一个过滤的操作呢,可以通过下面datatree中deletenode里的代码可以了解:
Set<Watcher> processed = dataWatches.triggerWatch(path, EventType.NodeDeleted);//1 childWatches.triggerWatch(path, EventType.NodeDeleted, processed);//2 childWatches.triggerWatch(parentName.equals("") ? "/" : parentName, EventType.NodeChildrenChanged);
可以看到,每个节点对应的watch会存到datawatches里,且如果一个节点是另一个节点的子节点,那么在server获取getchildren指令的时候会把children相关的的watch加入到datatree的childwatches里去。这时如果节点本身已经触发过了那么childwatches里的节点的watches便不用被触发了(因为节点都要被delete了,不存在子节点)。
- 最后的process方法并不是客户端的watcher,而是ServerCnxn的process,默认实现是NioserverCnxn。
@Override
synchronized public void process(WatchedEvent event) {
ReplyHeader h = new ReplyHeader(-1, -1L, 0);
if (LOG.isTraceEnabled()) {
ZooTrace.logTraceMessage(LOG, ZooTrace.EVENT_DELIVERY_TRACE_MASK,
"Deliver event " + event + " to 0x"
+ Long.toHexString(this.sessionId)
+ " through " + this);
}
// Convert WatchedEvent to a type that can be sent over the wire
WatcherEvent e = event.getWrapper();//包装watcherevent
sendResponse(h, e, "notification");//发送回复
}DumpWatches
/**
* String representation of watches. Warning, may be large!
* @param byPath iff true output watches by paths, otw output
* watches by connection
* @return string representation of watches
*/
//把watch写到磁盘中
public synchronized void dumpWatches(PrintWriter pwriter, boolean byPath) {
if (byPath) {
for (Entry<String, HashSet<Watcher>> e : watchTable.entrySet()) {
pwriter.println(e.getKey());//利用PrintWriter去写
for (Watcher w : e.getValue()) {
pwriter.print(" 0x");
pwriter.print(Long.toHexString(((ServerCnxn)w).getSessionId()));
pwriter.print("
");
}
}
} else {
for (Entry<Watcher, HashSet<String>> e : watch2Paths.entrySet()) {
pwriter.print("0x");
pwriter.println(Long.toHexString(((ServerCnxn)e.getKey()).getSessionId()));
for (String path : e.getValue()) {
pwriter.print(" ");
pwriter.println(path);
}
}
}
}总结
- zk的cnxn的实现由NIO和Netty两种方式,最近工作也用了些Netty相关的,抽空好好学习总结下。
参考
https://www.cnblogs.com/leesf456/p/6288709.html
https://www.jianshu.com/p/9cf98fab15ac
以上是关于Zookeeper源码阅读 Server端Watcher的主要内容,如果未能解决你的问题,请参考以下文章