spark2.2.2安装和集群搭建
Posted guan-li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark2.2.2安装和集群搭建相关的知识,希望对你有一定的参考价值。
1.环境准备
安装Hadoop-2.7.2
安装scala-2.11.8
安装jdk-1.8.0_171
准备安装包:spark-2.2.2-bin-hadoop2.7.tgz,并解压至hadoop用户目录.
tar zxvf spark-2.2.2-bin-hadoop2.7.tgz
mv spark-2.2.2-bin-hadoop2.7 spark2.修改配置文件
- .bash_profile
#添加
export SPARK_HOME=/home/hadoop/spark
export PATH=$SPARK_HOME/sbin:$PATH- spark-env.sh(从spark-env.sh.template拷贝)
#jdk安装目录
export JAVA_HOME=/usr/local/jdk1.8.0_171
#scala安装目录
export SCALA_HOME=/usr/local/scala-2.11.8
#hadoop安装目录
export HADOOP_HOME=/home/hadoop/hadoop
#hadoop配置文件目录
export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop
#master节点ip
export SPARK_MASTER_IP=192.168.163.101
#每个worker节点能够最大分配给exectors的内存大小
export SPARK_WORKER_MEMORY=1g
#每个worker节点所占有的CPU核数目
export SPARK_WORKER_CORES=1
#每台机器上开启的worker节点的数目
export SPARK_WORKER_INSTANCES=1
- slaves(从slaves.template拷贝)
centos7-1
centos7-2
centos7-3修改完成后,将spark目录拷贝至各节点.
3.启动
- 启动hdfs
spark依赖hdfs,yarn可以不启动.
start-dfs.sh- 启动spark
spark/sbin/start-spark.sh- 查看进程
#主节点
Master
#工作节点
Worker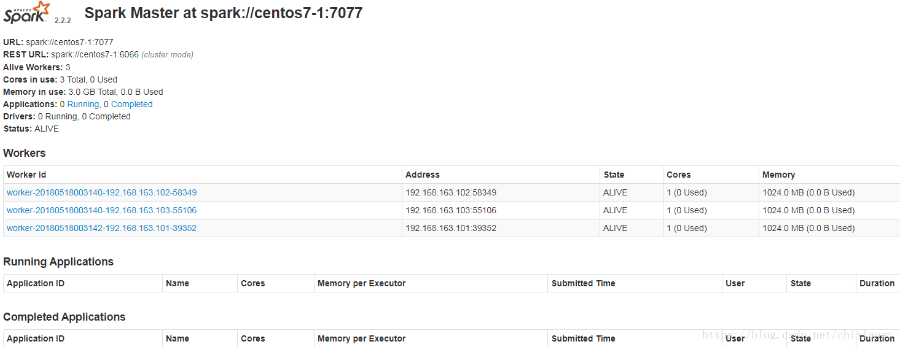
- spark-shell
spark/bin/spark-shell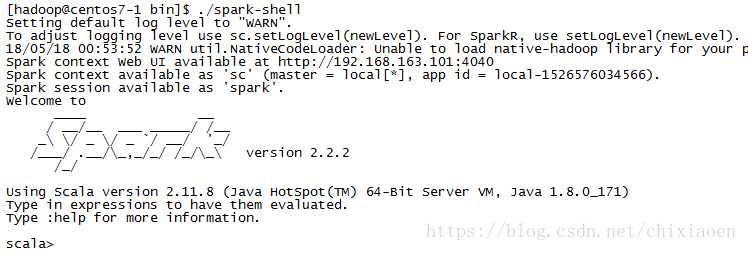
- 查看spark jobs
以上是关于spark2.2.2安装和集群搭建的主要内容,如果未能解决你的问题,请参考以下文章