阿里云消息队列 Kafka 生态集成的实践与探索
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云消息队列 Kafka 生态集成的实践与探索相关的知识,希望对你有一定的参考价值。
消息队列 Kafka 简介
Apache Kafka是一个分布式流平台,作为互联网领域不可或缺的消息组件,在全球获得了广泛的应用。在使用过程中,Kafka一般被作为消息流转的核心枢纽,上下游系统通过Kafka实现异步,削峰填谷。在大数据处理和实时数据处理领域Kafka也是不可替代的组件。
Kafka使用非常广泛,在有些领域使用已经非常成熟,如日志收集,大数据处理,数据库等领域。Kafka跟上下游也有标准化的对接模块,如日志收集有Flume,Filebeat,Logstash,大数据处理有spark,flink等组件。同时在一些小众的领域则没有现成的工具可以直接对接,如对接某个小众的数据库,或者用户自己定制化的系统。这时一般的对接方法是自行开发Kafka生产消费程序对接。
在不同系统对接时通常会遇到以下问题:
- 公司的不同团队对同一个系统有对接需求,各自开发重复造轮子,且实现方式不一,升级运维成本高。
- 各子系统由不同的团队开发,因此,各系统中的数据在内容和格式上,存在天然的不一致性,需要进行格式处理,以消除各系统数据之间格式的不同。
基于Kafka使用的广泛度和上下游系统的多样性考虑,Kafka推出了内置的上下游系统对接框架Kafka Connect。

Kafka Connect 介绍
Kafka Connect是一个用于将数据流输入和输出Kafka的框架。下面介绍connector的一些主要概念:
- Connectors:通过管理task来协调数据流的高级抽象
- Tasks:如何将数据复制到Kafka或从Kafka复制数据的实现
- Workers:执行Connector和Task的运行进程
- Converters:用于在Connect和外部系统发送或接收数据之间转换数据的代码
- Transforms:更改由连接器生成或发送到连接器的每个消息的简单逻
Connectors
Kafka Connect中的connector定义了数据应该从哪里复制到哪里。connector实例是一种逻辑作业,负责管理Kafka与另一个系统之间的数据复制。
connector有一些开源的实现。同时用户也可以从头编写一个新的connector插件,编写流程一般如下:

Tasks
Task是Connect数据模型中的主要处理数据的角色。每个connector实例协调一组实际复制数据的task。通过允许connector将单个作业分解为多个task,Kafka Connect提供了内置的对并行性和可伸缩数据复制的支持,只需很少的配置。这些任务没有存储任何状态。任务状态存储在Kafka中的特殊主题config.storage.topic和status.storage.topic中。因此,可以在任何时候启动、停止或重新启动任务,以提供弹性的、可伸缩的数据管道。
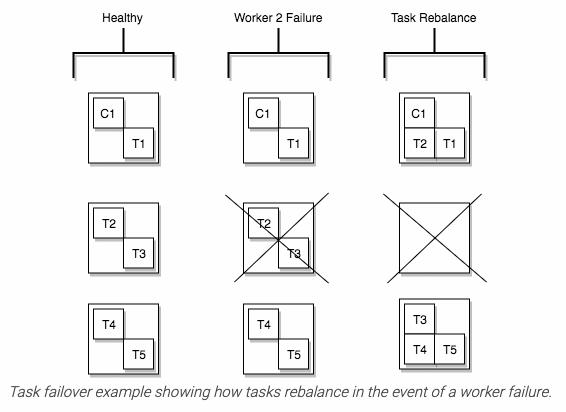
Task再平衡
当connector首次提交到集群时,workers会重新平衡集群中的所有connector及其tasks,以便每个worker的工作量大致相同。当connector增加或减少它们所需的task数量,或者更改connector的配置时,也会使用相同的重新平衡过程。当一个worker失败时,task在活动的worker之间重新平衡。当一个task失败时,不会触发再平衡,因为task失败被认为是一个例外情况。因此,失败的task不会被框架自动重新启动,应该通过REST API重新启动。
Converters
在向Kafka写入或从Kafka读取数据时,Converter是使Kafka Connect支持特定数据格式所必需的。task使用转换器将数据格式从字节更改为连接内部数据格式,反之亦然。
默认提供以下converters:
- AvroConverter:与Schema Registry一起使用;
- JsonConverter:适合结构数据;
- StringConverter:简单的字符串格式;
- ByteArrayConverter:提供不进行转换的“传递”选项;
转换器与连接器本身解耦,以便在连接器之间自然地重用转换器。
Transforms
Connector可以配置转换,以便对单个消息进行简单且轻量的修改。这对于小数据的调整和事件路由十分方便,且可以在connector配置中将多个转换链接在一起。
开源问题
Kafka connect线下单独部署时,设计的很不错了,但作为一个云服务提供时,还是存在了不少的问题,主要体现在以下几点:
- 与云服务的集成度不好:云厂商有不少闭源产品,对于开源产品的云托管版也会有访问控制等问题。
- 占用Kafka集群资源:每个connector任务都需要三个内置元信息topic,占用云产品资源,对于元信息topic的误操作也会导致任务异常。
- 运维管控接口和监控简单:管控接口没法控制运行资源粒度,监控缺少connector任务维度的指标。
- 与云原生架构结合不好:架构初始设计并非云原生,任务之间隔离度不够,负载均衡算法简单,没有动态自平衡能力。
基于Kafka connect部署在云上的种种问题,消息队列Kafka团队在兼容原生kafka connect框架的前提下,以云原生的方式重新实现了Kafka connect模块。
阿里云消息队列 Kafka Connect 解决方案
阿里云消息队列Kafka Connect框架介绍
架构设计将控制面和运行面分开,通过数据库和Etcd进行任务分发和模块通信。底层运行环境采用K8S集群,更好的控制了资源的粒度和隔离程度,整体架构图如下:
该架构在很好的解决了Apache Kafka Connect模块在云上遇到的问题:
- 与云服务的对接:运行环境部署时默认网络打通,运行面打通了访问控制模块;
- 占用Kafka集群资源:元信息采用数据库和Etcd存储,不占用Kafka topic资源;
- 运维管控接口增强:增强了资源层面的管控Api,可以精细化的控制每个任务的运行资源;
- 监控指标增强:任务维度全链路运行时metrics收集,监控数据从流入到流出的不同阶段的运行情况,出现问题是及时定位问题;
- 云原生架构设计:控制面统筹全局资源,实时监测集群负载,并能够自动完成负载均衡,失败重启,异常漂移等运维操作;
阿里云Kafka Connect介绍
阿里云消息队列Kafka已经支持的Connector类型如下:
涵盖了数据库,数据仓库,数据检索和报表,告警系统,备份需求这些主流的使用场景。
根据不同场景的实际需求,阿里云消息队列Kafka Connect主要两种实现方式:
1. 通过扩展Kafka Connect框架,完成外部系统与Kafka的直接对接。
2. 对于需要数据处理的任务类型,通过Kafka->函数计算(下简称fc)->外部系统的,在fc上可以灵活的定制化处理逻辑。
具体connect的实现方式如下:
数据库
数据库之间备份一般不会走kafka,msyql->kafka一般都是为了将数据分发给下游订阅,在mysql数据有变更时作出告警或这其他响应,链路mysql->kafka->订阅程序->告警/变更其他系统。
数据仓库
数据仓库阿里云上常用的是maxCompute,任务特点是吞吐量大,也有数据清洗需求,一般流程为kafka->maxCompute,然后maxCompute内部任务进行数据转换。也可以在入maxCompute之前进行数据清洗,链路一般为kafka->flink->maxCompute。对于数据转换简单或者数据量小的任务,可以使用函数计算替换flink,链路为kafka->fc->maxCompute。
数据检索和报表
通用的数据检索和报表一般通过es,数据传入es前需要做清洗处理,适合的路径kafka->flink->es/kafka->fc->es。
告警系统
告警系统中使用kafka一般流程 前置模块->kafka->订阅程序->告警模块,这种最好的方式是 前置模块->kafka->fc->告警。
备份需求
有些数据可能需要定期归档,做长期保存,oss是一个不错的介质,这种场景一般只需要保存原属数据,所以好的方式可能是kafka->oss。如果数据需要处理,可以通过Kafka->fc->oss链路。
阿里云消息队列 Kafka 生态规划
消息队列Kafka当前支持的connect都采用自研新架构独立开发,对于主流的使用场景已经有了不错的覆盖,但同时也可以看到,Kafka生态发展非常迅猛,Kafka的使用场景也越来越多,开源Kafka connect也在不断的发展,下一步消息队列Kafka会对接开源Kafka connect,让开源Kakfa connect可以无需修改,无缝的运行在自研的架构上。
总结
Kafka在互联网架构中已经占据了重要的位置,同时也在积极往上下游拓展,除了Kafka connect,还有Kafka Streams,Ksql,Kafka Rest Proxy等模块也在不断完善和成熟,相信在后续的发展中,Kafka在软件架构中会扮演越来越多的重要角色。
作者:尘辉
本文为阿里云原创内容,未经允许不得转载。
以上是关于阿里云消息队列 Kafka 生态集成的实践与探索的主要内容,如果未能解决你的问题,请参考以下文章