[MapReduce_8] MapReduce 中的自定义分区实现
Posted share23
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[MapReduce_8] MapReduce 中的自定义分区实现相关的知识,希望对你有一定的参考价值。
0. 说明
设置分区数量 && 编写自定义分区代码
1. 设置分区数量
分区(Partition)
分区决定了指定的 Key 进入到哪个 Reduce 中
默认 hash 分区,算法
// 返回的分区号 (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
设置分区数
job.setNumReduceTasks(3);
2. 代码编写
在 [MapReduce_1] 运行 Word Count 示例程序 代码基础之上进行以下操作
实现将文本中的数字存放在分区0,数字之外的内容放置到分区1
【2.1 编写 MyPartition.java】
package hadoop.mr.partition; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; /** * MapReduce 自定义分区 */ public class MyPartition extends Partitioner<Text, IntWritable> { /** * 自定义分区将数字放在0号分区,其余放在1号分区 */ @Override public int getPartition(Text key, IntWritable value, int numPartitions) { try { Integer.parseInt(key.toString()); return 0; } catch (Exception e) { return 1; } } }
【2.2 修改 WCApp.java】
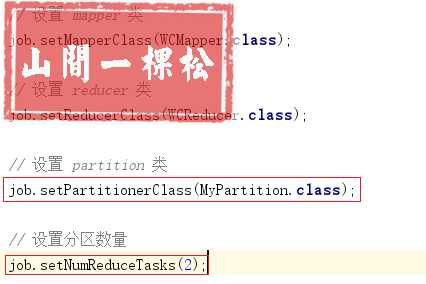
【2.3 最终结果】
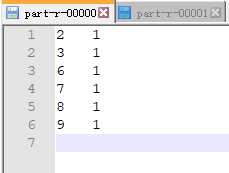
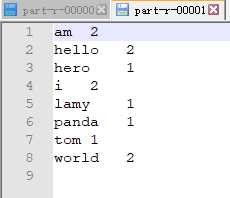
以上是关于[MapReduce_8] MapReduce 中的自定义分区实现的主要内容,如果未能解决你的问题,请参考以下文章
MapReduce程序——WordCount(Windows_Eclipse + Ubuntu14.04_Hadoop2.9.0)
大数据技术之_05_Hadoop学习_02_MapReduce_MapReduce框架原理+InputFormat数据输入+MapReduce工作流程(面试重点)+Shuffle机制(面试重点)(示例