K-means算法
Posted kexinxin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K-means算法相关的知识,希望对你有一定的参考价值。
K-means算法
- k-means聚类算法
在聚类问题中,给定数据集{x(1), . . . , x(m)},想要把这些数据划分成几个紧密联系的簇(clusters)。通常情况下,这里的x(i)∈ Rn,而标签y(i)是未知的。因此这是一个非监督式学习(unsupervised learning)问题。
最简单的聚类算法是k-means,k-means聚类算法如下:
-
初始化质心(即簇中心,cluster centroids),随机生成k个质心μ1, μ2, . . . , μk ∈ Rn;
-
循环下面的步骤直到收敛 {
对于每一个i,设定:
c(i) := arg minj ||x(i) –μj ||2
对于每一个j,设定
μj :=
}
上述算法中,k(算法的参数)就是我们要找的簇的个数,也是事先给定的聚类数;c(i)代表样本x(i)与k个类中距离最近的那个类,c(i)的值是1到k中的一个。而质心μj代表了我们对当前属于同一个类的样本中心的猜测。在初始化质心时,我们可以随机选择k个训练样本,然后让初始质心为这k个样本的值(当然,也有其他的随机初始化方法。)
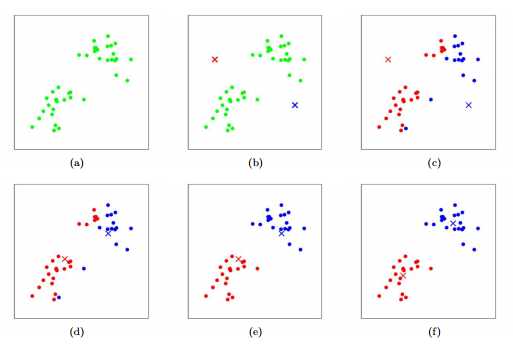
在算法的内循环中主要包括两个步骤:第一步是把每一个样本x(i)分配距离他最近的质心μj,第二步是把质心μj重新设置为分配后的各个样本的质心。下图展示了k-mean是如何学习的。
对于图中,各个点表示样本,而质心用×表示,图(a) 是原始数据集,图(b)是随机生成了两个质心(这里并没有随机使用两个训练样本)。图(c-f) 展示了k-means是如何运行的。通过不断的迭代,重新分配质心,使得结果越来越好。
那么k-means是否一定会收敛呢?是的,一定会收敛。首先我们定义一个畸变函数(distortion function) J(c, μ) = ,那么J描述了各个点 x(i) 到对应质心μc(i)的距离的平方和。可以看得出k-means在J上恰好使用了坐标下降法(coordinate descent,参照SVM章节坐标下降法)。具体的,在k-means算法的内循环中,通过固定μ不变,求得c使得J最小,之后在固定c,更新μ使得J最小。这样不断的循环着,J就一定会单调下降,因此J的值会收敛(这也暗示了c和μ是收敛的)。从理论上来说,k-means可能会在几个不同的聚类中摆动,比如存在不同的c和μ,使得J都是一样,不过这种情况很少见。
畸变函数J是非凸函数,因此坐标下降法并不能保证最终会收敛到全局最小值。换句话说,k-means可能会得到局部最优解。然而,通常情况下k-means能够得到很好的聚类结果。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,得到不同的聚类结果,然后取其中最小的J (c, μ)。
- 高斯混合模型和最大期望算法
在这一部分,我们讨论一下EM(Expectation Maximization,期望最大化算法,又称为最大化期望算法)用于核密度估计(density estimation)。给定数据集{x(1), . . . , x(m)},因为是非监督式学习的设定,因此这些数据点没有标签。
我们希望把数据用一个特定的联合分布p(x(i), z(i)) =p(x(i)|z(i))p(z(i))来建模。这里,我们认为z(i)服从多项式分布,z(i)~ Multinomial(Φ)(这里Φj≥0, = 1,参数Φj = p(z(i) = j),此外,对于给定的z(i),存在x(i)|z(i) = j ~ N(μj,∑j)。z(i)有k个值可以取{1, … ,k},我们的模型认为每一个样本x(i)都是在随机从{1, … ,k}取得的z(i)而生成的,而x(i)是可以用依赖于z(i)的k维高斯分布表示,这称之为混合高斯(mixture of Gaussians)模型。注意这里的z(i)是潜在(latent)随机变量,以为这他们是隐藏的或者不可见的。
那么我们的模型的参数是Φ, μ 和 Σ,为了估计出这些参数值,我们采用最大似然法则求解,这里的最大似然函数如下:
(Φ, μ,Σ) = =
然而,如果我们令该式子的偏导数为0,希望能够求解参数值,可是结果发现这是不可能的(因为求的结果不是封闭式 (close form))。随机变量z(i)指明了k维高斯分布x(i)是怎么来的。注意如果我们知道了z(i),那么最大似然问题就很容易求解了,因此我们可以这样写我们的最大似然函数:
(Φ, μ,Σ) =
最大化似然函数,得到参数Φ, μ,Σ值分别如下:
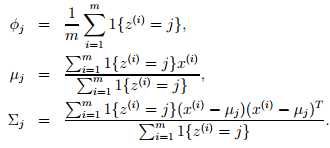
Φ就是样本类别中z(i)=j的比率。μ是类别为j的样本特征均值,Σ是类别为j的样例的特征的协方差矩阵。最终,我们看到了如果z(i)已知,并且把z(i)看作是分类的标签的话,那么这里的最大似然估计就相当于我们在估计高斯判别分析模型中的参数的时候一样。而我们的核心问题是,z(i)是未知的,那么我们该怎么做呢?
EM算法是一个迭代算法,主要包括两个步骤。在我们的问题中,可以用E-步,即猜一个潜在变量z(i)的值,在M-步中,我们根据上一步的猜测的模型来更新参数值,以获得最大似然估计。如下是EM算法:
循环直到收敛 {
(E-步) 对于每一个i,j:设定
w(i)j := p(z(i) = j|x(i); Φ, μ,Σ)
(M-步) 按如下方式更新参数:
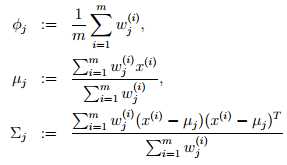
在E-步,我们计算了给定x(i)和设定的参数下,z(i)的后验概率(即w(i)j)可以通过贝叶斯法则来求解:
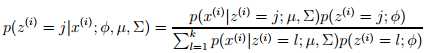
这里p(x(i) |z(i)=j; Φ, μ,Σ)是通过估计均值为μ,方差为Σ的高斯分布在x时的概率密度的,而p(z(i)= j ; Φ)是给定了Φj,其他的依次类推。此外,E-步中的w(i)j 代表了我们对z(i)的软猜测(软(soft)的意思是我们的猜测是一个在[0,1]之间的概率值,而硬(hard)猜测是一个最佳的具体值,比如从{1, … , k}中选择一个)。此外,我们需要对比一下M-步中,当z(i)给定时的式子的更新,与之前的高斯判别时给出的不一样,这里用w(i)j代替了z(i) 。
其实k-means也是一种EM算法,只是相比上面的软猜测,k-means里采用了硬猜测选择簇的分配c(i)。与k-means相似,EM也会容易获得局部最优解,因此多次尝试是一个不错的方法。通过不断循环的猜测z(i),EM给出了一个直观的解释,但是并没有给出他一定收敛的定量解释。下一讲,我们会深入研究EM算法。
- 最大期望算法一般化
之前我们主要讲了用于高斯混合拟合的EM算法。这里,我们将EM拓展到含有潜在变量的一类估计问题。在开始之前,先讨论一下Jensen不等式。
-
Jensen不等式
假设函数f是在实数域上,如果f‘‘(x) > 0,那么f就是一个凸函数(convex function)。考虑f的输入是向量形式的,那么它的hession矩阵一定是半正定的(semi-definite),即H ≥ 0。如果对于所有的x,均存在f‘‘(x) > 0,那么可以认为f是严格(strictly)凸函数(对应的在输入为向量的情况下,则是H > 0)。Jensen不等式,可以表示如下:
定理:如果f是凸函数,那么对于任意一随机变量X,存在E[f(X)] ≥ f(EX) ;更进一步,如果f是严格凸函数(非正式的说,就是曲线连续,不存在直线部分),那么当且仅当X = E[X]时,存在E[f(X)] = f(EX)。注意:在写期望的时候,我们通常都去掉了括号,即f(EX) = f(E[X])。
为了解释这个定理,我们从下图中看:
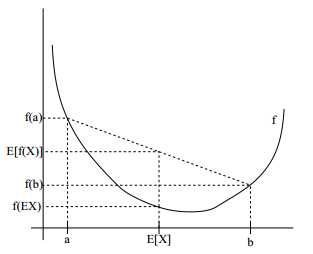
图中实线部分是凸函数f,X是一个随机变量,有0.5的机会选择值a,有0.5的机会选择b(如坐标轴上所示),那么X的期望E[X]就在ab中间的位置。同时,我们在y轴上标识出了f(a),f(b)和f(E[X])。在这个例子中,能够看出一定存在E[f(X)] ≥ f(EX) 。顺带一提,很多人都记不清楚不等式的符号,这里可以通过这个图来帮助记忆。注意:当且仅当-f也是凸的情况下(f′′(x) ≤ 0 or H ≤ 0),f是严格([strictly])凹的。Jensen不等式也存在:对于凹函数f,E[f (X )] ≤ f (EX )。
-
EM算法
假设我们有一个估计问题,对于m个训练数据{x(1), . . . , x(m)},我们希望能够通过数据拟合得到p(x,z)。通过最大似然估计,我们可以得到:
(θ) =
这里如果直接去求解参数θ的值,可能比较困难。这里的z(i)是潜在变量,通常情况下如果z(i)是观察得到的,那么该最大似然函数估计求解是非常容易的。在这样的设定下,EM算法给出了一个有效的方法来求解最大似然估计。直接最大似然函数(θ)是困难的,我们的策略是通过不断的建立(θ)的下界(E-步),然后优化下界(M-步)。
对于每一个i,用Qi 表示潜在变量z的分布(故Qj≥0, = 1,注意如果z是连续变量,那么Qi就是概率密度,求和就需要换成积分),那么:
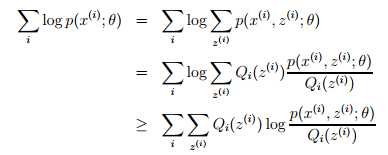
最后一步推导使用了Jensen不等式。具体的f(x) = logx 是一个凹函数,因为f ‘‘(x) = -1/x2 < 0,其中实数域x∈ R+,项是 [p(x(i), z(i); θ)/Qi(z(i))]的期望。根据Jensen不等式,我们有:
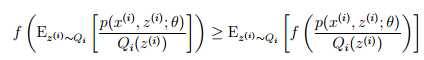
这里的下标z(i)~ Qi是指z(i)从 Qi产生。这样对于任意分布Qi,上式推导给出了(θ)的一个下界。这里Qi有很多选择,那么我们应该选择什么呢?如果我们现在猜一个参数θ,那么很自然的我们能够得到该参数下的(θ)的一个下界值。在后面我们将会证明EM的迭代是能够保证(θ)单调上升的。
在上述推导中,我们使用Jensen不等式,根据Jensen不等式如果要取等号的话,需要随机变量变成常数值,即 p(x(i), z(i); θ)/Qi(z(i)) = c 。c是不依赖于的z(i)常数,因此Qi(z(i)) 正比于p(x(i), z(i); θ),又因为 = 1(因为这是一个概率分布),因此可以推导出:
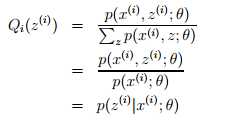
这里,我们得到了Qi是在给定x(i)下z(i)的后验概率。这就解决了如何选择Qi的问题。这就是在E-步中所要的建立(θ)的下界。在M-步,即通过最大化似然函数来更新参数θ。这样循环这两步就是所有的EM算法,即如下:
循环直到收敛 {
E-步:对于每一个i,设定
Qi(z(i)) := p(z(i)| x(i); θ)
M-步设定
θ := arg maxθ
}
然而,我们是怎样保证算法的收敛的呢?好吧,假设EM算法中成功更新的两次参数分别为θ(t)和θ(t+1)。我们知道EM算法每次更新都会导致似然函数增大,即(θ(t)) ≤ (θ(t+1))。这里的核心是在于我们对Qi的选择。即在EM算法迭代过程中,我们以θ(t)开始选择Qi(t)(z(i)) := p(z(i)| x(i); θ(t))。我们知道根据Jensen 不等式,为了取得等号,因此有:
(θ(t)) =
参数θ(t+1)就是在最大化上式右边部分得到的,因此:
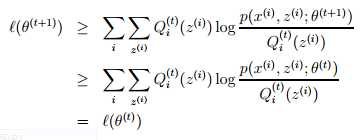
对于上述推导,第一个式子来自 (θ) ≥ ,这里对于任意的θ和Qi均成立,即对于Qi =Qi(t) 和θ =θ(t+1) 也成立。之后使用了θ(t+1)是最大化参数为θ(t)的似然函数,即arg maxθ 。而最后一步,就像之前那样,在选择Qi的时候就需要保证等号的成立。
因此,EM算法保证了似然函数的单调收敛。在EM算法的描述中,我们说要一直迭代直到收敛。根据我们推导的结果,我们可以通过测试(θ)在两次成功的迭代中增长的幅度是不是小于某个阈值,即判断EM算法中(θ)是否收敛太慢。
注:如果我们定义 J(Q, θ) = ,那么我们知道,对于之前的推导而言, (θ) ≥ J(Q, θ)。EM算法也可以被看成是在J上的坐标下降法,其中E-步在以Q为参数的最大化J,而M-步则是以θ为参数的最大化J。
以上是关于K-means算法的主要内容,如果未能解决你的问题,请参考以下文章