DRF的序列化
Posted mjc69213
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DRF的序列化相关的知识,希望对你有一定的参考价值。
一、为什么要序列化
当我们做前后端分离的项目~~我们前后端交互一般都选择JSON数据格式,JSON是一个轻量级的数据交互格式。那么我们给前端数据的时候都要转成json格式,那就需要对我们从数据库拿到的数据进行序列化。接下来我们看下django序列化和rest_framework序列化的对比~~
Python --- >json 序列化
json ---> Python 反序列化
二、Django序列化的方法
.values 和JsonResponse -- 自己去构建想要的数据结构
models
from django.db import models # Create your models here. __all__ = [‘Book‘, ‘Publisher‘, ‘Author‘] class Book(models.Model): title = models.CharField(max_length=32, verbose_name=‘书名‘) CHOICES = ( (1, ‘python‘), (2, ‘php‘), (3, ‘linux‘), (4, ‘go‘) ) category = models.SmallIntegerField(choices=CHOICES, verbose_name="分类") put_time = models.DateField(auto_now_add=True) pub = models.ForeignKey(to=‘Publisher‘) auth = models.ManyToManyField(to="Author") class Meta: db_table = ‘01-图书‘ verbose_name_plural = db_table def __str__(self): return self.title class Publisher(models.Model): title = models.CharField(max_length=32, verbose_name="出版社名") class Meta: db_table = "02-出版社" verbose_name_plural = db_table def __str__(self): return self.title class Author(models.Model): name = models.CharField(max_length=32, verbose_name="作者名子") class Meta: db_table = "03-作者" verbose_name_plural = db_table def __str__(self): return self.name
json.dumps() + HttpResponse()
from django.shortcuts import render, HttpResponse from django.views import View from app01 import models import json class Cbv(View): def get(self, request): books = models.Book.objects.values(‘id‘, ‘title‘, ‘pub‘) ret = json.dumps(list(books), ensure_ascii=False) return HttpResponse(ret)
JsonResponse HttpResponse 区别做了序列化 json.dumps, 还帮助我们序列化了datetime
JsonResponse
from django.shortcuts import render, HttpResponse from django.http import JsonResponse from django.views import View from app01 import models class Cbv(View): def get(self, request): books = models.Book.objects.values(‘id‘, ‘put_time‘, ‘title‘,‘pub‘) book_list = list(books) for book in book_list: p = models.Publisher.objects.filter(id=book[‘pub‘])[0] book[‘pub‘] = {‘id‘:p.id, ‘title‘:p.title} ret = JsonResponse(book_list, safe=False, json_dumps_params={"ensure_ascii":False}) return HttpResponse(ret)
用django的serialize方法 外键依然不能够被序列化 取出来的依然是id
from django.shortcuts import render from django.views import View from django.http import HttpResponse, JsonResponse from .models import Book, Publisher from django.core import serializers import json class BookView(View): def get(self, request): book_list = Book.objects.all() ret = serializers.serialize("json", book_list, ensure_ascii=False) return HttpResponse(ret)
三、DRF序列化
1、下载
pip install djangorestframework
2、在settings里注册app
INSTALLED_APPS = [ ‘django.contrib.admin‘, ‘django.contrib.auth‘, ‘django.contrib.contenttypes‘, ‘django.contrib.sessions‘, ‘django.contrib.messages‘, ‘django.contrib.staticfiles‘, ‘rest_framework‘,
3、DRF序列化
声明一个序列化器
# 导入serializers包
from rest_framework import serializers # 声明序列化的类和字段 class Publisher_serializers(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) class Author_serializers(serializers.Serializer): id = serializers.IntegerField() name = serializers.CharField(max_length=32) class Book_serializers(serializers.Serializer): id = serializers.IntegerField(required=False) # required=False代表反序的时候不需要验证 title = serializers.CharField(max_length=32) CHOICES = ( (1, ‘python‘), (2, ‘php‘), (3, ‘linux‘), (4, ‘go‘) ) category = serializers.ChoiceField(choices=CHOICES, source=‘get_category_display‘) pub = Publisher_serializers() auth = Author_serializers(many=True) # mangy=True表示对Queryset进行处理,mant=False表示对对象进行进行处理
views
# 导入APIView from rest_framework.views import APIView # 导入Response from rest_framework.response import Response from app01 import serializers from app01 import models import json class Cbv(APIView): def get(self, request): books = models.Book.objects.all() # 序列化,两个参数,instance:接受Queryset(或者对象) mangy=True表示对Queryset进行处理,many=False表示对对象进行进行处理 book_ser_obj = serializers.Book_serializers(instance=books, many=True) # 也可以json进行序列化,输出的格式不一样 # ret = json.dumps(book_ser_obj.data, ensure_ascii=False) return Response(book_ser_obj.data)
四、DRF反序列化
正序反序的时候数据类型不统一
book_obj = { "title": "xxx", "category": 1, # choices 正序的时候是中文CharField,反序的时候是IntegerField
"publisher": 1, # 多对1 正序的时候是字典对象,反序的时候是IntegerField
"authors": [1, 2] # 多对多 正序的时候是列表对象,反序的时候是IntegerField
}
序列化器需要注意的几点
- read_only
- write_only
- require=Flase
- 正序和反序列化的时候字段类型不同的时候
- 重写create方法
- ORM的操作进行新增数据
serializers.py
from rest_framework import serializers from app01.models import Book class Publisher_serializers(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) class Author_serializers(serializers.Serializer): id = serializers.IntegerField() name = serializers.CharField(max_length=32) class Book_serializers(serializers.Serializer): id = serializers.IntegerField(required=False) # required=False代表反序的时候不需要验证 title = serializers.CharField(max_length=32) CHOICES = ( (1, ‘python‘), (2, ‘php‘), (3, ‘linux‘), (4, ‘go‘) ) # 因为正序反序时字段不统一,所以要设计不同的字段 category = serializers.ChoiceField(choices=CHOICES, source=‘get_category_display‘, read_only=True) # 正序的时候用 post_category = serializers.ChoiceField(choices=CHOICES, write_only=True) # 反序的时候用 pub = Publisher_serializers(read_only=True) # 正序的时候用 auth = Author_serializers(many=True, read_only=True) # 正序的时候用 pub_id = serializers.IntegerField(write_only=True) # 反序时用 auth_list = serializers.ListField(write_only=True) # 反序时用 # 反序保存时要重写create def create(self, validated_data): # validated_date-->OrderedDict([(‘title‘, ‘书剑恩仇录1‘), (‘post_category‘, 1), (‘pub_id‘, 2), (‘auth_list‘, [1, 2])]) # 执行ORM新增数据的操作 book_obj = Book.objects.create( title=validated_data[‘title‘], category=validated_data[‘post_category‘], pub_id=validated_data[‘pub_id‘], ) book_obj.auth.add(*validated_data[‘auth_list‘]) # 添加多对多的关系 return book_obj def update(self, instance, validated_data): # 因为不知道具体更新的是那一个字段,因此每个字段都要写 instance就是视图传过来的具体的对象 instance.title = validated_data.get(‘title‘, instance.title) # 有就更新,没有就保持原来的值 instance.category = validated_data.get(‘post_category‘, instance.category) # 注意正反序时不同的字段名子 instance.pub_id = validated_data.get(‘pub_id‘, instance.pub_id) if validated_data.get(‘auth_list‘): # 如果validated_data有多对多的关系 instance.auth.set(*validated_data[‘auth_list‘]) # 设置多对多的关系 instance.save() # 保存对象的更新 return instance # 返回这个对象
views.py
# 导入APIView from rest_framework.views import APIView # 导入Response from rest_framework.response import Response from app01 import serializers from app01 import models class Cbv(APIView): def get(self, request): books = models.Book.objects.all() # 序列化,两个参数,instance:接受Queryset(或者对象) mangy=True表示对Queryset进行处理,many=False表示对对象进行进行处理 book_ser_obj = serializers.Book_serializers(instance=books, many=True) return Response(book_ser_obj.data) def post(self, request): book_obj = request.data # 所有传过来的数据都在request.data里 print(book_obj) # {‘title‘: ‘书剑恩仇录1‘, ‘post_category‘: 1, ‘pub_id‘: 2, ‘auth_list‘: [1, 2]} ser_obj = serializers.Book_serializers(data=book_obj) # 反序 # 排除read_only=True required=False这些验证数据是有效的 if ser_obj.is_valid(): print(ser_obj.validated_data) # OrderedDict([(‘title‘, ‘书剑恩仇录1‘), (‘post_category‘, 1), (‘pub_id‘, 2), (‘auth_list‘, [1, 2])]) ser_obj.save() # 保存时要在序列化器里重写create,不写报 NotImplementedError: `create()` must be implemented. return Response(ser_obj.validated_data) # 返回验证通过的数据 return Response(ser_obj.errors) # 验证不通过返回错误信息
源码create部分:
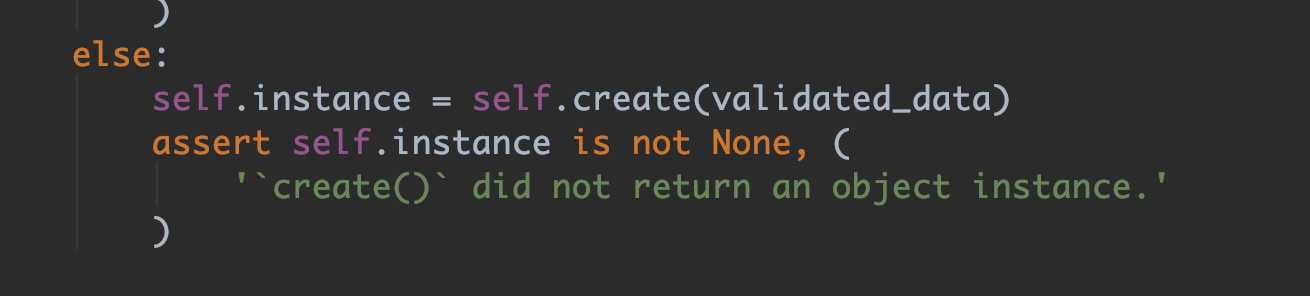

测试数据:
# 要和反序的字段名对应起来 { "title": "书剑恩仇录1", "post_category": 1, "pub_id": 2, "auth_list": [1, 2] }
五、DRF的更新操作
urls.py
urlpatterns = [ ....... url(r‘^api/books/$‘,Cbv_drf.as_view()), url(r‘^api/book/(?P<id>d+)/$‘, BookEditView.as_view()) ....... ]
序列化器需要重写update方法
def update(self, instance, validated_data): # 因为不知道具体更新的是那一个字段,因此每个字段都要写 instance就是视图传过来的具体的对象 instance.title = validated_data.get(‘title‘, instance.title) # 有就更新,没有就保持原来的值 instance.category = validated_data.get(‘post_category‘, instance.category) # 注意正反序时不同的字段名子 instance.pub_id = validated_data.get(‘pub_id‘, instance.pub_id) if validated_data.get(‘auth_list‘): # 如果validated_data有多对多的关系 instance.auth.set(*validated_data[‘auth_list‘]) # 设置多对多的关系 instance.save() # 保存对象的更新 return instance # 返回这个对象
views.py
class BookEditView(APIView): def get(self, request, id): book_obj = models.Book.objects.filter(id=id).first() # 获取从url中传过来id的book对象 ser_obj = serializers.Book_serializers(book_obj) # 正序列化 return Response(ser_obj.data) # 返回序列化后的数据 def patch(self, request, id): ‘‘‘patch局部更新 put全部更新‘‘‘ book_obj = models.Book.objects.filter(id=id).first() # 获取要更新的对象 ser_obj = serializers.Book_serializers(instance=book_obj, data=request.data, partial=True) # 反序,partial=True允许部分验证,也就是说验证提交的部分,不提交的部分不做验证 if ser_obj.is_valid(): ser_obj.save() return Response(ser_obj.validated_data) return Response(ser_obj.errors)
六、验证
1、单个字段的验证(钩子函数)
def validate_字段名称(self, vlaue): 处理我们验证的逻辑
验证通过: return vlaue
验证不通过:
raise serializers.ValidationError("错误信息")
serializers.py
.......... def validate_title(self, value): ‘‘‘单个字段的验证‘‘‘ if len(value) < 3: raise serializers.ValidationError(‘长度不够‘) return value
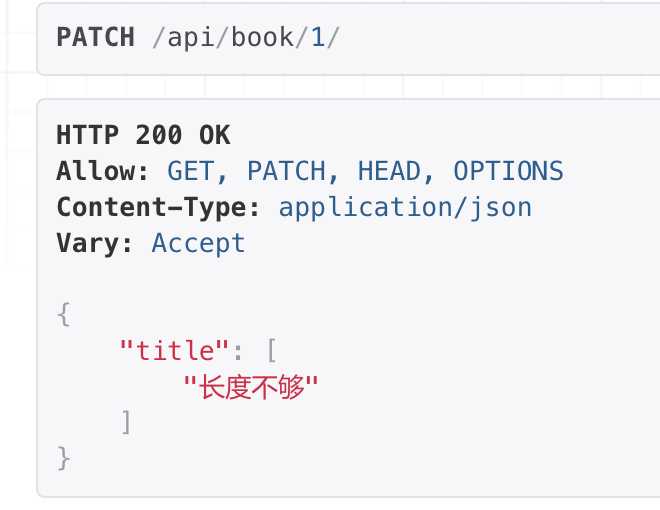
2、多个字段的验证(validate)
def validate(self, attrs): attrs 所有传过来的数据 {} 字典里含有 字段的名称 : 值 。。。。 通过 return attrs 不通过 raise serializers.ValidationError("错误信息")
serializers.py
def validate(self, attrs): ‘‘‘多个字段的验证‘‘‘ print(attrs) # attrs 提交的字段名和值组成的字典 if len(attrs[‘title‘]) < 3 or attrs[‘post_category‘] == 1: # 如果长度小于3或者类型是1的 raise serializers.ValidationError(‘输入不符合要求‘) return attrs
3、自定义验证
1、自定义一个函数 def my_validate(value): 处理自己的验证逻辑 验证通过return传进来的值 验证不通过 raise serializers.ValidationError("错误信息") 2、给我们的字段加属性 validators=[my_validate]
serializers.py
# 建一个自定义的函数 ................... def my_validate(value): if len(value) < 3: raise serializers.ValidationError(‘长度不够‘) return value # 在需要验证的字段上加上属性 validators=[xxxx] .................... title = serializers.CharField(max_length=32, validators=[my_validate])
4、验证顺序
字段属性验证>钩子函数>全局的validate
七、ModelSerializer
快速建立相关模型的serializer 模型
- 自动产生基于模型的fileds
- 自动产生验证器,比如unique_together验证器
- 默认包含create和uodate方法
(一)定义一个ModelSerializer序列化器
from rest_framework import serializers from .models import Book class BookModel(serializers.ModelSerializer): class Meta: model = Book # fields = ‘__all__‘ # 显示所有字段 # fields = [‘title‘, ‘category‘, ‘put_time‘, ] # 指定显示列表中的字段 exclude = [‘id‘] # 排除列表中的字段,不能和fields同时出现
(二)外键关系的序列化
注意:当序列化类MATE中定义了depth时,这个序列化类中引用字段(外键)则自动变为只读
from rest_framework import serializers from .models import Book class BookModel(serializers.ModelSerializer): class Meta: model = Book # fields = ‘__all__‘ # 显示所有字段 # fields = [‘title‘, ‘category‘, ‘put_time‘, ] # 指定显示列表中的字段 exclude = [‘id‘] # 排除列表中的字段,不能和fields同时出现 depth = 1 # depth 代表找关联关系嵌套的第几层
(三)自定义字段
我们可以声明一些字段来覆盖默认字段,来进行自定制~
from rest_framework import serializers from .models import Book class BookModel(serializers.ModelSerializer): category = serializers.CharField(source="get_category_display", read_only=True) # 重写category字段,覆盖原来的字段 class Meta: model = Book # fields = ‘__all__‘ # 显示所有字段 # fields = [‘title‘, ‘category‘, ‘put_time‘, ] # 指定显示列表中的字段 exclude = [‘id‘] # 排除列表中的字段,不能和fields同时出现 depth = 1 # depth 代表找关联关系嵌套的第几层
(四)post以及patch请求
由于depth会让我们外键变成只读,去掉depth就可以了~~
(五)SerializerMethodField 来优化不必要的查询拼接自定义的数据结构
from rest_framework import serializers from .models import Book class BookModel(serializers.ModelSerializer): category_dis = serializers.SerializerMethodField(read_only=True) def get_category_dis(self, obj): return obj.get_category_display() class Meta: model = Book # fields = ‘__all__‘ # 显示所有字段 # fields = [‘title‘, ‘category‘, ‘put_time‘, ] # 指定显示列表中的字段 exclude = [‘id‘] # 排除列表中的字段,不能和fields同时出现 depth = 1 # depth 代表找关联关系嵌套的第几层 extra_kwargs = {‘category‘:{‘write_only‘:True}} # 附加关键字参数,将字段名称映射到关键字参数的字典,不加这个会显示两个category

from rest_framework import serializers from .models import Book class BookModel(serializers.ModelSerializer): pub_info = serializers.SerializerMethodField(read_only=True) def get_pub_info(self, obj): # 序列化的Book对象,通过Book对象找到我们的publisher对象,就可以拿到我们想要的字段,拼接成自己想要的数据结构 ret = { ‘title‘:obj.pub.title # 自定义外键的显示只显示title,不显示id } return ret class Meta: model = Book fields = ‘__all__‘ # 显示所有字段 # fields = [‘title‘, ‘category‘, ‘put_time‘, ‘pub_info‘] # 指定显示列表中的字段 # exclude = [‘id‘] # 排除列表中的字段,不能和fields同时出现 # depth = 1 # depth 代表找关联关系嵌套的第几层 extra_kwargs = { "pub":{"write_only":True} # 通过附加关键字参数,让model的pub字段,只在反序的时候使用 }

from rest_framework import serializers from .models import Book class BookModel(serializers.ModelSerializer): author_count = serializers.SerializerMethodField() def get_author_count(self, obj): # 序列化的Book对象,通过Book对象找到我们的publisher对象,就可以拿到我们想要的字段,拼接成自己想要的数据结构 ret = obj.auth.all().count() return ret class Meta: model = Book # fields = ‘__all__‘ # 显示所有字段 fields = [‘title‘, ‘put_time‘, ‘author_count‘] # 指定显示列表中的字段 # exclude = [‘id‘] # 排除列表中的字段,不能和fields同时出现 # depth = 1 # depth 代表找关联关系嵌套的第几层

用ModelSerializer改进上面Serializer的完整版
from rest_framework import serializers from .models import Book class BookModel(serializers.ModelSerializer): category_dis = serializers.SerializerMethodField(read_only=True) author_count = serializers.SerializerMethodField(read_only=True) pub_info = serializers.SerializerMethodField(read_only=True) auth_info = serializers.SerializerMethodField(read_only=True) def get_category_dis(self, obj): ‘‘‘返回category的实际名称‘‘‘ return obj.get_category_display() def get_author_count(self, obj): ‘‘‘返回作者的个数‘‘‘ ret = obj.auth.all().count() return ret def get_pub_info(self, obj): ‘‘‘自定义一对多关系publisher中显示的数据结构‘‘‘ ret = { ‘id‘:obj.pub.id, ‘title‘:obj.pub.title } return ret def get_auth_info(self, obj): ‘‘‘自定义多对多author中显示的数据结构‘‘‘ # 通过obj拿到authors,构建想要的数据结构返回 ret = [] for i in obj.auth.all(): ret.append({ ‘id‘:i.id, ‘name‘:i.name }) return ret class Meta: model = Book fields = ‘__all__‘ # 显示所有字段 # fields = [‘title‘, ‘put_time‘, ‘author_count‘] # 指定显示列表中的字段 # exclude = [‘id‘] # 排除列表中的字段,不能和fields同时出现 # depth = 1 # depth 代表找关联关系嵌套的第几层 extra_kwargs = { ‘category‘:{‘write_only‘:True}, ‘pub‘:{‘write_only‘:True}, ‘auth‘:{‘write_only‘:True} }
views.py
from rest_framework.views import APIView from rest_framework.response import Response from .models import Book from .model_serializers import BookModel class Model_views(APIView): def get(self, request): all_book = Book.objects.all() ser_book = BookModel(all_book, many=True) return Response(ser_book.data) def post(self, request): ser_obj = BookModel(data=request.data) # 反序,request.data拿到传过来的数据 if ser_obj.is_valid(): ser_obj.save() return Response(ser_obj.validated_data) return Response(ser_obj.errors)
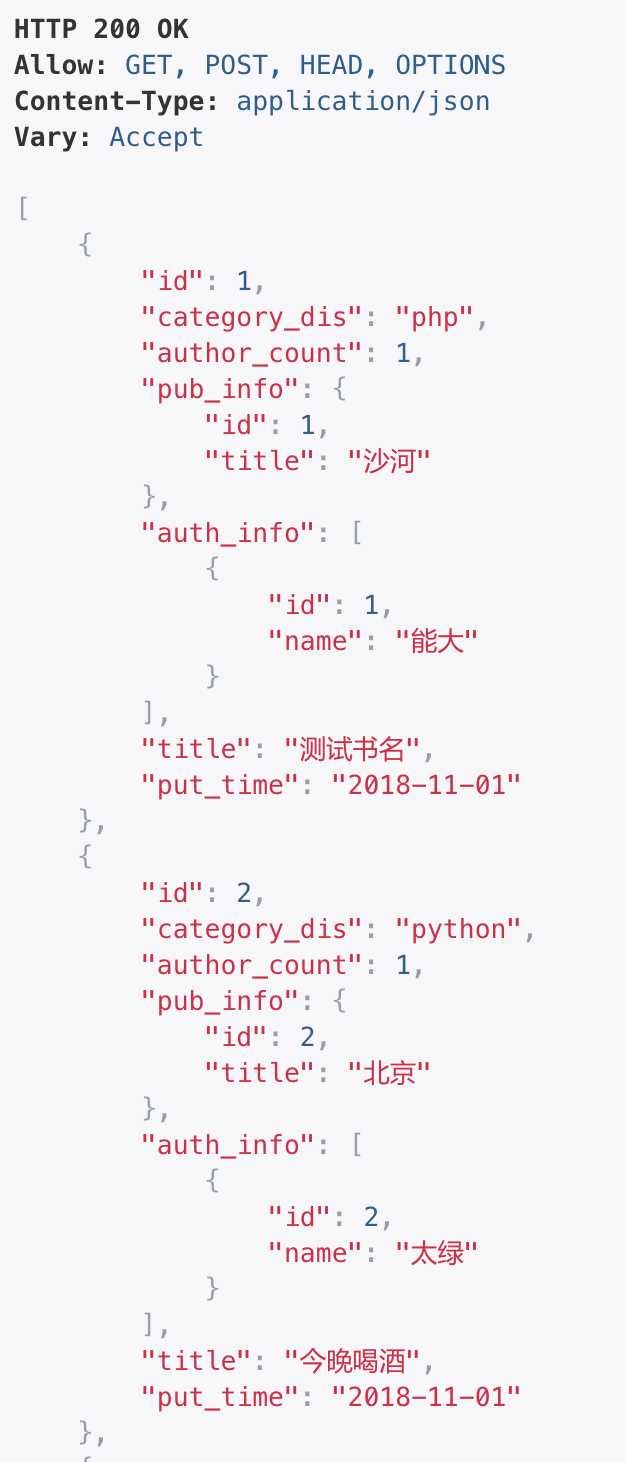
以上是关于DRF的序列化的主要内容,如果未能解决你的问题,请参考以下文章