ssm学习——Lucene建立索引
Posted dbbf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ssm学习——Lucene建立索引相关的知识,希望对你有一定的参考价值。
一:理论知识
1.非结构化数据查询方法
1)顺序扫描法
太慢,效率不高。
2)全文检索法
对需要查询的文档创建索引,再对其进行搜索。其实说白了就是为了使其结构化。
2.索引创建和搜索流程图
1)流程图
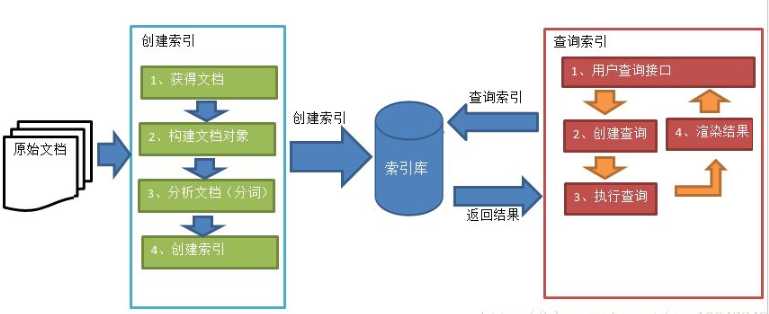
2)索引库
索引库是由两部分组成的,一部分是索引,另一部分是文档对象(不是原始文档)。
3.流程图详解
1)创建文档对象
有以下规则
a.不同的文档可以有不同的Field
b.同一个文档可以有相同的Field
c.每一个文档有一个唯一的编号id
2)分析文档
分析的过程是经过对原始文档提取单词,将字母转换成小写,去除标点符号等过程最终生成语汇单元(一个一个的单词)。
注意:不同的域中生成的term是不同的term。
term好像是索引的基本单位,term包含文档域名和单词内容。例如一个文档的文件名包含java是不同于内容中包含java的。这是通过term来实现的。
3)创建索引
为每一个term,指向所在的文档对象。Lucene是倒排索引,是先找到这个term再找到这个文档,这种方法比顺序查找效率高。
二:实例
1.准备工作
1)创建java工程
2)导包
lucene-core-4.10.3.jar
lucene-analyzer-common-4.10.3.jar
lucene-queryparser-4.10.3.jar
common-io-2.4.jar
2.实现步骤
1)实现步骤
1.创建一个IndexWriter对象
指定索引库存放位置
指定一个分析器
2.创建document对象
3.创建field对象
4.使用IndexWriter对象进行索引创建
4.关闭IndexWriter对象
2)代码
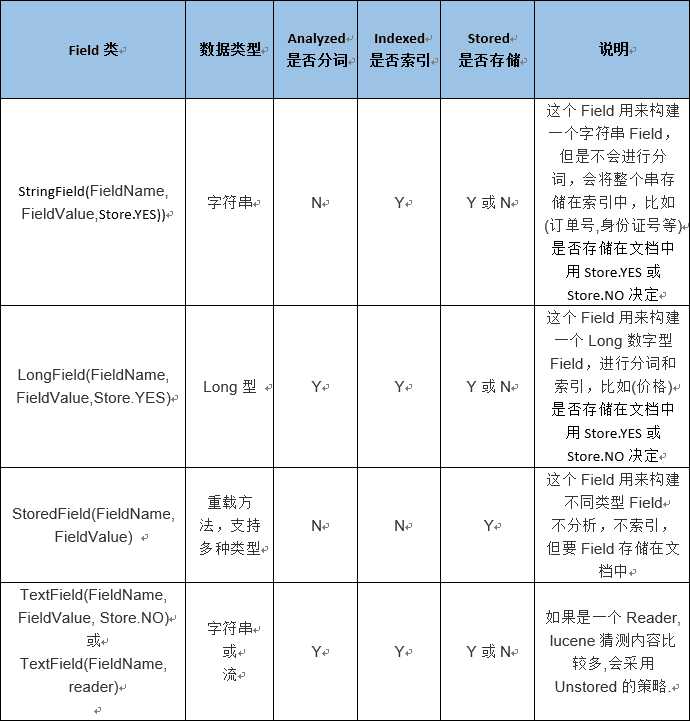
3.Field的一些说明
1)Field域有几大实现类,选择依据:
是否分析:是否对域的内容进行分词处理。是否要对域的内容进行查询
是否索引:无论是否分析,但是索引要搜索到。有一些不分析,但是也要进行索引。
是否存储:将Field值存储在文档对象中,凡是将来要从Document中获取的Field都要存储。
2)Field的子类
3)使用工具查看建立的索引库
Luke - Lucene Index Toolbox
注意事项:Lucene不提供信息采集的类库,需要其它库支持。(Nutch,jsoup,heritrix)
以上是关于ssm学习——Lucene建立索引的主要内容,如果未能解决你的问题,请参考以下文章