软件工程之词频统计
Posted mttblog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了软件工程之词频统计相关的知识,希望对你有一定的参考价值。
代码: https://github.com/jackroos/word_frequency
how you collaborate: working separately? pair programming? VS Live Share? other style?
首先我们一起讨论了代码结构,如何用python实现来更快的进行词频统计。然后是分工合作,队友负责python实现,我负责代码复审、单元测试、回归测试,同时我们采用了结对编程的方式对代码的瓶颈一起进行了分析和优化。
how do you discuss design guideline, coding convention and reach agreement?
我们在设计代码的模块的时候,遵循每个模块的功能相对独立的原则,代码风格都用pycharm, 4个空格缩进,函数名能尽量看出功能等等。因此,根据这个规则,我们一起设计了各个模块的功能和接口
- freq_dict.py : 所有freq类的父类,实现topk 以及文件递归路径等功能
- charater_freq_dict.py: 实现字母频率统计
- word_freq_dict.py: 词频统计,指称stop word
- phrase_freq_dict.py: 短语频率统计,支持stop word和动词原形变化
- preprocessing.py: 对读入文件各种parse到我们想要的格式,比如word list,过滤stop-word等等
how did the two of you aim high and try to deliver the optimal result with your own time constraints? is this the best your could do? what prevent you from doing your best?
在项目开始之前,要充分的讨论,然后各自发挥强项,感觉效率还是很高的,另外从中我感觉自己从队友的设计什么的学到了挺多的。代码因为是python所以很多地方不是很好优化,我们主要从多进程来优化,如果有更多的时间,可能有进一步的优化,但我感觉优化的空间不大。
list 3 strengths and 1 weak area of your partner
对python很熟悉,接口模块设计的比较清晰,思路很清楚;写代码比较粗心
how do you use profile tools to find the performance bottleneck and improve speed? show some screenshots of your analysis
在一开始的时候我们就打算采用多进程来并行处理多个文件,在代码写好之后,用cProfile和gprofdot进行性能测试分析,我们发现处理多个文件的时候,代码似乎并没有并行起来:
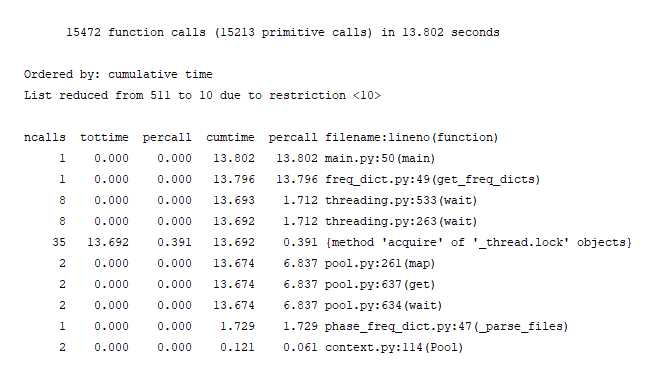
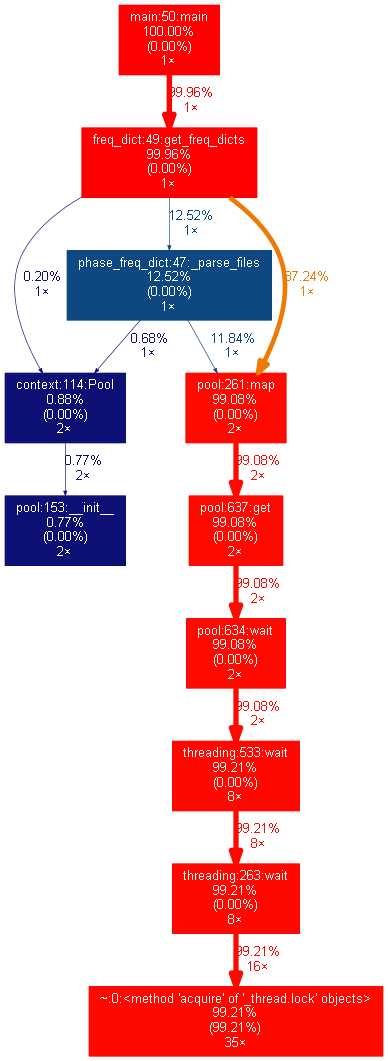
我们发现时间主要花在进程等待获取锁上面,python多进程会把共享的变量object_lists每个都复制一份,这样每次复制一份parse后的sentence list会花费很多时间,因此我们把parse_raw_text_to_sentences移到函数内,在函数内计算sentence list, 参数复制的是 text_path_list, 快了很多。
修改之前:
def _get_freq_dict_for_text(self, index):
cnt = Counter()
object_list = self.object_lists[index]修改之后:
def _get_freq_dict_for_text(self, index):
cnt = Counter()
object_list = parse_raw_text_to_sentences(self.text_path_list[index])时间提升了一半:
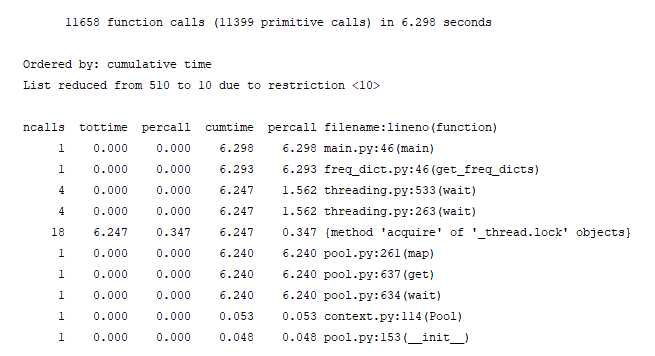
单元测试/回归测试
见github
以上是关于软件工程之词频统计的主要内容,如果未能解决你的问题,请参考以下文章