序列模型第一课--循环序列模型
Posted nxf-rabbit75
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了序列模型第一课--循环序列模型相关的知识,希望对你有一定的参考价值。
一. why sequence models?
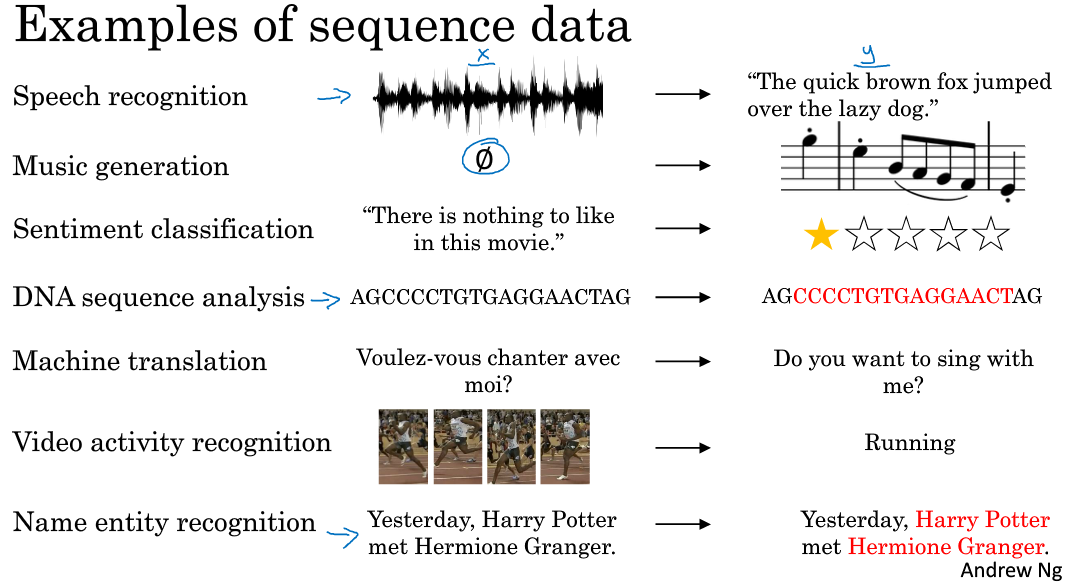
(1)序列模型广泛应用于语音识别,音乐生成,情感分析,DNA序列分析,机器翻译,视频行为识别,命名实体识别等众多领域。
(2)上面那些问题可以看成使用(x,y)作为训练集的监督学习,但是输入与输出的对应关系有非常多的组合,
比如一对一,多对多,一对多,多对一,多对多(个数不同)等情况来针对不同的应用。
二.数学符号说明 Notation
假设有这样一句话:
X:Harry Potter and Hermoine Granger invented a new spell.
目的是想识别出句子中的实体词。所谓实体词包括人名, 地名,组织机构名称等等。
可见,输入的句子可以看成是单词的序列,那么我们期望的输出应是如下对应的输出:
Y:1 1 0 1 1 0 0 0 0
1代表的是“是实体”;0代表的是“非实体”
(当然,实际的命名实体识别比这输出要复杂得多,还需要表示实体词的结束位置与开始位置,在这个栗子中我们暂且选择以上这种简单的输出形式来讲解)
显而易见,输入的x与输出的y的序列个数一致,且索引位置相对应,我们用如下符号来表示输入与输出:
(t)表示第t时刻的输入;
(T_x) 表示样本(x)的序列长度;(T_y) 表示样本(x)输入模型后,输出序列的词长度,在本例中,输出与输出序列的长度相等,为9;
(x^{(i)<t>}),(y^{(i)<t>})
样本往往有很多个,用以下符号表示,第i个样本t时刻的输入与输出:
用以下符号表示第i个样本的输入序列的长度与输出序列的长度:
(T^{(i)}_x), (T^{(i)}_y)

三.What is the Recurrent Neural Networks
(1) 为什么叫循环神经网络呢?
- 1.输入和输出在不同的样本中可以有不同的长度,即使能找到输入输出的最大值,对某个样本来说填充来使他达到最大长度,但是这种表示方式依然不够好;
- 2.标准神经网络不能讲从文本不同位置学习到的特征共享,比如在第一个位置学习到了Harry是一个人名,如果Harry再次出现在其他位置的时候,不能自动识别它是一个人名,还需要重新识别

(2) 什么是循环神经网络?
仍然使用这句话作为例子
X:Harry otter and Hermoine Granger invented a new spell.
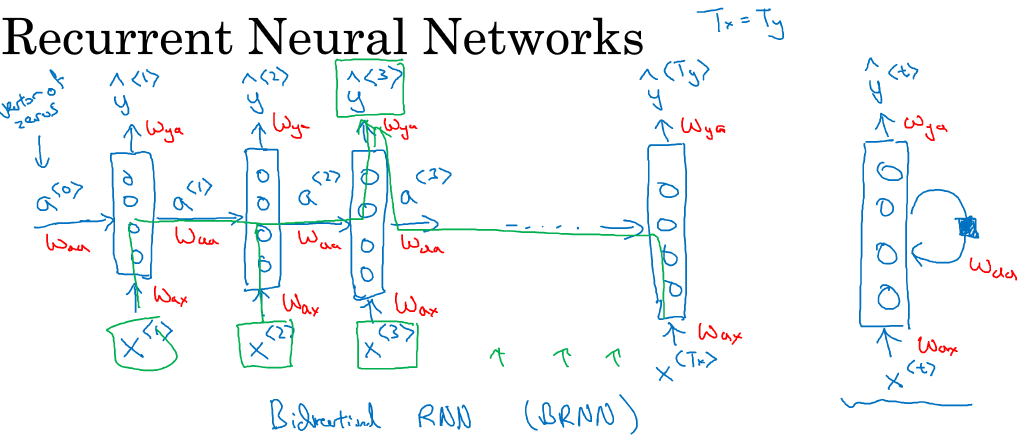
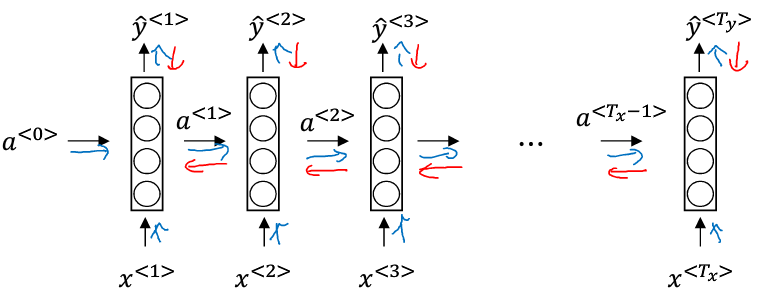
首先将第一个词Harry作为第一个输入(x),中间经过一堆隐藏层,然后输出(y);
接着将第二个词Potter作为第二个输入, 通用经过相同的隐藏层结构,获得输出。但这次,输入不但来自于第二个单词Potter,
还有一个来自上一个单词隐藏层中出来的信息(一般叫做激活值)(a)作为输入;
同理,接着是输入第3个词and, 同样也会输入来自第二个词的激活值;以此类推,直到最后一个词;
另外,第一个单词前面也需要一个激活值,这个可以人为编造,可以是0向量,也可以是用一些方法随机初始化的值。
词一个一个输入的,可以看成每个时间输入一次,所有输入的隐藏层是共享参数的。设输入层到隐藏层到参数为(W_{ax}),激活值到隐藏层到参数记为(W_{aa}).
根据以上结构,显而易见,第一次输入的单词会通过激活值影响下一个单词的预测,甚至影响接下去的所有单词的预测,这就是循环神经网络。
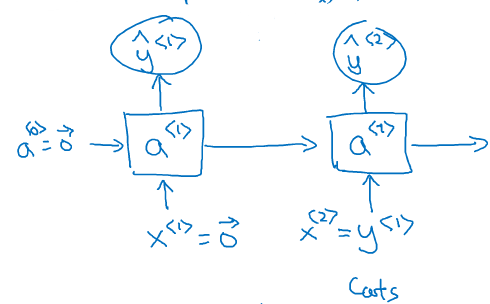
(3)前向传播
(a^{<0>})是人为初始化的到的;
(x^{<1>})是t=1时刻的输入;
输入层的权重是(W_{ax});
激活层的权重是(W_{aa});
输出层的权重是(W_{y1});
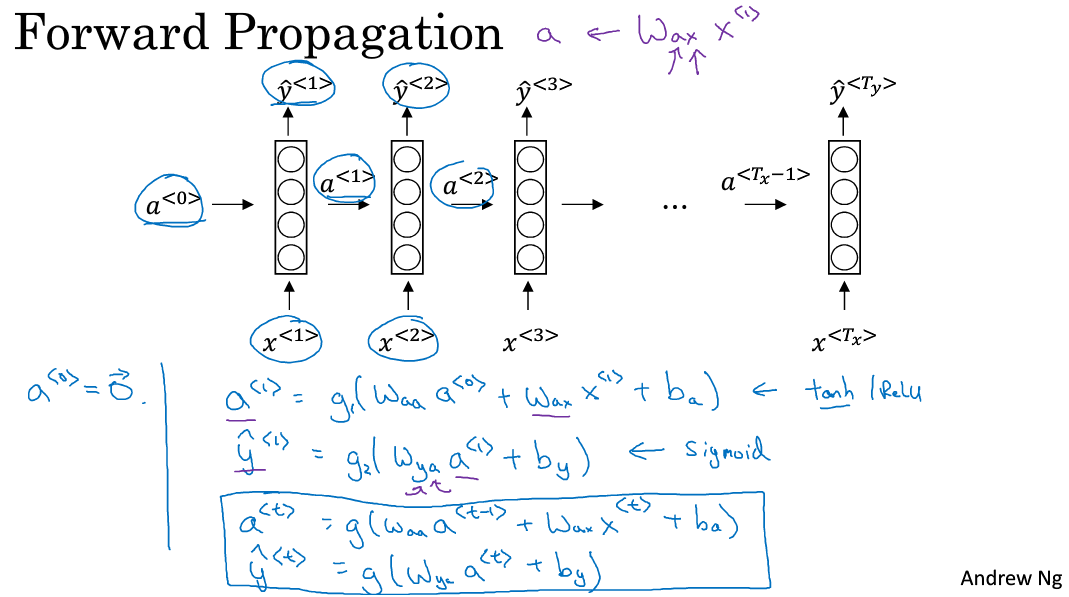
要计算的是每个时刻的激活值(a^{<t>})与输出值(y^{<t>})
(a^{<1>})的计算:
(hat{y}^{<1>})的计算
g()是一个激活函数,通常选用tanh,有时也是用relu用于避免梯度弥散。若是输出是2分类,往往采用sigmoid作为激活函数,因为本例中是要判别是否为实体店而分类,因此采用sigmoid函数。
扩展的一般情况(a^{<t>})与输出值(hat{y}^{<t>})如下计算:
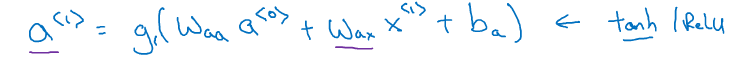
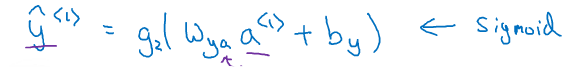
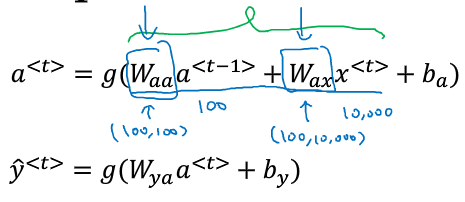
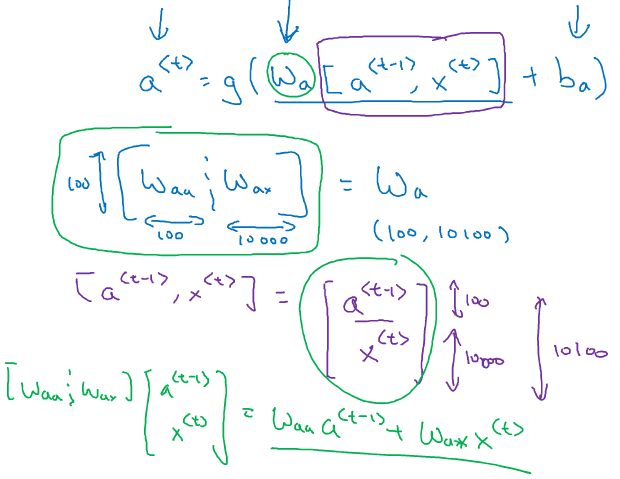
(4)简化RNN表示
其中(W_a)是(W_{aa})与(W_{ax})的左右拼接,若(W_{aa})纬度10010000,(W_{ax})纬度10010000,则组合后(W_{a})纬度是100*10100
同理第二个公式也简化成:
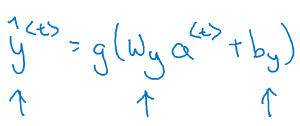
四.RNN中的时间反向传播
(1)回顾前向传播
回顾前向传播算法,有一个长度为(T_x)的序列
通过输入的(x),可以求出每一个时间上的激活值(a):
回顾上一节,时间(t)上的激活值(a)是由(t-1)时刻的(a),与(t)时刻的输入(x)乘以参数而得:
(a^{<t>}=g(W_{aa}a^{<t-1>}+W_{ax}x^{<t>}+b_a)) ====>>(a^{<t>}=g(W_{a}[a^{<t-1>},x^{<t>}]+b_a))
每一个时间上的运算都是共享一组参数(W_a),(W_b)的,如下:

接着,计算RNN的输出y:
同样,回顾y是通过当前时刻的激活值与参数相乘的到的:
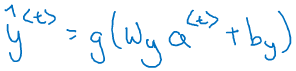
每一时刻的计算也是共享了一组参数(W_y)
于是前向传播就完成了。
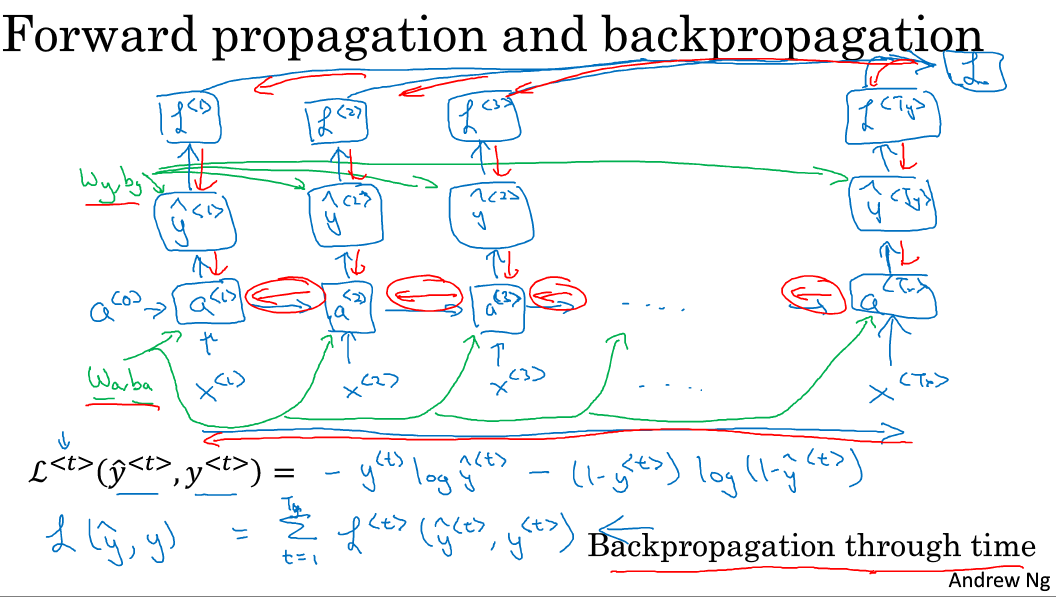
(2)损失函数 loss function
前向传播的过程是反向传播的基础, 而为了计算反向传播,还需要定义一个损失函数。
此处使用交叉熵损失函数
- 首先计算每个时间t上的损失,即计算序列中单次输入x,计算得到y的损失L( )
- 接着计算总的损失,即计算所有时间上的损失的总和
(3)反向传播
将损失函数对各个参数求导,利用梯度下降法更新参数,红色箭头表示反向传播的过程
在RNN中的反向传播亦叫时间反向传播back propogation through time
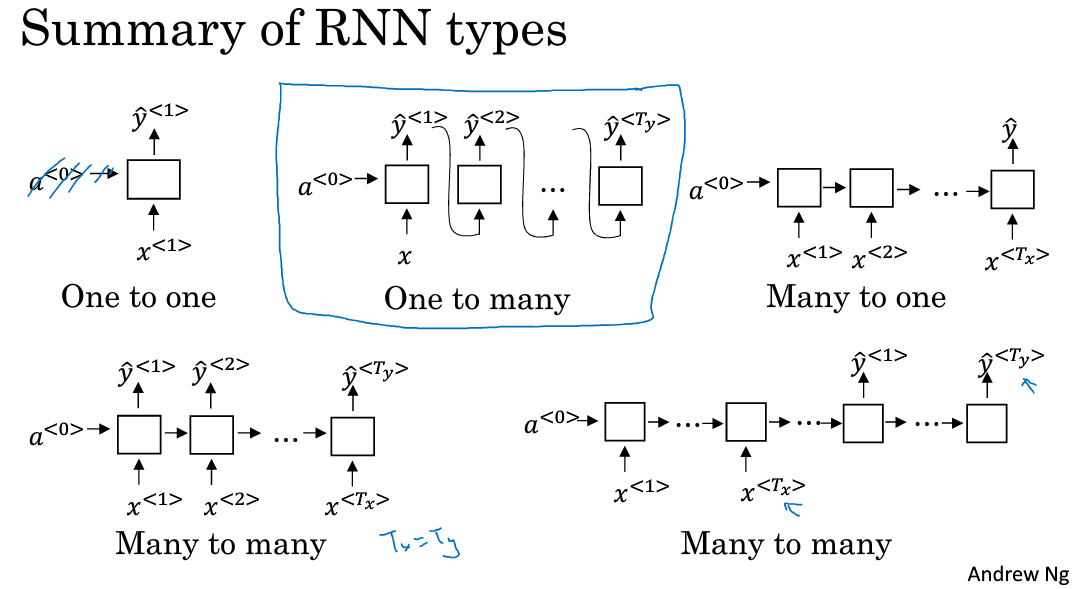
五.RNN的不同类型
(1)多对多
命名实体识别中,输入的序列与输出的序列都有多个元素,且长度相同,称之为many-to-many结构,多对多结构。
1】输入输出序列长度一致
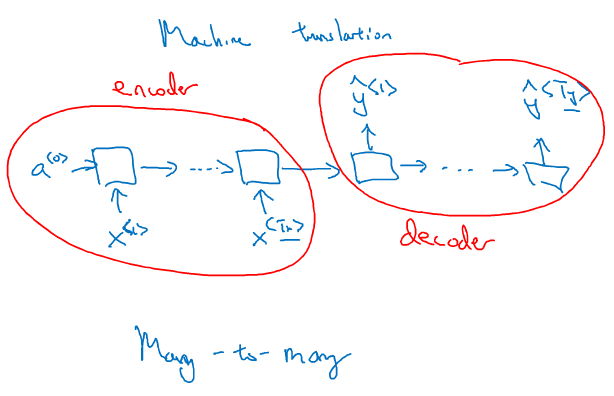
2】多对多也可以实现输入与输出序列长度不等的情况,最常见的是机器翻译,先来看看结构:
模型由2部分组成,前面一部分叫做encoder(编码), 将要翻译的文本序列逐次输入,但不产生输出;后一部分叫做decoder(解码),编码器的输出是解码器的输入,
而接下去的每个时间上都不再有输入,但每次都会有一个输出。解码器输出的序列就是对编码器输出序列的翻译。
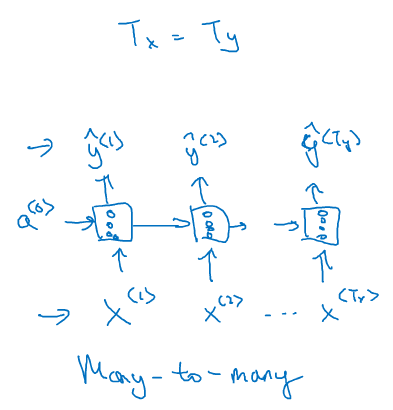
(2).多对一
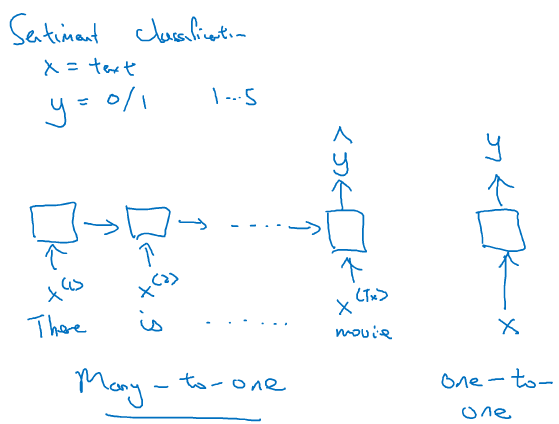
在文本情感分析中,输入的是文本的序列,每个词都是一个输入,而输出的往往是类别标签,比如给电影的评价等级分为5档,或者判别文章正面情感与负面情感的2档。
最后一个时间上会有y输出,而其他时间上都不再有y输出。这种结构叫做many-to-one结构,多对一结构。
(3).一对多
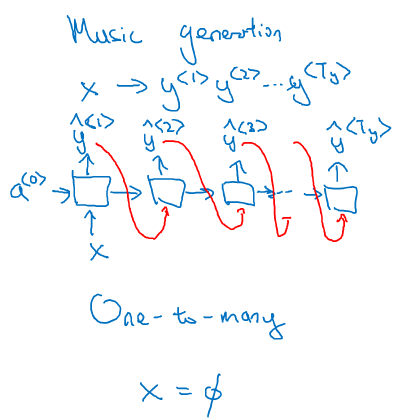
比如音乐生成的例子,输出的是一段音符的序列,而输入的可以是整数,表示你想要的音乐风格,或者是第一个音符,表示你想要用这个音符开头,或者什么都不输入,让模型自由发挥。
首先,只在第一个时间有输入x,其他时刻都没有;
其次,每一个时刻都会有输出,总的输出形成一个序列;
要注意的是,有一个技术细节,通常用RNN生成序列的时候,会把前一个时刻的输出y
(4).总结
六.语言模型与序列生成 Language model and sequence generation
(1)什么是语言模型?
比如speech recognition语音识别,即将声音识别成文字(国内语音识别做得不错的是科大讯飞)。
假如人说一句话“The apple and pear salad”,可以识别成以下两句话:
其中,pair与pear读音相同,显然第二句话才是正确识别说话人的意图。那要如何来选择最正确的句子呢?这就要用到语言模型了。
语言模型计算出两句话概率:
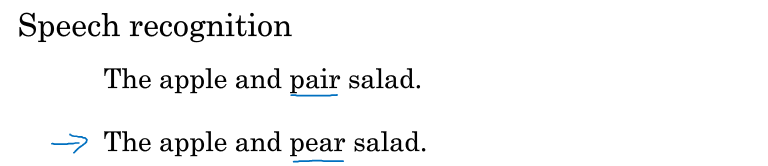
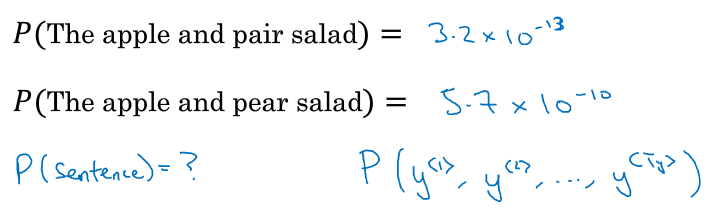
显然第二句的概率是第一句概率的近100倍,因此选择第二句话。也就是说语言模型会给你任何一句的概率,从而可以根据概率来选择最有可能正确的句子。
语言模型的应用目前有两大范畴,第一就是上面说的语音识别;第二就是机器翻译,同理,通过计算句子概率找到最正确的那句翻译。
(2)怎么建立用RNN建立语言模型呢?
1】首先要拥有一个训练集:巨大的语料库,越大越好
2】对语料库进行标记化,在前面几节中提高过,根据语料库整理出一个词典,并用one-hot的词向量表示每个词。有三个注意点:
A.一般会用
B.对于之后新的文本中出现了语料库中未出现过的词,则将其用
C.至于要不要将标点符号作为词典的一部分,这个看具体需求与问题来定夺。
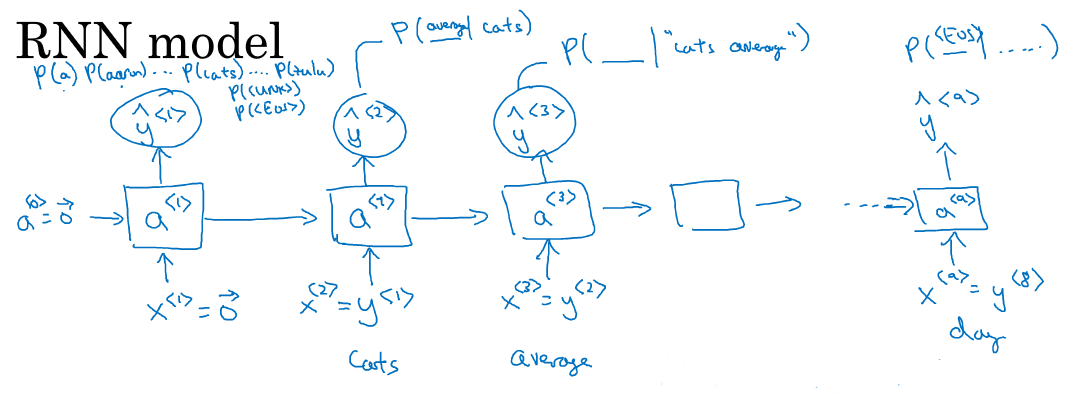
3】接着,建立RNN模型
假设有这样一句话:
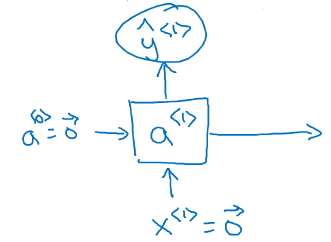
在第一个时间(t=1)时,输出的(x^{<1>})为0向量,因为第一个词之前没有词;激活值(a^{<0>})也初始化为0向量;如此计算后,得到的(y^{<1>})是softmaxt里出来的一个向量,
其长度为词典的长度,每一个位置上的值都是对应词典中的词的概率。注意字典也包括(<EOS>),与(<UNK>)
在第二个时间(t=2)时,输入的(x^{<2>})实际上就是第一个单词(y^{<1>}:cat);通过softmax计算,同样会得到词典长度的概率分布向量,这个概率是(P(Word / cat))即前面为单词cat时,
词典中每个词出现的条件概率。
以此类推,一直到最后一个时刻,输入的(x^{<9>}=y^{<8>}="day")。
4】计算损失函数
每次计算输出的概率分布时预测值,与实际值比较从而计算损失,对于单词次时刻,损失的公式为:
(i) 遍历词典,对词典中每个词的值进行汇总
总的损失,是所有时间上的损失的和:
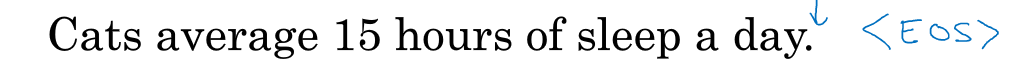
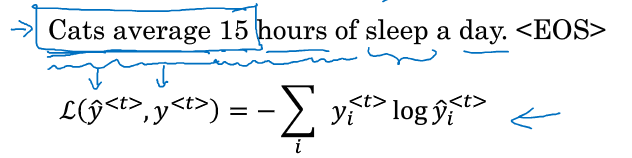
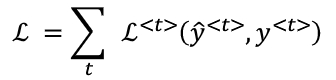
以上是关于序列模型第一课--循环序列模型的主要内容,如果未能解决你的问题,请参考以下文章