爬虫4
Posted helloqaz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫4相关的知识,希望对你有一定的参考价值。
? windows 1、打开文件资源管理器 2、地址栏输入 %appdata% 3、新建一个文件 pip.ini 4、编写指定的内容即可
linux 1、cd ~ 2、mkdir ~/.pip 3、vi ~/.pip/pip.conf 4、编辑内容和windows一样即可
? 使用: 步骤:首先通过BeautifulSoup这个类,将html格式的字符串转化为一个对象,然后根据对象的相关方法去查找指定的元素
(1)可以解析本地html文件 from bs4 import BeautifulSoup soup = BeautifulSoup(open(文件名, encoding=‘utf8‘), ‘lxml‘) lxml是一个文件解析器,需要安装 pip install lxml,如果指令安装失败,可以手动安装,去相关地址下载符合你环境的lxml,安装即可 html.parser 是python自带的一个解析器,lxml效率比这个高
(2)可以解析网络html文件 from bs4 import BeautifulSoup soup = BeautifulSoup(网页字符串内容, ‘lxml‘)
? 语法: (1)根据标签名查找 soup.a 查找第一个符合要求的节点,得到的是对象
(2)获取属性 soup.a.attrs 返回一个字典,里面是所有属性和值 soup.a[‘href‘] 获取单个属性
(3)获取内容 soup.a.string soup.a.text soup.a.get_text() 如果标签里面还有标签,那么string获取的是空,其它两个获取的是全部的纯文本内容
(4)find 返回一个对象 soup.find(‘a‘, id=‘xxx‘) soup.find(‘a‘, class_=‘xxx‘)
(5)find_all 返回一个列表,列表里面都是对象 soup.find_all(‘a‘, class_=‘xxx‘) soup.find_all(‘a‘, class_=‘xxx‘, limit=2) 取出前两个 soup.find_all([‘a‘, ‘p‘]) soup.find_all(‘a‘, class_=re.compile(r‘^love‘))
(6)select 选择-选择器 标签选择器 a 类选择器 .dudu id选择器 #dudu 属性选择器 input[type=radio] 伪类选择器 a:hover 通用选择器 * 后代选择器 div a h1 a是div的子节点、
子孙节点 div > a > h1 a是div的直接子节点 组合选择器 .dudu,#lala,div,p 兄弟选择器 ul + div 选择器作用:选择一批标签,然后将样式添加给他们 返回的永远是一个列表,列表里面都是符合要求的对象
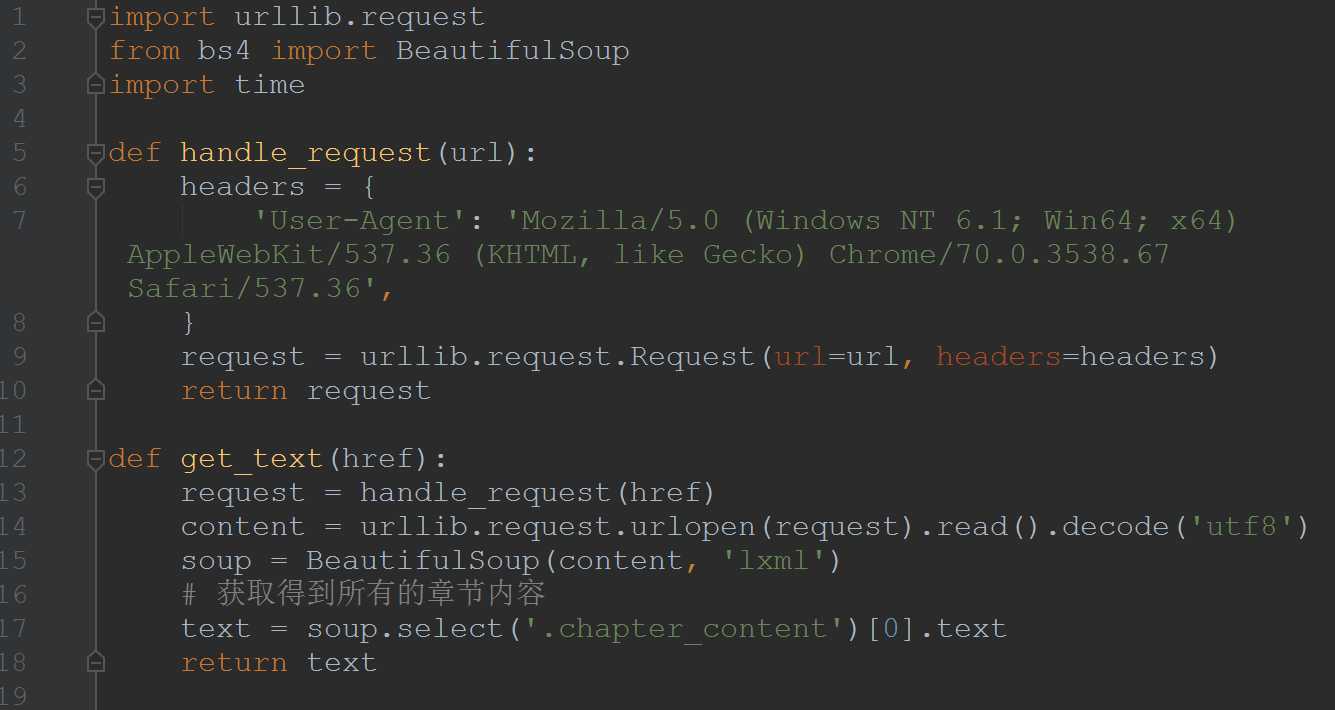
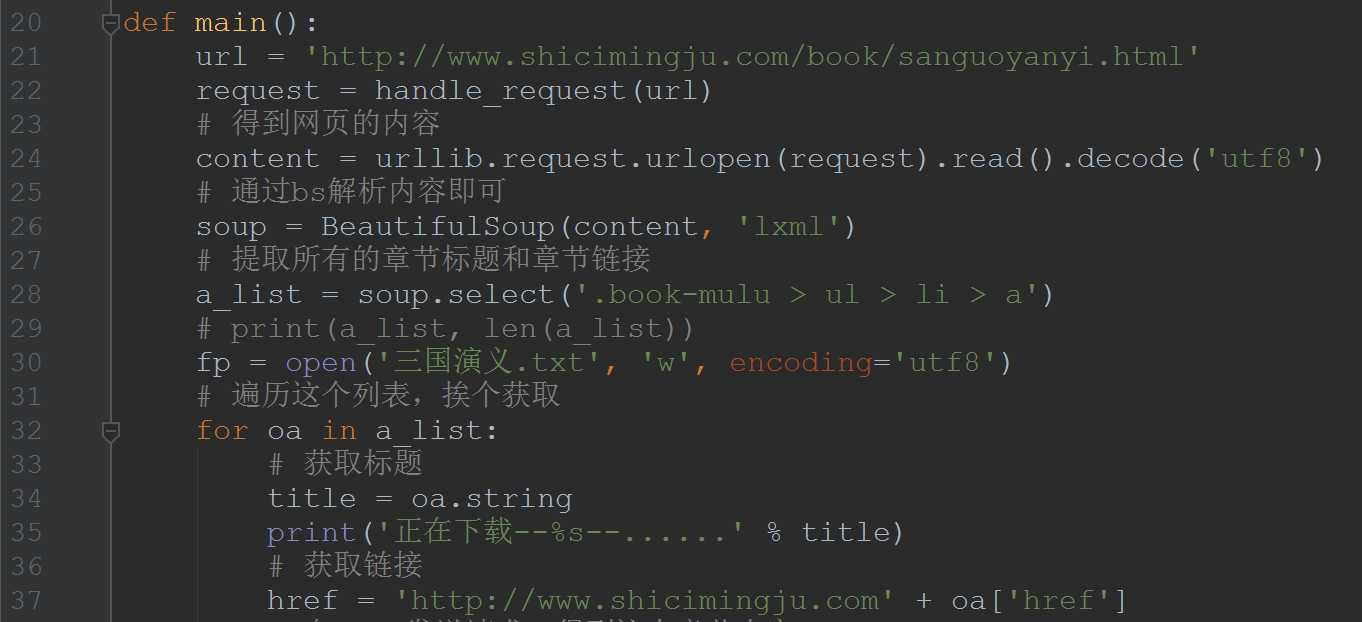
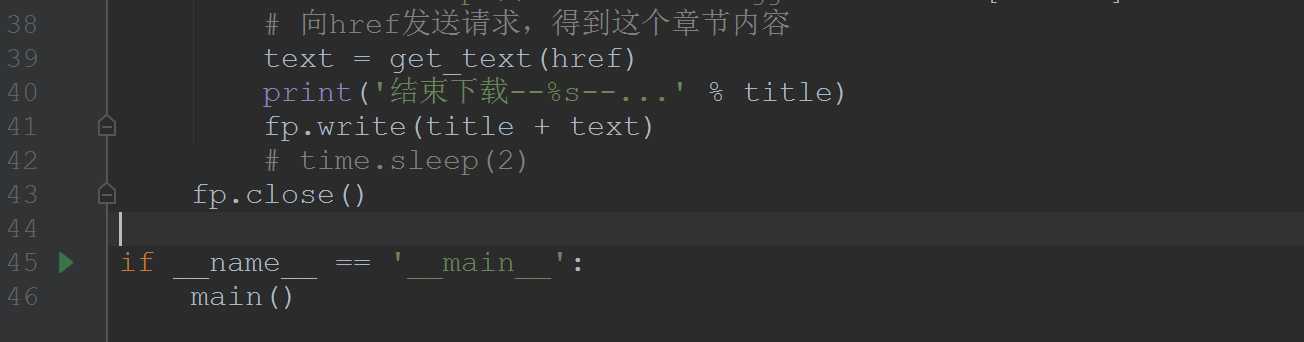
2、bs4实例
51job https://search.51job.com/list/020000,000000,0000,00,9,99,python,2,2.html 保存到mysql中 保存到mongodb中 数据库 数据库(database) 表格 集合(collection) 可视化界面工具 https://robomongo.org/download
3、xpath简介 xml是什么?
和json处在同一个位置,后端给前端传输数据的时候使用的数据格式,目前以json使用居多 xml:可扩展标记语言 html:超文本标记语言 不同:
(1)xml用来传输和存储数据,html用来显示数据 (2)xml标签可以自行定义,html不行
(3)xml是纯文本信息,html是超文本信息 xpath是什么?xpath是用来解析xml数据的 xpath和html有什么关系?因为xml和html的结构一模一样,
所以能不能使用xpath解析html数据呢?
能,有一个第三方库实现了这个功能,lxml pip install lxml 如何学习xpath
(1)根据xpath的教程学习xpath的基本语法 (2)学习xpath在html中的应用 (3)学习xpath在代码中的应用
以上是关于爬虫4的主要内容,如果未能解决你的问题,请参考以下文章