Gym
Posted treedream
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Gym相关的知识,希望对你有一定的参考价值。
用于研发与比较强化学习算法的工具。
安装
pip install gym
车杆问题,模型栗子CartPole-v0
env.step() ,传入0,1,表示车向左,右给1牛顿的力,现在要平衡这个车。
import gym env = gym.make(‘CartPole-v0‘) env.reset() for _ in range(1000): env.render() env.step(env.action_space.sample()) # take a random action
我们可以尝试一下,01010101,现实生活中,会让这根杆转起来,当然这不是我们平衡这个车的目标咯。
import numpy as np import random import gym ? env = gym.make(‘CartPole-v0‘) env.reset() s = 0 for _ in range(1000): env.render() env.step(s^1) s^=1
当然,我们可以切换场景,gym最重要的就是训练环境,有很多,有登山,走路的等等。
为达到我们平衡这个车杆的目标,我们可以设计我们自己的算法,当然我们需要知道当前车的状态,实际上step返回值有四个,包含了深度学习的常用概念。
-
observation :环境对象,和你选的环境有关,例如你选的机器人训练环境,他就是机器人的关节等信息。
-
reward:通过前面的action,你得到的奖励。(大小不一定和模型选择相关)
-
done:游戏是否结束,(例如杆的角度倾斜太大了)
-
info:用于调试的信息,然而,官方环境不允许使用。
这就是Gym的经典的"agent-environment loop" (代理环境循环)。如图所示:
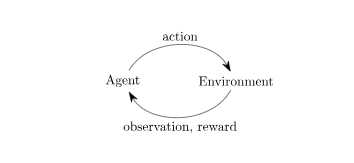

这个过程,首先reset(),返回一个环境对象。程序必须接受done方法,当满足done游戏结束标记,程序就退出。
【注】 render()重新绘制环境的一帧
import gym env = gym.make(‘CartPole-v0‘) for i_episode in range(20): observation = env.reset() for t in range(100): env.render() print(observation) action = env.action_space.sample() observation, reward, done, info = env.step(action) if done: print("Episode finished after {} timesteps".format(t+1)) break
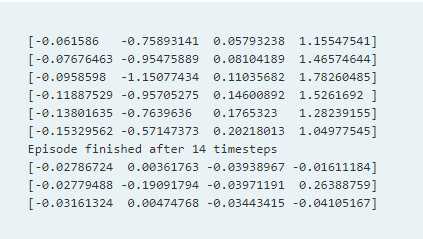
【注】这里我们打印了observation环境特性对象。

其含义,小车的位置,小车的速度,木棒的角度,木棒的速度。
-
Spaces(空间)
每一个环境都有 action_space,observation_space,他们的类型是Space,可以打印出来他们的属性。
import gym env = gym.make(‘CartPole-v0‘) print(env.action_space) #> Discrete(2) print(env.observation_space) #> Box(4,)
Discrete空间允许随机确定的非负数,在这个案例中就是0,1。Box空间代表问题的n维空间。我们查看一下他的环境特性属性,4个数字。
print(env.observation_space.high) #> array([ 2.4 , inf, 0.20943951, inf]) print(env.observation_space.low) #> array([-2.4 , -inf, -0.20943951, -inf])
这有助于通用代码的编写。在车杆问题中,你可以给左右的力,你知道这些数据的含义了吗?幸运的是,你的算法学的越好,你就越少解释这些数据的含义。
以上是关于Gym的主要内容,如果未能解决你的问题,请参考以下文章
解决使用Monitor出现gym.error.DependencyNotInstalled: Found neither the ffmpeg nor avconv executables的问题(代码