大数据(8l)运费分摊
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据(8l)运费分摊相关的知识,希望对你有一定的参考价值。
文章目录
问题描述
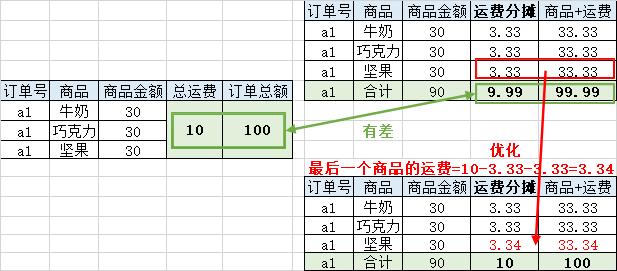
- 电商场景中,优惠、运费等是以订单为单位进行计算的
- 若要以商品维度进行分析,就要把优惠、运费等的效果分摊到每个商品
- 分摊方法:
分 摊 比 重 = 每 种 商 品 的 金 额 商 品 总 额 分摊比重=\\frac每种商品的金额商品总额 分摊比重=商品总额每种商品的金额 - 问题来了,由于除法有时除不尽,导致合计有差
- 改进方法:
最 后 一 种 商 品 分 摊 比 重 = 1 − 其 它 分 摊 比 重 累 加 最后一种商品分摊比重 = 1 - 其它分摊比重累加 最后一种商品分摊比重=1−其它分摊比重累加 - 判断是否最后一种商品:
商 品 总 额 − 已 经 分 摊 的 商 品 金 额 累 加 = = 商 品 金 额 商品总额 - 已经分摊的商品金额累加 == 商品金额 商品总额−已经分摊的商品金额累加==商品金额
Python实现
运费分摊
data = [
('a1', ['牛奶', '坚果', '蛋糕'], [30, 30, 30], 10, 100),
('a2', ['酸奶', '坚果', '蛋糕'], [60, 60, 60], 20, 200),
]
for 订单号, 订单商品, 订单商品金额, 运费, 订单总额 in data:
商品总额 = 订单总额 - 运费
已经分摊的商品金额累加 = 0
运费分摊累加 = 0
# 遍历每个商品,计算【运费分摊】
for 商品, 商品金额 in zip(订单商品, 订单商品金额):
# 判断是否为最后一个商品
if 商品总额 - 已经分摊的商品金额累加 == 商品金额:
运费分摊 = 运费 - 运费分摊累加
else:
运费分摊 = round(商品金额 / 商品总额 * 运费, 2)
已经分摊的商品金额累加 += 商品金额
运费分摊累加 += 运费分摊
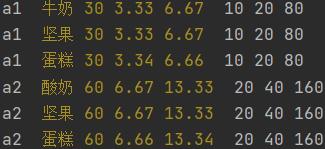
print(订单号, '\\033[033m', 商品, 商品金额, 运费分摊, '\\033[0m', 运费, 订单总额)
运费和优惠分摊
data = [
('a1', ['牛奶', '坚果', '蛋糕'], [30, 30, 30], 10, 20, 80),
('a2', ['酸奶', '坚果', '蛋糕'], [60, 60, 60], 20, 40, 160),
]
for 订单号, 订单商品, 订单商品金额, 运费, 优惠, 订单总额 in data:
商品总额 = 订单总额 - 运费 + 优惠
已经分摊的商品金额累加 = 0
运费分摊累加 = 0
优惠分摊累加 = 0
# 遍历每个商品,计算【运费分摊】
for 商品, 商品金额 in zip(订单商品, 订单商品金额):
# 判断是否为最后一个商品
if 商品总额 - 已经分摊的商品金额累加 == 商品金额:
运费分摊 = 运费 - 运费分摊累加
优惠分摊 = 优惠 - 优惠分摊累加
else:
已经分摊的商品金额累加 += 商品金额
运费分摊 = round(商品金额 / 商品总额 * 运费, 2)
运费分摊累加 += 运费分摊
优惠分摊 = round(商品金额 / 商品总额 * 优惠, 2)
优惠分摊累加 += 优惠分摊
print(订单号, '\\033[033m', 商品, 商品金额, 运费分摊, 优惠分摊, '\\033[0m', 运费, 优惠, 订单总额)
打印
HIVE实现
--删库
DROP DATABASE IF EXISTS sale CASCADE;
--建库
CREATE DATABASE sale LOCATION '/sale';
USE sale;
--建表
CREATE TABLE good(
order_number STRING COMMENT "订单号",
good STRING COMMENT "商品",
good_costs INT COMMENT "商品金额",
goods_costs INT COMMENT "商品总额",
transport_costs INT COMMENT "运费",
costs INT COMMENT "订单总额"
)COMMENT "商品分析"
LOCATION '/sale/good';
--插数据
INSERT INTO TABLE good VALUES
('a1','牛奶',3000,9000,1000,10000),
('a1','坚果',3000,9000,1000,10000),
('a1','蛋糕',3000,9000,1000,10000),
('a2','酸奶',6000,18000,2000,20000),
('a2','坚果',6000,18000,2000,20000),
('a2','蛋糕',6000,18000,2000,20000);
--查看
SELECT * FROM good;
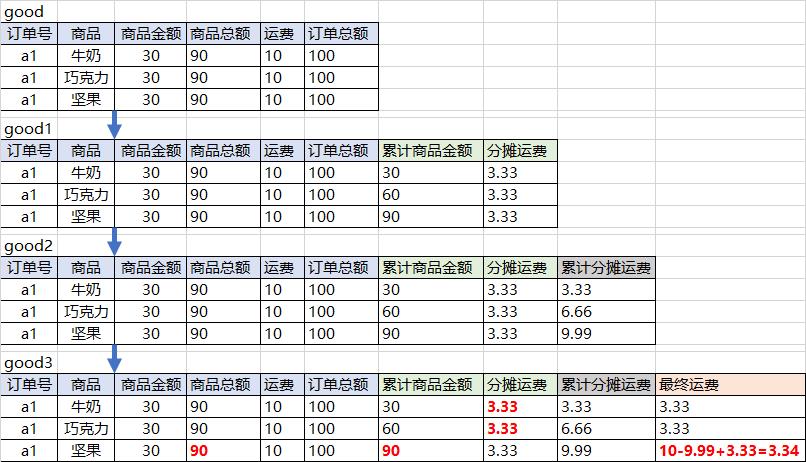
good1
CREATE VIEW good1 AS
SELECT
*,
SUM(good_costs) OVER(PARTITION BY order_number ORDER BY good)
AS good_accumulation, -- 累计商品金额
ROUND(good_costs/goods_costs*transport_costs)
AS transport_share -- 分摊运费
FROM good;
good2
CREATE VIEW good2 AS
SELECT
*,
SUM(transport_share) OVER(PARTITION BY order_number ORDER BY good)
AS transport_share_accumulation -- 累计分摊运费
FROM good1;
good3
CREATE VIEW good3 AS
SELECT
*,
IF(goods_costs==good_accumulation,transport_costs-transport_share_accumulation+transport_share,transport_share)
AS transport_share_final -- 最终分摊运费
FROM good2;
123合体
SELECT
*,
IF(
goods_costs==good_accumulation,
transport_costs-transport_share_accumulation+transport_share,
transport_share)
AS transport_share_final -- 最终分摊运费
FROM (
SELECT
*,
SUM(good_costs) OVER(PARTITION BY order_number ORDER BY good)
AS good_accumulation, -- 累计商品金额
ROUND(good_costs/goods_costs*transport_costs)
AS transport_share, -- 分摊运费
SUM(ROUND(good_costs/goods_costs*transport_costs))
OVER(PARTITION BY order_number ORDER BY good)
AS transport_share_accumulation -- 累计分摊运费
FROM good
)t;
Spark实现
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object Hello
def main(args: Array[String]): Unit =
// 创建SparkSession对象
val c1: SparkConf = new SparkConf().setAppName("a1").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(c1).getOrCreate()
// 隐式转换支持
import spark.implicits._
// 创建数据
val df = Seq(
("a1", "牛奶", 3000, 9000, 1000, 10000),
("a1", "坚果", 3000, 9000, 1000, 10000),
("a1", "蛋糕", 3000, 9000, 1000, 10000),
("a2", "酸奶", 6000, 18000, 2000, 20000),
("a2", "坚果", 6000, 18000, 2000, 20000),
("a2", "蛋糕", 6000, 18000, 2000, 20000)
).toDF("order_number", "good", "good_costs", "goods_costs", "transport_costs", "costs"
).sort("order_number")
// 创建视图
df.createTempView("good")
// 累计商品金额、分摊运费、累计分摊运费
spark.sql(
"""
|SELECT
| *,
| SUM(good_costs) OVER(PARTITION BY order_number ORDER BY good)
| AS good_accumulation, -- 累计商品金额
| ROUND(good_costs/goods_costs*transport_costs)
| AS transport_share, -- 分摊运费
| SUM(ROUND(good_costs/goods_costs*transport_costs))
| OVER(PARTITION BY order_number ORDER BY good)
| AS transport_share_accumulation -- 累计分摊运费
|FROM good
|""".stripMargin).createTempView("good1")
// 最终分摊运费
spark.sql(
"""
|SELECT
| *,
| IF(
| goods_costs==good_accumulation,
| transport_costs-transport_share_accumulation+transport_share,
| transport_share)
| AS transport_share_final -- 最终分摊运费
|FROM good1;
|""".stripMargin).show()
结果打印

以上是关于大数据(8l)运费分摊的主要内容,如果未能解决你的问题,请参考以下文章