用户画像大数据之用户画像的原理应用与实现
Posted 魏晓蕾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用户画像大数据之用户画像的原理应用与实现相关的知识,希望对你有一定的参考价值。
什么是用户画像
用户画像:通过各个维度对用户或者产品特征属性的刻画,并对这些特征分析统计挖掘潜在价值信息。完美地抽象出一个用户的信息全貌,可以看作企业应用大数据的根基。用户画像使用标签来量化用户特征属性,达到描述用户的目的。用户画像是对现实世界中的用户进行建模。用户画像是描述用户的数据, 是符合特定业务需求的对用户的形式化描述。
用户画像,即用户信息标签化。企业通过收集与分析消费者个人属性、社会属性、生活习惯、消费行为等主要信息的数据之后,完美地抽象出一个用户的商业全貌。
用户画像为企业提供了足够的信息基础,能够帮助企业快速找到精准用户群体以及精准用户需求等更为广泛的反馈信息,来进行各种精准营销。
分析的维度:可以按照人口属性和产品行为属性进行综合分析。
- 人口属性:地域、年龄、性别、文化、职业、收入、生活习惯、消费习惯等;
- 产品行为属性:产品类别、活跃频率、产品喜好、产品驱动、使用习惯、产品消费等。
用户画像的本质
专业术语:人物角色
企业使用术语:用户画像
技术原理:数据清理、分析、统计、打标签、用户信息标签化
为什么使用用户画像
在互联网进入大数据时代后,给企业及消费者行为带来一系列改变,其中最大的变化,是消费者的一切行为在企业面前是“可视化”的。随着大数据技术的迅速发展、深入研究和广泛应用,企业的专注点日益聚焦于怎样利用大数据来进行精准营销等服务,以及进一步深入挖掘潜在的商业价值,“用户画像”的概念也因此应运而生。
用户画像的核心工作是为用户打标签,打标签的重要目的之一是为了让人能够理解并且方便计算机处理,如,可以做分类统计:喜欢红酒的用户有多少?喜欢红酒的人群中,男、女比例是多少?也可以做数据挖掘工作:利用关联规则计算,喜欢红酒的人通常喜欢什么运动品牌?利用聚类算法分析,喜欢红酒的人年龄段分布情况?
大数据处理,离不开计算机的运算,标签提供了一种便捷的方式,使得计算机能够程序化处理与人相关的信息,甚至通过算法、模型能够“理解” 人。当计算机具备这样的能力后,无论是搜索引擎、推荐引擎、广告投放等各种应用领域,都将能进一步提升精准度,提高信息获取的效率。
用户画像打标签
一个标签通常是人为规定的高度精炼的特征标识:
- 年龄段标签:25~35岁
- 地域标签:北京
标签特性:
- 语义化:能很方便的理解每个标签的含义
- 短文本:每个标签只代表一种含义
如何创建用户画像
- 数据收集
基础用户注册信息:性别,年龄,地区
用户行为数据:浏览,关注,活跃度
用户评价:喜好,期望
历史数据:日志 - 亲和图、确定类型
把大量收集到的事实、意见或构思等定性资料,按其相近性进行归纳整理的一种方法。手动列出大标签,品类或者数据聚类的过程。例如:屌丝、IT男、java、hadoop、技术宅。
用户画像分类
精确用户属性标签画像:
- 用户基础属性画像
- 用户的喜好偏向
- 用户拓展信息画像
- 单个信息的集合
概况画像
- 用户来源画像:我们需要有一个来源分类,并对不同分类打标签,例如:直接访问、搜索引擎、广告营销、移动APP
- 用户浏览行为画像:行为标签,分析用户热点区域连接
- 实时订单画像:不同来源用户的订单画像
- 订单转化率画像:各个来源客户的访问和最终购买的比例
- 访客画像群体画像
- 实时打标签
- 实时订单种类
流量趋势画像
- 访客趋势(访客每日的访问量)
- 浏览趋势(浏览量每日趋势)
- 新访客趋势(新访客每日访问趋势)
- 活跃访客趋势(活跃访客每日访问趋势)
- 访问量(每日、每周、每月)
页面画像
- 受访画像(各品类页面访问量统计)
- 进入画像(访客从哪些页面进入网站)
- 离开画像(访客从哪些页面离开网站)
- 页面热点图(优化网页设计)
- 访问标记(访客在页面上点击哪些内容或者id元素)
- 主机域名(网站子域名访问量)
- 访问目录(网站子目录访问量)
- 外链网站(访客点击哪些站外链接离开网站)
行为分析画像
- 跳出率(访问行为评估)
- 忠诚度(访问质量评估)
- 活跃度(活跃度、流失分析)
- 用户关联度聚类画像(用户与用户之间的关系)
- 新用户画像(吸引新用户注册因素画像)
- 访客浏览路径热点画像(用户浏览习惯调研)
访客画像
- 地域分析(访客地域位置的分布)
- 速度分析(访客访问网站的速度分析)
- 客户端环境(访问客户端分析)
- 设备属性画像(使用硬件信息)
- 移动终端(访客上网设备分析)
- 网络连接画像(不同网络的连接方式运营商)
会员画像
- 性别画像(性格的占比)
- 年龄分布画像(按标准年龄段的正态分布)
- 教育背景画像(教育背景)
- 职业分布画像(职业背景)
- 特征分布画像(多标签特征库,购物狂,游戏迷)
- 会员游客画像(详细信息画像)
- 匿名用户画像(会员不详细用户画像)
用户来源画像
- 来源分类(直接输入、搜索引擎、本域来路、外域来路)
- 来源网站(网站统计)
- 来源页面(网站链接)
- 直接访问(浏览器直接进去)
- 搜索引擎(具体的搜索引擎画像)
- 搜索关键词(热点关键词画像)
- 广告营销(通过广告进入)
- 移动APP(移动数据入口)
广告营销画像
- 广告分析(普通广告来源分析)
- SEM分析(竞价搜索来源分析)
- EDM分析(邮件来源分析)
- 有效性价值画像(有效广告,转化率)
- 免费搜索(SEO 关键词优化)
- 付费搜索(SEO 关键词优化)
- 推荐链接(友情链接)
- 微博类媒介(浏览量传播效果评估)
- 论坛评论、软文画像(浏览量)
- 用户点击区域分布画像(地理区域分布)
APP 画像
- 应用属性画像(名字、版本、设备信息、(核心软件、系统))
- 基础指标(累积启动次数、启动用户、新增用户、人均启动次数、平均使用时长)
- 在线分析(流量消耗、活跃用户)
- 内容分析(页面,菜单使用热度)
- 使用时段画像(均匀负载)
- 使用间隔画像(用户使用频率)
- 错误画像(程序错误自动报告系统)
商品画像
- 商品的品类数量画像(不同品类数量及占比)
- 单品关联度画像(同类热门产品)
- 点击量、收藏量
- 购买量、退货量
- 品牌以及活动组画像(活动产品的浏览购买)
- 品类热门产品画像(品类的topN)
订单画像
- 订单趋势(订单每日、每星期、每月)
- 订单集中度(支付方式、价格区间、退单率)
- 商家占比折扣
- 单价比
- 利润值
用户画像应用场景
网站指标画像
- 网站的指标画像,对网站性能负载进行综合调整、评估、优化
- PV(Page View,浏览量)
- UV(unique visitor,独立访客)
- IP(独立ip)
- PR(即Page Rank),网页的级别重要程度
- 响应时间、各级页面平均停留时间
- 浏览量、跳出率、跳转次数、回头率
社交用户画像
- 有很多社交的注册用户,为了增加用户之间的社交文化,对每一个用户进行画像,根据画像做好友推荐
- 所在地
- 故乡
- 性别
- 年龄
- 在线
- 附近距离
用户群体画像
- 对不同职业,不同技术的不同背景的用户群体分析画像
- 所在地
- 年龄阶段分类
- 职业岗位分类
- 消费群体分类
- 薪资分类
- 目标客户细分
广告推荐
- 广告推荐核心技术是推荐引擎,角色(用户)画像是广告推荐引擎的一部分
- 物品信息画像(对于内容的识别、关键字)
- 用户对物品的偏好(评分、查看、购买等)
- 协同过滤相似度推荐(画像标签相似度推荐)
- 总量性指标(包括广告的费用与频次)
- 趋势性指标(企业投放力度的变化情况)
- 转化率指标(消费者对广告的投放点击率)
- 访问者成本(总的广告费用除以独立访问者数量)
- 进入页面的跳出率(进入广告直接退出)
电商类推荐
- 根据用户喜好推荐相关用户喜欢的产品
- 关键字(根据关键字匹配用户想找的物品)
- 浏览量(关键词品类浏览热点)
- 销量(关键词品类销量画像)
- 价格(关键词商品的价格排序)
- 用户购买喜好(用户购买聚类画像)
- 活动推广商品画像(广告指标画像)
资讯类推荐
- 根据用户主动订阅或者浏览次数频率,对用户喜欢画像,进行资讯推荐
- 订阅
- 热门推荐
- 最新推荐
- 浏览品类次数统计
- 浏览的频率推荐
- 关键词推荐
视频类推荐
- 视频网站有大量的视频,怎样让用户找到用户感兴趣的视频,需要对用户喜欢做精确的画像,提高用户的体验
- 基础画像(对用户注册信息画像)
- 用户播放历史画像(用户关键词,影片画像)
- 播放指标画像(最新的,最热的,播放量)
- 视频质量画像(用户观看质量,观看时间)
- 视频相关度画像(每个视频相关视频TOP N)
- 推荐营销视频画像
- 用户热点画像
用户金融信誉等级画像
- 互联网金融大数据,需要对用户信用等级做评估,就需要对用户信用画像
- 恶意贷款负债画像
- 用户固有资产画像(车、房产、企业信誉)
- 用户经济能力画像(工资、纳税额)
- 用户消费能力画像(购买消费)
- 用户关系圈画像(职称、朋友信用等级)
- 用户互联网画像(微博、微信)
- 标准用户画像(用户信用区间等级评定)
移动电信集中监管系统画像
- 移动电信集中监管系统画像是对用户的通信数据等各种指标进行画像分析
供销存画像
传感器数据分析画像
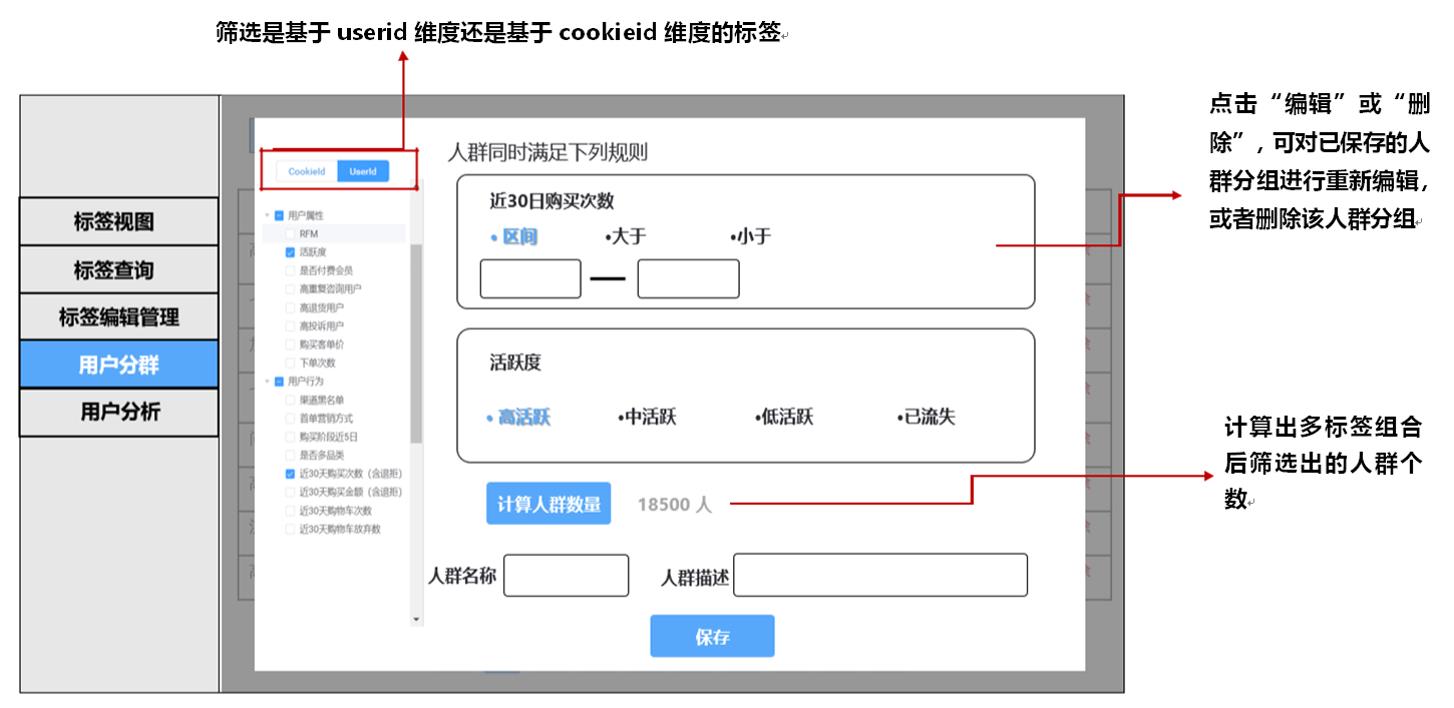
用户画像实现
建日全量表
CREATE TABLE dw.userprofile_tag_userid (
tagid STRING COMMENT 'tagid',
userid STRING COMMENT 'userid',
tagweight STRING COMMENT 'tagweight',
reserve STRING COMMENT '预留')
PARTITIONED BY (data_date STRING COMMENT '数据日期', tagtype STRING COMMENT '标签主题分类')
建日增量表
CREATE TABLE dw.userprofile_useract_tag (
tagid STRING COMMENT '标签id',
userid STRING COMMENT '用户id',
act_cnt int COMMENT '行为次数',
tag_type_id int COMMENT '标签类型编码',
act_type_id int COMMENT '行为类型编码')
COMMENT '用户画像-用户行为标签表'
PARTITIONED BY (data_date STRING COMMENT '数据日期')
标签元数据
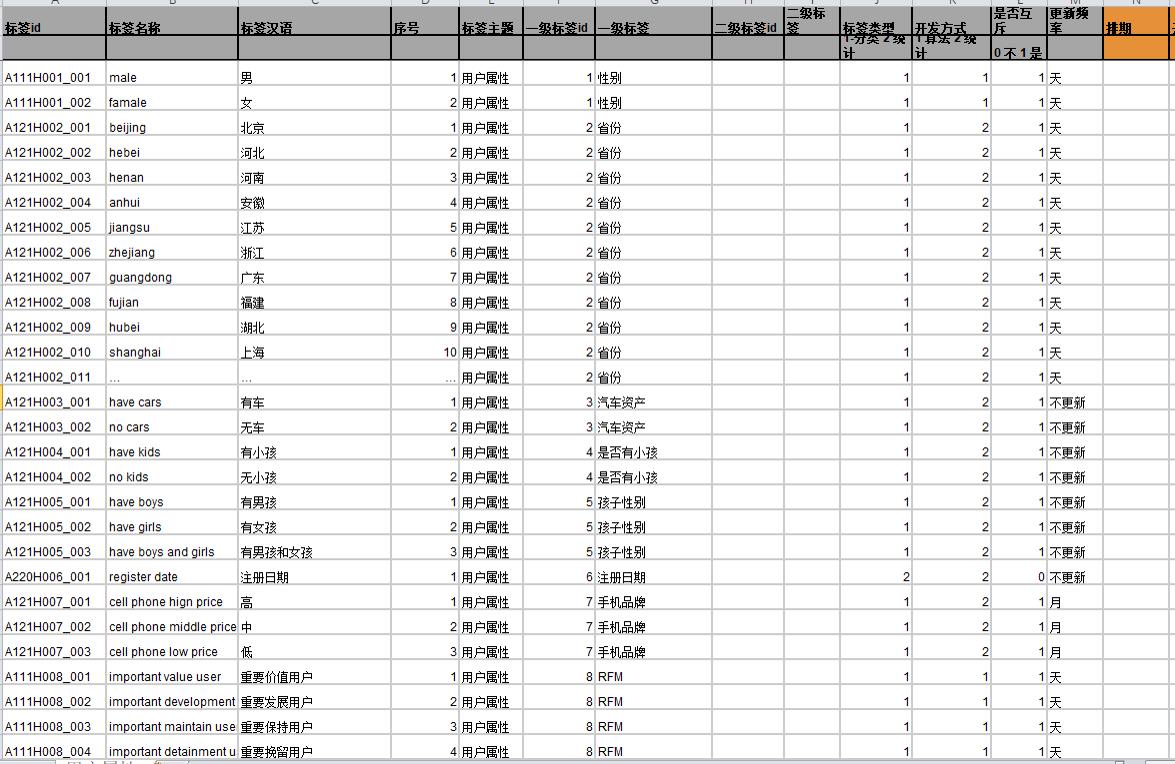
标签分类
- 统计类标签:最为基础也最为常见的标签类型
- 规则类标签:基于用户行为及确定的规则产生
- 机器学习挖掘类标签:通过数据挖掘产生,应用在对用户的某些属性或某些行为进行预测判断
集群架构
| 服务名称 | 子服务 | 服务器1 | 服务器2 | 服务器3 |
|---|---|---|---|---|
| HDFS | NameNode | √ | ||
| DataNode | √ | √ | √ | |
| SecondaryNameNode | √ | |||
| Yarn | ResourceManager | √ | ||
| NodeManager | √ | √ | √ | |
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Flume(采集日志) | Flume | √ | √ | |
| Kafka | Kafka | √ | √ | √ |
| Flume(消费Kafka) | Flume | √ | ||
| Hive | Hive | √ | ||
| mysql | MySQL | √ | ||
| Sqoop | Sqoop | √ | ||
| Spark | Spark | √ |

用户画像标签存储
- MySQL 存储画像标签相关的元数据
- Hive存储标签相关数据的计算结果
数据库建表
- 创建用户标签表
CREATE TABLE dw.profile_tag_userid (
tagid STRING COMMENT 'tagid',
userid STRING COMMENT 'userid',
tagweight STRING COMMENT 'tagweight',
reserve1 STRING COMMENT '预留1',
reserve2 STRING COMMENT '预留2',
reserve3 STRING COMMENT '预留3')
PARTITIONED BY (data_date STRING COMMENT '数据日期', tagtype STRING COMMENT '标签主题分类')
- 向用户标签表添加记录
insert into table dw.profile_tag_userid partition(data_date='20180421', tagtype='user_install_days') values ('A220U029_001', '25083679', '282', '', '', '');
insert into table dw.profile_tag_userid partition(data_date='20180421', tagtype='user_install_days') values ('A220U029_001', '7306783', '166', '', '', '');
insert into table dw.profile_tag_userid partition(data_date='20180421', tagtype='user_install_days') values ('A220U029_001', '4212236', '458', '', '', '');
insert into table dw.profile_tag_userid partition(data_date='20180421', tagtype='user_install_days') values ('A220U029_001', '39730187', '22', '', '', '');
- 创建聚合表
CREATE TABLE `dw.profile_user_map_userid` (
`userid` string COMMENT 'userid',
`tagsmap` map<string, string> COMMENT 'tagsmap',
`reserve1` string COMMENT '预留1',
`reserve2` string COMMENT '预留2')
COMMENT 'userid 用户画像数据'
PARTITIONED BY (`data_date` string COMMENT '数据日期')
insert overwrite table dw.profile_user_map_userid partition(data_date='20180910')
select userid, str_to_map(concat_ws(','collect_set(concat(tagid, ':', tagweight)))) as tagsmap, '', ''
from dw.profile_tag_userid
where data_date='20180910'
group by userid
CREATE TABLE `dw.profile_user_map_cookieid` (
`cookieid` string COMMENT 'tagid',
`tagsmap` map<string, string> COMMENT 'cookieid',
`reserve1` string COMMENT '预留1',
`reserve2` string COMMENT '预留2')
COMMENT 'cookie 用户画像数据'
PARTITIONED BY (`data_date` string COMMENT '数据日期')
- 创建用户人群表
CREATE TABLE `dw.profile_usergroup_tag` (
`userid` string,
`tagsmap` map<string, string>,
`reserve1` string,
`reserve2` string)
COMMENT 'cookie 用户画像数据'
PARTITIONED BY (`data_date` string, `target` string)
select t1.userid, t2.order_sn, t3.tel
from $tablename t1
inner join dw.paid_order_fact t2
on t1.userid = t2.user_id
inner join dw.order_user_info t3
on t2.order_id = t3.order_id
where t1.data_date = '$data_date'
and t1.target = '100000207486'
group by t1.userid, t3.tel
having t3.tel <> ''
- 标签监控

统计标签的开发:用户退货率标签开发
- 计算出近30天内的订单量
- 计算出近30天内的退货量
- 近30天内的退货率=订单量/退货量
## userprofile_userid_return_goods_rate.py
# 用户近30日订单量
user_paid_30_orders = "select t1.user_id, count(distinct t1.order_id) as paid_orders
from dw.dw_order_fact t1
where t1.pay_status in (1,3)
and concat(substr(t1.pay_time,1,4),substr(t1.pay_time,6,2),substr(t1.pay_time,9,2)) >= "+"'"+month_day_ago_1+"'"+" \\
and concat(substr(t1.pay_time,1,4),substr(t1.pay_time,6,2),substr(t1.pay_time,9,2)) <= "+"'"+start_date_str+"'"+" \\
group by t1.user_id "
# 用户近30日订单退货量
user_paid_30_return="select t1.user_id, count(distinct t1.returned_order_id) as returned_orders
from who_wms_returned_order_info t1
inner join dw.dw_order_fact t2
on (t1.user_id = t2.user_id and t1.returned_order_id = t2.order_id)
where t1.return_status in (0,1,2,3,4,5,6,7,8)
and t1.site_id in (0,1)
and from_unixtime(t1.returned_time,'yyyyMMdd') >= "+"'"+month_day_ago_1+"'"+"
and from_unixtime(t1.returned_time,'yyyyMMdd') <= "+"'"+start_date_str+"'"+"
and t2.pay_status in (1,3)
and concat(substr(t2.pay_time,1,4),substr(t2.pay_time,6,2),substr(t2.pay_time,9,2)) >= "+"'"+month_day_ago_1+"'"+"
and concat(substr(t2.pay_time,1,4),substr(t2.pay_time,6,2),substr(t2.pay_time,9,2)) <= "+"'"+start_date_str+"'"+"
group by t1.user_id "
user_paid_30_rate = "insert overwrite table " +target_table+" partition(data_date ="+"'"+start_date_str+"'"+",tagtype='return_goods_rate')
select 'B220U071_001' as tagid,
t.user_id as userid,
round(t.returned_orders/t.paid_orders, 2) as tagweight,
'' as tagranking,
'' as reserve,
'' as reserve1
from (
select nvl(t2.user_id,t1.user_id) as user_id,
nvl(t2.returned_orders, 0) as returned_orders,
t1.paid_orders
from user_paid_30_orders t1
full outer join user_paid_30_return t2
on t1.user_id = t2.user_id
) t
group by 'B220U071_001',
t.user_id,
round(t.returned_orders/t.paid_orders, 2),
'','','' "
spark = SparkSession.builder.appName("userid_return_goods_rate").enableHiveSupport().getOrCreate()
returned_df1 = spark.sql(user_paid_30_orders).cache()
returned_df1.createTempView("user_paid_30_orders")
returned_df2 = spark.sql(user_paid_30_return).cache()
returned_df2.createTempView("user_paid_30_return")
spark.sql(user_paid_30_rate)
规则类标签开发:RFM模型标签开发
- 计算出消费的最近时间、频率、金额
- 根据消费的最近时间、频率、金额,综合得到用户的价值、保持、发展、挽留的程度,如“一般”还是“重要”
## userprofile_userid_RFM_value.py
# A111U008_001 重要价值用户
# A111U008_002 重要保持用户
# A111U008_003 重要发展用户
# A111U008_004 重要挽留用户
# A111U008_005 一般价值用户
# A111U008_006 一般保持用户
# A111U008_007 一般发展用户
# A111U008_008 一般挽留用户
# 用户RFM维度数据 (用户最后一次购买时间非空)
user_rfm_info = "select 。。。 "
// date_str:昨天的日期
user_rfm = " select user_id, \\
// 计算出Recency:最近一次消费
case when datediff("+"'"+date_str+"'"+",last_pay_date)<90 then '近' \\
else '远' end as date_diff,
// 计算出Frequency:消费的频率,忠诚度
\\
case when last_1y_paid_orders <3 then '低频' \\
else '高频' end as sum_orders,
// 计算出Monetary:消费金额
\\
case when last_1y_paid_order_amount <50 then '低额' \\
else '高额' end as sum_amount \\
from user_rfm_info \\
where country = 'ID' \\
union all \\
select user_id, \\
case when datediff("+"'"+date_str+"'"+",last_pay_date)<90 then '近' \\
else '远' end as date_diff, \\
case when last_1y_paid_orders <3 then '低频' \\
else '高频' end as sum_orders, \\
case when last_1y_paid_order_amount <300 then '低额' \\
else '高额' end as sum_amount \\
from user_rfm_info \\
where country <> 'ID' "
insert_table = "insert overwrite table " + target_table + " partition(data_date="+"'"+start_date_str+"'"+",tagtype='rfm_model') \\
select case when date_diff = '近' and sum_orders = '高频' and sum_amount = '高额' then 'A111U008_001' \\
when date_diff = '远' and sum_orders = '高频' and sum_amount = '高额' then 'A111U008_002' \\
when date_diff = '近' and sum_orders = '低频' and sum_amount = '高额' then 'A111U008_003' \\
when date_diff = '远' and sum_orders = '低频' and sum_amount = '高额' then 'A111U008_004' \\
when date_diff = '近' and sum_orders = '高频' and sum_amount = '低额' then 'A111U008_005' \\
when date_diff = '远' and sum_orders = '高频' and sum_amount = '低额' then 'A111U008_006' \\
when date_diff = '近' and sum_orders = '低频' and sum_amount = '低额' then 'A111U008_007' \\
else 'A111U008_008' end as tagid, \\
user_id as userid, \\
'' as tagweight, \\
'' as tagranking, \\
'' as reserve, \\
'' as reserve1 \\
from user_rfm "
spark = SparkSession.builder.appName("user_rfm_model").enableHiveSupport().getOrCreate()
// 执行sql,放到缓存,可以快速获取缓存的数据
returned_df1 = spark.sql(user_rfm_info).cache()
// 生成一个临时表,这个临时表就可以在后面的sql语句中直接使用
returned_df1.createTempView("user_rfm_info")
returned_df2 = spark.sql(user_rfm).cache()
returned_df2.createTempView("user_rfm")
spark.sql