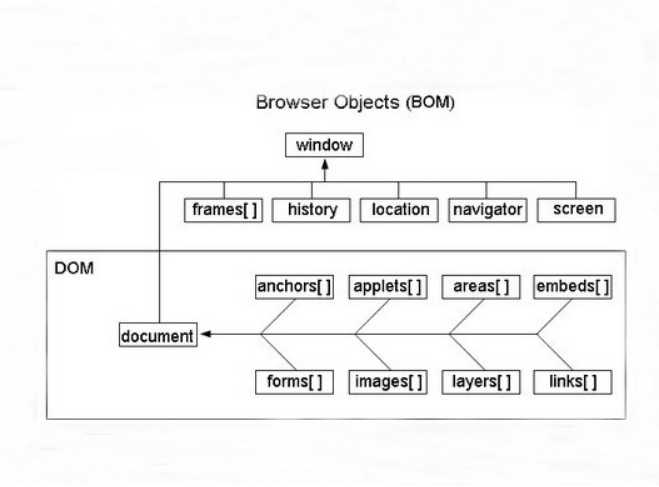
BOM DOM
Posted wang1998
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BOM DOM相关的知识,希望对你有一定的参考价值。
BOM
BOM(Byte Order Mark),字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码。
|
编码
|
表示 (十六进制)
|
表示 (十进制)
|
|---|---|---|
|
EF BB BF
|
239 187 191
|
|
|
UTF-16(大端序)
|
FE FF
|
254 255
|
|
UTF-16(小端序)
|
FF FE
|
255 254
|
|
UTF-32(大端序)
|
00 00 FE FF
|
0 0 254 255
|
|
UTF-32(小端序)
|
FF FE 00 00
|
255 254 0 0
|
|
2B 2F 76和以下的一个字节:[ 38 | 39 | 2B | 2F ]
|
43 47 118和以下的一个字节:[ 56 | 57 | 43 | 47 ]
|
|
|
en:UTF-1
|
F7 64 4C
|
247 100 76
|
|
en:UTF-EBCDIC
|
DD 73 66 73
|
221 115 102 115
|
|
en:Standard Compression Scheme for Unicode
|
0E FE FF
|
14 254 255
|
|
en:BOCU-1
|
FB EE 28及可能跟随着FF
|
251 238 40及可能跟随着255
|
|
GB-18030
|
84 31 95 33
|
132 49 149 51
|
DOM
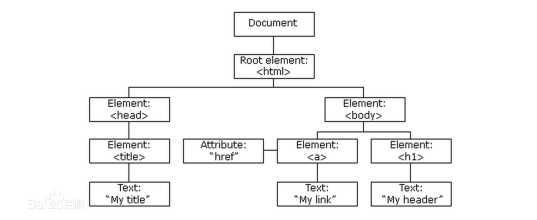
文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展标志语言的标准编程接口。在网页上,组织页面(或文档)的对象被组织在一个树形结构中,用来表示文档中对象的标准模型就称为DOM。Document Object Model的历史可以追溯至1990年代后期微软与Netscape的“浏览器大战”,双方为了在JavaScript与JScript一决生死,于是大规模的赋予浏览器强大的功能。微软在网页技术上加入了不少专属事物,既有VBScript、ActiveX、以及微软自家的DHTML格式等,使不少网页使用非微软平台及浏览器无法正常显示。DOM即是当时蕴酿出来的杰作。
通过使用getElementByld()和getElementsByTagName()方法
通过使用一个元素节点的parentNode、firstChild以及lastChild属性
getElementByld()和getElmementsTagName()这两种方法,可查找整个HTML文档中的任何HTML元素。
这两种方法会忽略文档的结构。这两种方法会向你提供任何你所需要的HTML元素,不论他们在文档中所处的位置。
getElementByld()可通过指定的ID来返回元素:
getElementByld()语法
document.getElementByld("ID");注释:getElementByld()无法工作在XML中。在XML文档中,你必须通过拥有类型id的属性来进行搜索,而此类型必须在XMLDTD中进行声明。
getElementsByTagName()方法会使用指定的标签名返回所有的元素(作为一个节点列表),这些元素是你在使用
此方法时所处的元素的后代。
getElementsByTagName() 可被用于任何的 HTML 元素:
getElementsByTagName() 语法
document.getElementsByTagName("标签名称");或者:
document.getElementById(‘ID‘).getElementsByTagName("标签名称");
以上是关于BOM DOM的主要内容,如果未能解决你的问题,请参考以下文章