SELECT GROUP_CONCAT(REPLACE(path,‘/‘,‘,‘)) AS path FROM department b WHERE department_type = 1
执行结果:

sql:
SELECT DISTINCT SUBSTRING_INDEX(SUBSTRING_INDEX(a.path,‘,‘,b.help_topic_id + 1),‘,‘,-1) FROM (SELECT GROUP_CONCAT(REPLACE(path,‘/‘,‘,‘)) AS path FROM department b WHERE department_type = 1) a JOIN mysql.help_topic b ON b.help_topic_id < (LENGTH(a.path) - LENGTH(REPLACE(a.path,‘,‘,‘‘)) + 1)
执行结果:
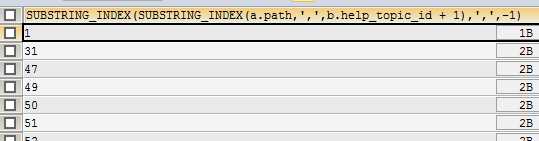
原理分析:
这个join最基本原理是笛卡尔积。通过这个方式来实现循环。
分析:
length(a.path) - length(replace(a.path,‘,‘,‘‘))+1 表示了,按照逗号分割后,分割需要循环的次数。
join过程:
根据ID进行循环
{
判断:i 是否 <= n
获取最靠近第 i 个逗号之前的数据, 即 substring_index(substring_index(a.path,‘,‘,b.help_topic_id),‘,‘,-1)
}
这种方法的缺点在于,我们需要一个拥有连续数列的独立表。并且连续数列的最大值一定要大于符合分割的值的个数。
例如有一行的path有100个逗号分割的值,那么我们的table 就需要有至少100个连续行。
当然,mysql内部也有现成的连续数列表可用。如mysql.help_topic: help_topic_id 共有504个数值,一般能满足于大部分需求了。