[Reinforcement Learning] 强化学习介绍
Posted maybe2030
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Reinforcement Learning] 强化学习介绍相关的知识,希望对你有一定的参考价值。
随着AlphaGo和AlphaZero的出现,强化学习相关算法在这几年引起了学术界和工业界的重视。最近也翻了很多强化学习的资料,有时间了还是得自己动脑筋整理一下。
强化学习定义
先借用维基百科上对强化学习的标准定义:
强化学习(Reinforcement Learning,简称RL)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。
从本质上看,强化学习是一个通用的问题解决框架,其核心思想是 Trial & Error。
强化学习可以用一个闭环示意图来表示:
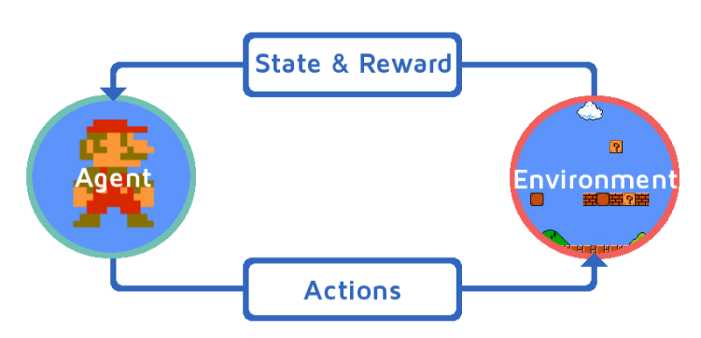
强化学习四元素
- 策略(Policy):环境的感知状态到行动的映射方式。
- 反馈(Reward):环境对智能体行动的反馈。
- 价值函数(Value Function):评估状态的价值函数,状态的价值即从当前状态开始,期望在未来获得的奖赏。
- 环境模型(Model):模拟环境的行为。
强化学习的特点
- 起源于动物学习心理学的试错法(trial-and-error),因此符合行为心理学。
- 寻求探索(exploration)和采用(exploitation)之间的权衡:强化学习一面要采用(exploitation)已经发现的有效行动,另一方面也要探索(exploration)那些没有被认可的行动,已找到更好的解决方案。
- 考虑整个问题而不是子问题。
- 通用AI解决方案。
强化学习 vs. 机器学习
机器学习是人工智能的一个分支,在近30多年已发展为一门多领域交叉学科,而强化学习是机器学习的一个子领域。强化学习与机器学习之间的关系可以通过下图来形式化的描述:
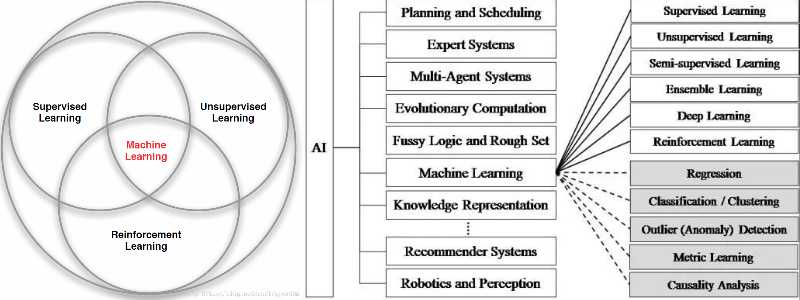
注:上图中Machine Learning分支应该包含进化算法(Evolutionary Algorithms)。
强化学习与其他机器学习的不同:
- 强化学习更加专注于在线规划,需要在探索(explore 未知领域)和采用(exploit 现有知识)之间找到平衡。
- 强化学习不需要监督者,只需要获取环境的反馈。
- 反馈是延迟的,不是立即生成的。
- 时间在强化学习中很重要,其数据为序列数据,并不满足独立同分布假设(i.i.d)。
强化学习 vs. 监督学习
强化学习与监督学习可以参考下图:
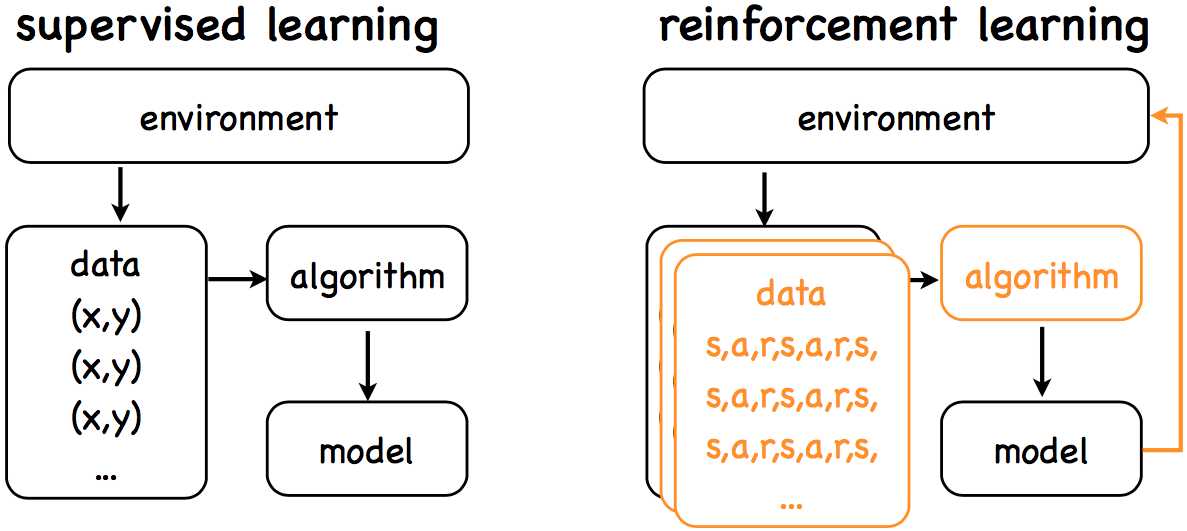
两者的目标都是学习一个model,而区别在于:
监督学习:
- Open loop
- Learning from labeled data
- Passive data
强化学习:
- Closed loop
- Learning from decayed reward
- Explore environment
强化学习 vs. 进化算法
进化算法(Evolutionary Algorithms,简称EA)是通过生物进化优胜略汰,适者生存的启发而发展的一类算法,通过种群不断地迭代达到优化的目标。进化算法属于仿生类算法的一种,仿生类算法还包括粒子群算法(PSO)、人工免疫算法以及如日中天的神经网络算法等。
进化算法最大的优点在于整个优化过程是gradients-free的,其思想可以通过下图表示:
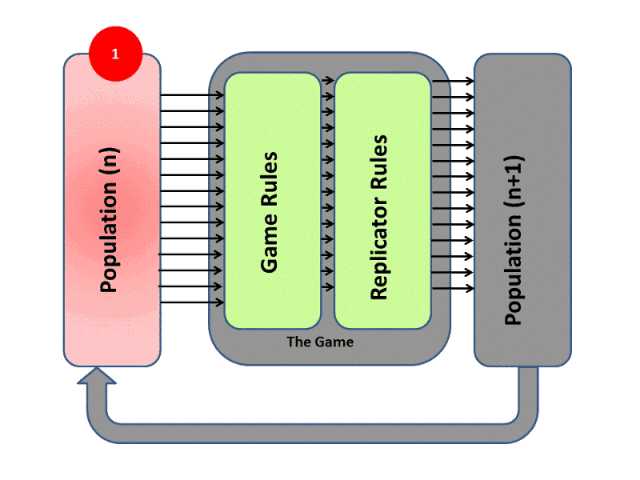
RL和EA虽然都属于优化问题的求解框架,而且两者都需要大量的算力,但是两者有着本质上的区别。
Sutton在其强化学习介绍一书中也重点谈到了RL与EA的区别,这里简单谈几点:
- RL通过与环境交互来进行学习,而EA通过种群迭代来进行学习;
- RL通过最大化累计回报来解决序列问题,而EAs通过最大化适应函数(Fitness Function)来寻求单步最优;
- RL对于state过于依赖,而EA在agent不能准确感知环境的状态类问题上也能适用。
近期随着RL的研究热潮不断推进,很多研究也尝试通过将EA和RL结合解决优化问题,比如OpenAI通过使用进化策略来优化RL,获得了突破性的进展[3]。
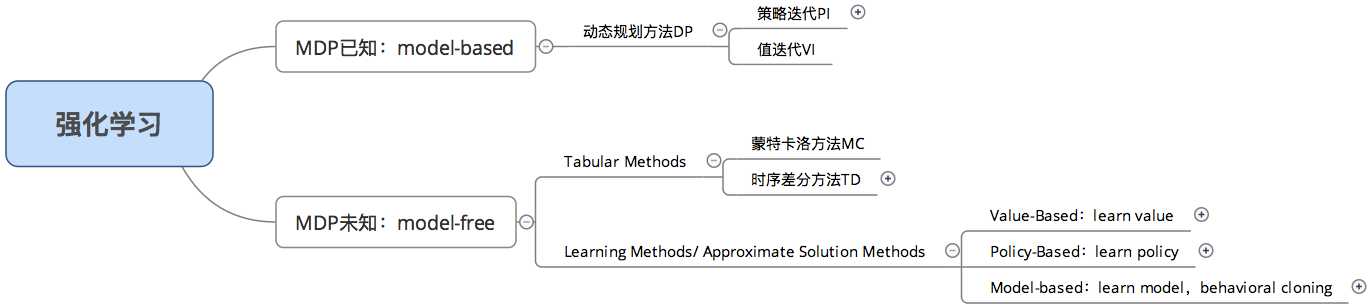
强化学习分类
强化学习分类比较多样:
- 按照环境是否已知可以分为Model-based & Model-free;
- 按照学习方式可以分为On-Policy & Off-Policy;
- 按照学习目标可以分为Value-based & Policy-based。
下图为根据环境是否已知进行细分的示意图:
强化学习相关推荐资料
- Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto:介绍强化学习很全面的一本书籍,相关的电子书及源码见这里。
- David Silver在UCL的强化学习视频教程:介绍强化学习的视频教程,基本与Sutton的书籍可以配套学习,Silver来自于Google Deepmind,视频和课件可以从Silver的主页获取,中文字幕版视频YouTube链接点这里。
- 强化学习在阿里的技术演进与业务创新:介绍强化学习在阿里巴巴的落地,可以拓展强化学习应用的业务思路,电子版见这里,密码:yh48。
- Tutorial: Deep Reinforcement Learning:同样来自于Sliver的一个课件,主要针对RL与DL的结合进行介绍,电子版见这里,密码:9mrp。
- 莫烦PYTHON强化学习视频教程:可以通过简短的视频概括地了解强化学习相关内容,适合于入门的同学,视频见这里。
- OpenAI Gym:Gym is a toolkit for developing and comparing reinforcement learning algorithms,Gym包含了很多的控制游戏(比如过山车、二级立杆、Atari游戏等),并提供了非常好的接口可以学习,链接见这里。
- Lil‘Log:介绍DL和RL的一个优质博客,RL相关包括RL介绍、Policy Gradients算法介绍及Deep RL结合Tensorflow和Gym的源码实现,主页链接见这里。
Reference
[1] 维基百科-强化学习
[2] Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto, 2018
[3] Evolution Strategies as a Scalable Alternative to Reinforcement Learning
以上是关于[Reinforcement Learning] 强化学习介绍的主要内容,如果未能解决你的问题,请参考以下文章
Reinforcement Learning Q-learning 算法学习-4
Deep Reinforcement Learning 深度增强学习资源
Reinforcement Learning Q-learning 算法学习-3
repost: Deep Reinforcement Learning