飞桨最新升级汇总 (附赠AI产业应用技术方案和学习资料大礼包)
Posted 百度大脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了飞桨最新升级汇总 (附赠AI产业应用技术方案和学习资料大礼包)相关的知识,希望对你有一定的参考价值。

转眼2022年即将结束,今年下半年飞桨进行了一系列发新和升级,涵盖目标检测、图像分类、图像分割、语音、OCR、NLP、模型压缩、模型部署、时序预测等技术方向。本次也给大家准备了全套AI产业应用技术方案和学习资料大礼包(文末可领取),包含多个方向。下面就让小编为你快速介绍。
►►►
飞桨开源框架2.4版发布
以底层技术创新持续优化性能表现
此次飞桨升级的2.4版本,框架开发更加灵活便捷,大规模模型分布式训练持续领先,并实现了全场景高性能推理部署。

开发方面,飞桨开源框架2.4版本针对稀疏计算、图学习等重要场景新增160多个API,并且API开发门槛和成本大幅降低,使此次新增的API中有1/3来自生态开发者的贡献。针对AI for Science场景需求,2.4版实现了通用的高阶自动微分功能,更好地支持科学计算相关应用。同时,飞桨全面提升了核心动转静技术的可扩展性和部署灵活性,新模型动转静成功率达92%,充分发挥动态图和静态图各自优势。
训练方面,2.4版全新升级,推出了基于GPU的超大规模图模型训练引擎PGLBox,在业内率先实现了可同时支持复杂算法、超大图、超大离散模型的一体化图学习方案。另外,飞桨的集合通信分布式训练性能也做到了极致优化,为大模型训练提供了全面丰富的分布式训练性能优化体系,基于此,飞桨今年连续两次获得国际权威的AI训练基准测试MLPerf Training榜单第一。
推理部署,对于大模型的推理,飞桨开源框架2.4版支持自适应模型切分和分布式推理等功能,依托飞桨框架动转静能力,可实现自动深度融合及高性能优化,全面支撑大模型应用落地。同时为了从根本上解决AI应用落地面临的场景碎片化、开发成本高、推理速度慢三大难题,飞桨全新推出的全场景高性能AI部署工具FastDeploy,一站式满足端、边、云多场景,多框架与多硬件的部署需求,不仅API设计统一,简单易用,而且还支持自动化压缩与高性能推理引擎深度联动,可充分发挥软硬一体融合优势,拥有业内领先的推理性能,为AI产业应用落地提供最优解。
►►►
端到端大模型开发套件
PaddleFleetX重磅发布
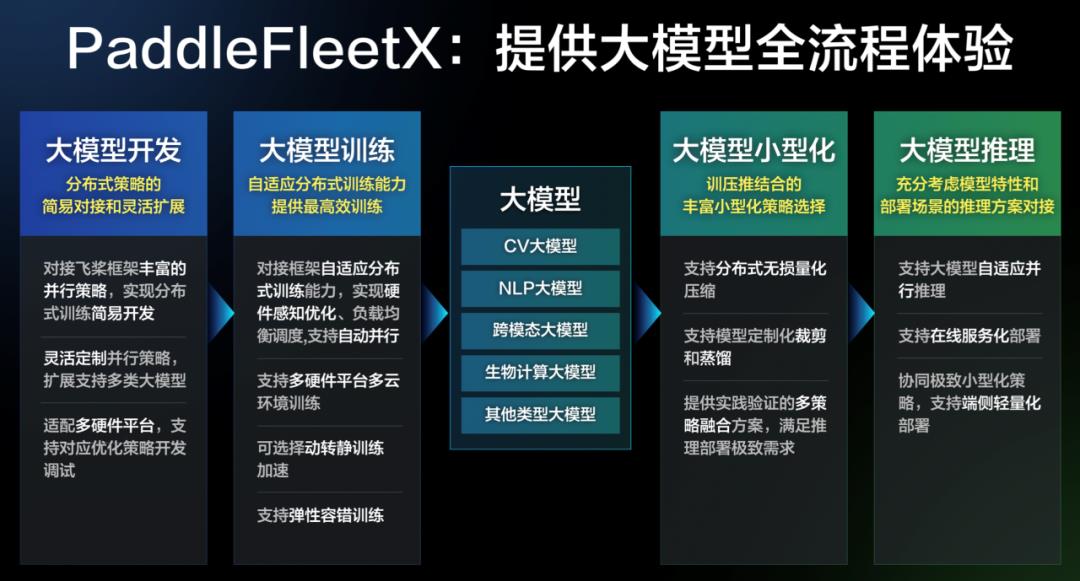
PaddleFleetX无缝对接飞桨并行策略并支持定制化组合,可以扩展支持更多类型的大模型,开发者可以根据模型结构的特点自行选择并行策略组合,并且支持GPU/NPU/DCU等多硬件平台的多云环境的训练调试。同时,PaddleFleetX还支持自适应分布式推理技术,真正做到了分布式策略的训推一体,大可支持超大模型的服务化部署,小可协同训压推结合的丰富小型化策略,实现端侧轻量化部署。
►►►
全场景高性能AI部署工具FastDeploy
三行代码搞定150+模型部署
新一代推理部署工具FastDeploy,为产业实践的推理部署向开发者提供最优解。FastDpeloy通过将部署API标准化、模型API标准化、多硬件适配、端到端的性能优化,实现了三行代码搞定AI模型部署,一行命令切换不同推理后端和硬件,支持云、边、端不同部署形态,满足不同开发者的部署需求。经过高密度打磨,FastDeploy目前具备3类特色能力:
全场景:统一多端部署API,支持Paddle Inference、Paddle Lite、TensorRT、OpenVINO、ONNX Runtime、RKNN、Poros,一行代码切换不同推理后端和推理硬件,实现不同部署场景的零成本迁移;多框架支持支持,一行命令实现模型协议互转;多硬件适配目前支持的硬件包括X86 CPU、NVIDIA GPU、Jetson、飞腾 CPU、昆仑 XPU、Graphcore IPU、华为昇腾 NPU、ARM CPU(联发科、瑞芯微、高通、麒麟等)、瑞芯微 NPU、晶晨 NPU、恩智浦 NPU等十多类AI硬件)。
易用灵活:多语言统一API,三行代码完成AI模型的部署;覆盖20多个主流产业应用场景,预置150+产业级部署Demo,覆盖CV、NLP、Speech、Cross-model,以及10多个基于EasyEdge的端到端的端侧部署工程Demo,助力快速产品落地。
极致高效:FastDeploy集成飞桨压缩与推理特色,深度联动自动压缩与推理引擎深度优化,结合高性能前后处理加速库,实现更高效的量化推理部署和AI模型端到端的性能优化体验。
项目传送门
https://github.com/PaddlePaddle/FastDeploy
►►►
飞桨图像分割开源套件
PaddleSeg重磅升级!
图像分割是计算机视觉三大任务之一,基于深度学习的图像分割技术也发挥日益重要的作用,广泛应用于智慧医疗、工业质检、自动驾驶、遥感、智能办公等行业。

然而在实际业务中,图像分割依旧面临诸多挑战,比如:分割数据标注效率较低、标注过程自动化程度低、垂类场景多样、打造全流程方案的难度大、针对3D分割的方案较少。
针对以上挑战,飞桨图像分割开源套件PaddleSeg近期升级2.7版本,主要包括:
开源NeurIPS 2022顶会发表的语义分割官方实现模型RTFormer,结合CNN和Transformer的优点,该模型设计并使用了高效的RTFormer Block。对比其他实时语义分割模型,RTFormer在多个数据集上实现SOTA精度和速度。
针对标注数据的难题,发布智能标注平台EISeg正式版,支持医疗、遥感、工业质检等领域的分割标注,新增视频分割标注,分割标注效率提升超过过10倍。
针对人像分割场景,发布实时人像分割SOTA方案PP-HumanSegV2,推理
速度提升87.15%,分割精度达到96.63%,可视化效果更佳,可与商业收方费方案媲美。
针对抠图场景,发布百度自研轻量级抠图模型PP-MattingV2,推理速度提升44.6%,平均误差减小17.91%,超越此前SOTA模型,支持零成本开箱即用,并构建了Matting模型库和Benchmark。
针对3D医疗分割场景,发布3D医疗影像分割方案MedicalSegV2,支持3D交互式标注,并新增医疗影像分割模型SwinUnet、TransUnet和nnFormer。
►►►
飞桨文字识别套件PaddleOCR发布PP-StructureV2智能文档分析系统
针对开发者的需求,飞桨文字识别套件PaddleOCR全新发布PP-StructureV2智能文档分析系统,支持一行命令实现PDF转Word功能,文字、表格、标题、图片都可完整恢复,一键实现PDF编辑自由!

PP-StructureV2智能文档分析系统升级点包括以下2方面:
1.系统功能升级:新增图像矫正和版面复原模块,支持标准格式pdf和图片格式pdf解析!
2.系统性能优化:
版面分析:发布轻量级版面分析模型,速度提升11倍,平均CPU耗时仅需41ms!
表格识别:设计3大优化策略,预测耗时不变情况下,模型精度提升6%。
关键信息抽取:设计视觉无关模型结构,语义实体识别精度提升2.8%,关系抽取精度提升超过9.1%。
GitHub传送门
https://github.com/PaddlePaddle/PaddleOCR
►►►
车辆分析工具
Paddle-Vehicle开源上新
继行人分析工具PP-Human之后,飞桨目标检测端到端开发套件PaddleDetection正式开源车辆分析工具PP-Vehicle!
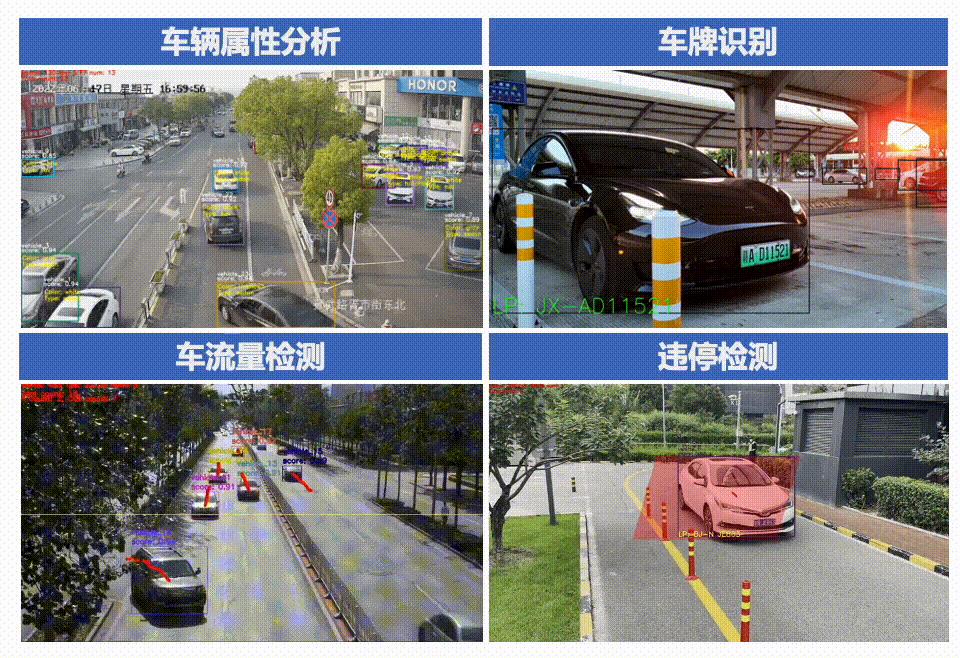 PP-Vehicle功能全景图
PP-Vehicle功能全景图
PP-Vehicle是一款针对车辆分析相关场景的开源工具,产品主要围绕以下几个方面进行设计开发:
实用性:针对车辆分析场景共性的底层模型进行优选迭代;针对几个高频场景进行了详细的后处理策略设计,可以满足业务的快速上线需求。同时提供丰富的二次开发教程,方便用户根据自己的业务场景进行私有化开发。
泛化性:在公开数据集以及自采数据集上进行充分训练,并且提供预训练模型,覆盖车辆分析中监控视角、驾驶员视角、俯拍视角等常见相机视角。
低代码:实现1行代码快速部署,支持图片、视频、单路/多路rtsp视频流输入,修改配置文件即可快速实现策略修改以及pipeline的组合。
源码链接如下
https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.5/deploy/pipeline
►►►
较YOLOv7精度提升1.9%
54.7mAP的PP-YOLOE+强势登场
PP-YOLOE+是基于飞桨云边一体高精度模型PP-YOLOE迭代优化升级的版本,具备以下特点:
超强性能
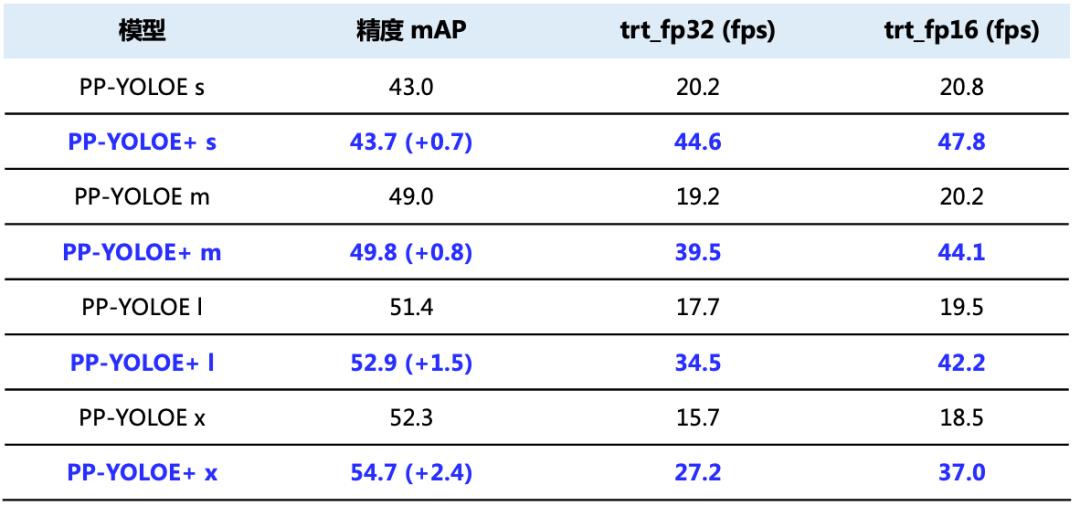
PP-YOLOE+与PP-YOLOE性能对比
*备注:以上速度为端到端推理速度,包含数据解码+数据预处理+模型预测+后处理计算;均在v100上测试所得,V100 + CUDA11.2 + cudnn8.2.0 + TRT8.0.1.6
训练收敛加速:使用Objects365预训练模型,减少训练轮数,训练收敛速度提升3.75倍。
下游任务泛化性显著提升:在农业、夜间安防、工业等不同场景数据集上验证,精度最高提升8.1%。
高性能部署能力:本次升级PP-YOLOE+支持多种部署方式,包括Python/C++、Serving、ONNX Runtime、ONNX-TRT、INT8量化等部署能力。
超强性能与超高泛化性使得PP-YOLOE+助力开发者在最短时间、最少量数据上能得到最优效果。
模型下载与完整教程请见PP-YOLOE+
https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.5/configs/ppyoloe
►►►
三行代码建模,训练虚度提升200%
时序预测神器PaddleTS开源!
时序是什么?时序预测可以为业务带来哪些价值?产品销量预测、电池剩余寿命预测……这些高价值场景如何提高预测准确率?深度学习模型在时序预测有什么优势?如何寻得一款集前沿高尖时序技术的产品,为业务所用?
百度飞桨重磅发布了一款开源时序建模算法库——PaddleTS,可以帮助开发者实现时序数据处理、分析、建模、预测全流程,具有更优的使用体验:
超易用:3行代码即可完成时序建模
速度快:模型训练效率比同类产品快2倍
效果好:时序专属的自动建模与集成预测效果突出
GitHub项目
https://github.com/PaddlePaddle/PaddleTS/
►►►
AI模型自动压缩工具
两行代码完成AI模型压缩
PaddleSlim推出的全新自动化压缩工具(Auto Compression Toolkit, ACT),旨在通过Source-Free的方式,自动对预测模型进行压缩,压缩后模型可直接部署应用。ACT目前在30多个CV-CNN类模型、CV-Transformer类模型以及NLP模型进行了充分的验证。详细压缩收益如下:
CV-CNN类模型:使用ACT中的基于知识蒸馏的量化训练方法量化训练YOLOv7模型,与原始的FP32模型相比,INT8量化后的模型减小3.95倍,在NVIDIA GPU上推理加速5.16倍。使用ACT中的非结构化稀疏和蒸馏技术训练PP-HumanSeg模型,与压缩前相比在ARM CPU上推理加速1.49倍。
CV-Transformer类模型:利用其中的知识蒸馏的量化训练,无需无需修改训练源代码,通过几十分钟量化训练,即可获得模型体积降低3.93倍,GPU上推理速度相比FP32速度提升7.10倍。
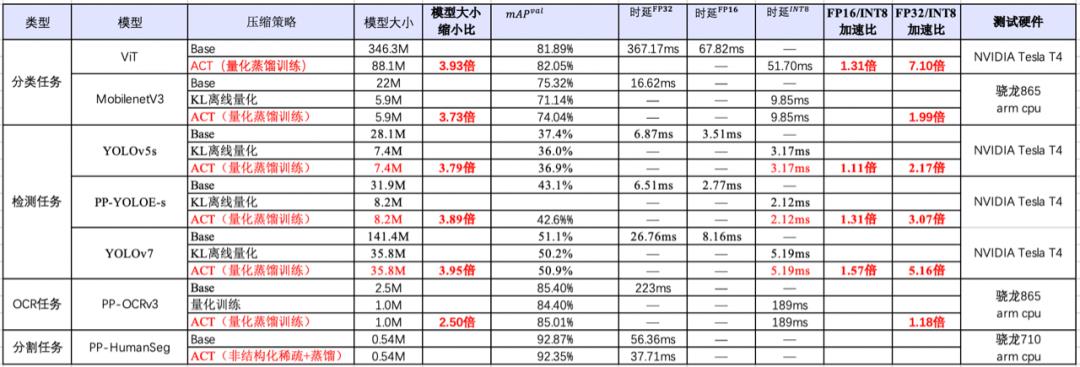
NLP专项模型:利用ACT中的结构化稀疏和蒸馏量化技术量化训练ERNIE3.0模型,与原始的FP32对比,INT8量化后的模型减小185%,在NVIDIA GPU上推理速度与FP32对比提升6.37倍。

github地址
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression
►►►
无需训练、APP可玩
商品、车辆、菜品20+场景一键识别
图像识别作为深度学习算法的主流实践应用方向,早已在生活的各个领域发挥作用。如安全检查、身份核验时的人脸识别;无人货架、智能零售柜中的商品识别,其背后的关键技术都在于此。

PP-ShiTu v2实际预测效果示意图
然而实现理想的识别效果却并不容易:
难点一:针对海量数据,不同场景均实现优秀的表征能力,能否一套方案全搞定?
难点二:不同物品的差别极其微小,或者同类物品由于受到外界干扰却呈现不同形态,究竟如何进行有效区分?
难点三:识别需求更新频繁,使用单一模型必须不断重训模型,怎样才能降低开发成本,快速跟上迭代步伐?
此次PaddleClas最新升级发布的通用图像识别系统PP-ShiTu v2完美解决以上难点,无需训练,一套模型即可完成20+高频场景的图像识别,对于新增类别更是只需两步即可添加入库,实现精准识别。
上下滑动查看更多应用场景
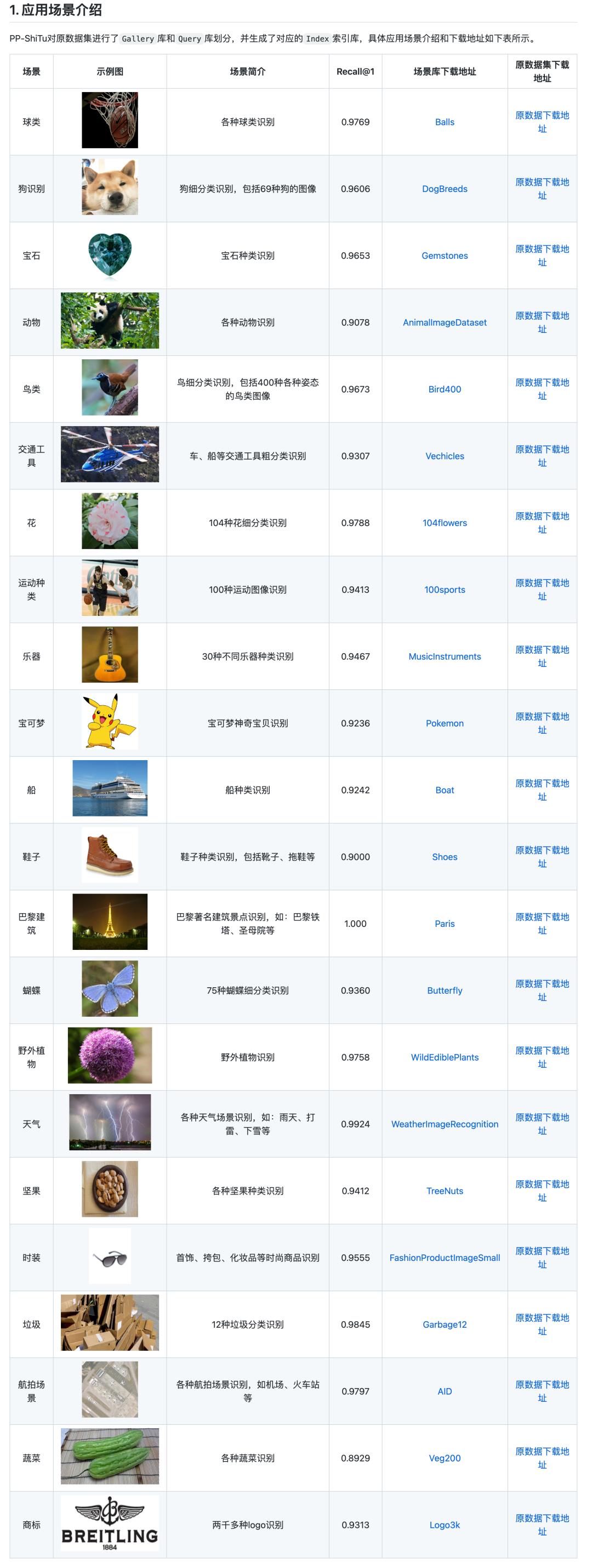
项目链接
https://github.com/PaddlePaddle/PaddleClas
►►►
PaddleNLP重大升级!覆盖信息抽取、文本分类、语义检索等领域
飞桨自然语言处理模型库PaddleNLP,聚合众多百度自然语言处理领域自研SOTA算法以及社区开源模型,并凭借飞桨核心框架底层能力,不断开源适合产业界应用的模型、场景、预测加速与部署能力,得到学术界与产业界的广泛关注。今年,PaddleNLP带来重大升级,覆盖信息抽取、文本分类、情感分析、语义检索、智能问答等自然语言处理领域核心任务。
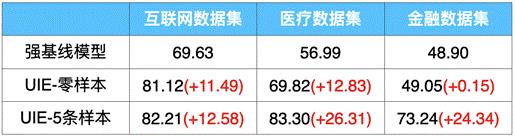
PaddleNLP开源首个面向通用信息抽取的产业级技术方案UIE,零样本、小样本效果领先。
通过调用paddlenlp.Taskflow API即可实现零样本(zero-shot)抽取多种类型的信息;
对于复杂目标,可以标注少量数据(Few-shot)进行模型训练,以进一步提升效果。PaddleNLP打通了从数据标注-训练-部署全流程,方便大家进行定制化训练。以金融领域事件抽取任务为例,仅仅标注5条样本,F1值就提升了25个点!
开源文心ERNIE-Layout,文档智能不再难
1.文心ERNIE-Layout多语言版跨模态布局增强文档预训练大模型
2.DocPrompt开放文档抽取问答模型(基于文心ERNIE-Layout)
PaddleNLP发布NLP流水线系统Pipelines,10分钟搭建检索、问答等复杂系统
发布多场景文本分类方案,新增数据增强策略,可信增强技术
新增AutoPrompt自动化提示功能,轻松上手Prompt Learning,解决小样本难题
GitHub地址
https://github.com/PaddlePaddle/PaddleNLP/
►►►
定制音库成本骤降98%
PaddleSpeech小样本语音合成方案
随着以语音为交互渠道的产业不断升级,企业对语音合成有着越来越多的需求,比如智能语音助手、手机地图导航、有声书播报等场景都需要用到语音合成技术。通过语音合成技术想要得到一个新的音色,需要定制音库,但是定制音库所耗费的人力成本和时间成本巨大,成为产业升级的屏障。
面对音库成本难题,PaddleSpeech语音合成技术再升级,开源多种降低定制音库成本方案。
多种小样本合成方案:支持一句话合成和小数据集微调。一句话合成方案即通过用户输入的一句话即可模仿用户的音色进行语音合成任务;小数据集微调方案针对少量数据学习用户音色,训练所需数据量降低98%以上。
跨语言学习方案:支持多发音人多语种训练,让发音人实现同音色跨语言语音合成任务,可有效降低音库对发音人多语种发音能力要求。
语音-语言跨模态大模型文心ERNIE-SAT:采用语音-文本联合训练的方式在多语言的数据集上训练,合成声音更加自然,可以承接多种下游任务,支持个性化合成、跨语言合成、语音编辑,可有效降低定制化音库所需数据量。
项目传送门
https://github.com/PaddlePaddle/PaddleSpeech
【AI产业应用技术方案和学习资料大礼包】
以上就是本次集中产品发新的全部内容,更多功能细节大家可以前往飞桨官网体验。本次百度飞桨还为大家准备了全套产业应用技术方案和学习资料大礼包,分量不小,请准备好充足的内存,包含:
1.《OCR产业应用技术方案》
✅《动手学OCR》共397页(电子版)
✅66篇OCR顶会前沿论文
✅10节《PaddleOCR深度讲解课程》和PDF资料
✅19个官方OCR技术产业实践案例
✅OCR场景应用模型库
2.《目标检测产业应用技术方案》
✅涵盖30大类250+模型算法和方案
✅20+真实企业产业应用案例(含代码)
✅6位百度资深研发工程师联合讲授
✅10节目标检测产业应用核心AI技术课
✅30+行人车辆等垂类高性能预训练模型
✅10+工业安防交通全流程项目实操(含代码)
3.《NLP产业应用技术方案》
✅自然语言处理从入门到精通(24讲)
✅自然语言处理产业应用实践分享
✅NLP精选Notebook项目80篇
✅NLP赛题基线方案(原理+实践)
✅PaddleNLP历史直播课合集
4.《图像分割产业应用技术方案》
✅20个企业图像分割应用案例(含代码)
✅10份图像分割代码解读文档
✅图像分割模型产业实操范例
✅涵盖工业/人像/医疗等多个行业的分割数据集
✅分割垂类场景解决方案
5.《语音模型产业应用技术方案》
✅语音识别方向论文合集
✅语音合成方向论文合集
✅PaddleSpeech历史直播课合集
✅PaddleSpeech语音技术实战
6.《图像分类产业应用技术方案》
✅20+场景数据库,覆盖各类商品、动植物等
✅8个图像分类产业范例(含代码、模型)
✅70+前沿图像分类与识别论文
✅图像分类课程回访与优秀项目集锦
7.《自动压缩工具产业应用技术方案》
✅模型压缩方向顶会论文合集
✅压缩方向历史直播课合集
✅模型压缩架构师培训师资料
✅深度学习课程



本次礼包发放只限500个名额
快来登记领取吧

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
以上是关于飞桨最新升级汇总 (附赠AI产业应用技术方案和学习资料大礼包)的主要内容,如果未能解决你的问题,请参考以下文章
飞桨升级 创新引领!发布飞桨最新技术成果及产业实践,共话AI创新引领新征途...
飞桨升级 创新引领!发布飞桨最新技术成果及产业实践,共话AI创新引领新征途...
WAVE SUMMIT+2022飞桨平台新升级 全面支撑大模型研发与产业化