从CREATE开始
- 通过显式的CREATE INDEX命令
- 在创建约束时作为隐含的对象
随约束创建的隐含索引
当向表中添加如下两种约束之一时,就会创建隐含索引。
- 主键约束(聚集索引)
- 唯一约束(唯一索引)
一、CREATE INDEX语法
CREATE INDEX语句所做的事情与其听上去一样-用于在指定表或视图上基于声明的列创建索引:

CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED]
INDEX <index name> ON <table or view name>(<column name> [ASC|DESC][,...n])
INCLUDE (<column name> [,...n])
[
WITH
[PAD_INDEX = {ON | OFF}]
[[,] FILLFACTOR = <fillfactor>]
[[,] IGNORE_DUR_KEY = {ON | OFF}]
[[,] DROP_EXISTING = {ON | OFF}]
[[,] STATISTICS_NORECOMPUTE = {ON | OFF}]
[[,] SORT_IN_TEMPDB = {ON | OFF}]
[[,] ONLINE = {ON | OFF}]
[[,] ALLOW_ROW_LOCKS = {ON | OFF}]
[[,] ALLOW_PAGE_LOCKS = {ON | OFF}]
[[,] MAXDOP = <maxinum degree of parallelism>
]
[ON {<filegroup> | <partition scheme name> | DEFAULT}]
CREATE INDEX语句必须随表或者视图出现,并且需要声明列所在(ON)的表。下面解释个选项的作用
1、ASC/DESC
这两个选项允许为索引选择升序和降序排列顺序。默认选项为ASC,它是升序。
为什么需要升序和降序两个选项呢?不是反序查看索引不就行了吗?但是如果一列按升序排列,但是其他列要求按降序排列,怎么办呢?因为索引的列是存储在一起的,所以对一列反向查看索引也将倒转其他列的顺序。如果显示地声明某一列是升序,而另一列是降序,那么将直接在索引的物理数据中倒转第二列-突然间就不必改变访问数据的方式了。
2、INCLUDE
这是SQL Server2005及后续版本支持的选项。它的目的是为覆盖查询(covered queries)提供更好的支持。
当包含(INCLUDE)列而不是将列放在ON列表上时,SQL Server仅仅在索引的叶级上添加它们。因为在索引叶级上的每一行对应于一个数据行,所以所做的事情在本质上是将更多的原始数据包含在索引的叶级上。这样做有一个好处,因为SQL Server在有了它实际需要的内容就停止工作。SQL Server在遍历索引时没有继续访问实际的数据行就找到所需的所有数据,那么就不必再到达数据行。通过在索引中包含特定的列,可以在叶级“覆盖”利用该特定索引的查询,从而节省了与使用索引指针到达数据页相关的I/O。实际是,比如你为一个日期列创建索引,但是INCLUDE一个订单ID列。那么查找某日期的订单ID,就不必再到实际数据行了,因为在索引中就有了所需的数据。但是注意不要滥用该选项,当包含列时,将增加索引页的叶级的大小。这意味着每页中的行数将更少,因此需要更多的I/O来查看相同数量的行。结果可能是,加快了一个查询的同时可能减慢了其他的查询。要考虑对系统各个部分的影响,而不是仅仅考虑某个时候正在使用的特定查询。
3、WITH
WITH非常简单-它只是告诉SQL Server将要提供一个或者多个跟在后面的选项。
4、PAD_INDEX
该选项确定了第一次创建索引时,索引的非叶级页将有多满(用百分比表示)。不用在PAD_INDEX中声明百分比,因为将使用后面的FILLTACTOR选项指定的百分比。设置不带有FILLFACTOR选项的PAD_INDEX=ON将是没有意义的。
5、FILLFACTOR
当SQL Server第一次创建索引时,默认情况下将尽可能地将页填满,仅留两个记录的控件,可以将FILLTACTOE设置为在0-100之间的任意值。一旦索引构造完成,这个数字将表示页相对满的程度的百分比。但是在进行页拆分时,数据将仍然在两页之间对半分布-除了定期重建索引外,不能不断地控制填充百分比。
当需要调整页密度的时候,使用FILLTACTOR需要从以下几方面考虑:
- 如果是OLTP系统(经常添加和删除),那么需要较低的FILLFACTOR。
- 如果是OLAP或者其他非常稳定(几乎没有添加和删除)的系统,那么需要尽可能高的FILLFACTOR。
- 如果事务比例中等,且有很多基于它的报表类型查询,那么可能需要中等水平的FILLFACTOR(不太低,也不太高)。
- 如果没有提供值,那么SQL Server将把页填充至差两行满为止,同时保证每页至少有一行。(如果行是8000字符宽,那么每页只能放一行,所以无法达到差两行满)。
6、IGNORE_DUP_KEY
IGNORE_DUP_KEY选项几乎是一种回避系统的方法。简而言之,它使得唯一约束与其应有的操作方式有些不同。
通常,唯一约束(或唯一索引)不允许任何种类的重复-如果事务尝试基于定义为唯一的列创建重复值,那么事务将被回滚并且拒绝。然而,一旦设置了IGNORE_DUP_KEY选项,就将得到混合的行为。仍然接收错误信息,但是错误将仅仅是一种警告-记录仍然没有被插入。
从IGNORE_DUP_KEY的角度看,不能会事务进行回滚(错误仍是警告错误,而不是关键错误),但重复的行将被拒绝。
一句话,这个东西的态度是,重复行完全没问题,但是你要有一个该值的行存在就OK了(插入时,重复行被忽略,还是全部都不允许插入)。
当你创建唯一索引时,你可以指定IGNORE_DUP_KEY选项,因此本文最开始创建唯一索引的选项可以是:
CREATE UNIQUE NONCLUSTERED INDEX AK_Product_Name ON Production.Product ( [Name] ) WITH ( IGNORE_DUP_KEY = OFF );
IGNORE_DUP_KEY这个名字容易让人误会。唯一索引存在时重复的值永远不会被忽略。更准确的说,唯一索引中永远不允许存在重复键。这个选项的作用仅仅是在多列插入时有用。
比如,你有两个表,表A和表B,有着完全相同的结构。你可能提交如下语句给SQL Server。
INSERT INTO TableA SELECT * FROM TableB;
SQL Server会尝试将所有表B中的数据插入表A。但如果因为唯一索引拒绝表B中含有和表A相同的数据插入A怎么办?你是希望仅仅重复数据插入不成功,还是整个INSERT语句不成功?
这个取决于你设定的IGNORE_DUP_KEY参数,当你创建唯一索引时,通过设置设个参数可以设定当插入不成功时怎么办,设置IGNORE_DUP_KEY的两种参数解释如下:
IGNORE_DUP_KEY=OFF
整个INSERT语句都不会成功并弹出错误提示,这也是默认设置。
IGNORE_DUP_KEY=OFF
只有那些具有重复键的行不成功,其它所有的行会成功。并弹出警告信息。
IGNORE_DUP_KEY 选项仅仅影响插入语句。而不会被UPDATE,CREATE INDEX,ALTER INDEX所影响。这个选项也可以在设置主键和唯一约束时进行设置。
7、DROP_EXISTING
如果指定DROP_EXISTING选项,那么如果之前已经存在同名索引将在构造新索引之前被删除。当和群集索引一起使用该选项时,这个选项比简单删除并重新创建现有的索引更加有效。如果重新创建与现有索引完全匹配的索引,那么SQL Server知道它不需要涉及非群集索引,然而为了适应不同的行位置,显式删除和创建将导致重新构建所有非群集索引两次。如果使用DROP_EXISTING改变索引的结构,那么NCI只被重新构建一次,而不是两次。
8、STATISTICS_NORECOMPUTE
默认情况下,SQL Server试图自动化在表和索引上更新统计信息的过程。通过选择该选项,表示将由自己手动负责更新统计信息。为了关闭这个选项,需要运行UPDATESTATISTICS命令,但不使用NORECOMPUTE。
强烈建议不要使用该选项,因为查询优化器使用索引上的统计信息来指出索引对于给定的查询有多大用处。随着表中数据大量增多或减少,以及列特定值改变。索引上的统计信息会不断变化。基于这两点,可以知道不更新统计信息则查询优化器将基于过时的信息运行查询,打开自动统计信息功能意味着统计信息将周期地更新(多长时间更新一次取决于对表更新的本质和频繁程度)。相反关闭自动更新统计信息意味着信息会过时,或者需要设定计划手动运行UPDATE STATISTICS。
9、SORT_IN_TEMPDB
只有在tempdb存储在与包含新索引的数据库物理上分离的驱动器上时,该选项才有意义。为什么?
当SQL Server建立索引时,它必须执行多个读操作以处理各种索引构造步骤。
1、遍历所有的数据,构建对应于实际数据每一行的叶行。类似于实际数据和最后的索引,这些内容进入用于临时存储的页。这些中间页不是最终的索引页,而是每次排序缓冲器已满时临时存储的位置。
2、通过这些中间页单独运行,以将他们合并到最终叶级页。
3、当填充叶级页时,构建非叶级页。
如果没有使用SORT_IN_TEMPDB选项,那么中间页将被写入在其中存储数据库的相同物理文件中。这意味着实际数据的读操作必须与构建过程的写操作竞争。这两种情况造成磁头需要移动到一个不同的位置(读和写)。结果是磁头经常地来回移动-这会花费时间。
另一方面,如果使用SORT_IN_TEMPDB,那么中间页将被写入tempdb中,而不是数据库自己的文件。如果它们在单独的物理驱动器上,这意味着在索引构建的读和写操作之间没有竞争。但是要牢记,只有在tempdb位于与数据库文件分离的独立物理驱动器上,这才会有效。否则,只是名义上发生改变,而I/O竞争仍然是问题。
如果要使用SORT_IN_TEMPDB,那么确保在tempdb中有用于支持大文件的足够空间。
10、ONLINE
如果将这个选项设置为ON,那么它将强制表对于一般的访问保持有效,并且不创建任何阻止用户使用索引和/表的锁。默认情况下,全索引操作将获得所需的锁(最终得到表锁),以便对表进行完全和有效的访问,然而,副作用是这将会阻止用户(这是矛盾的:一方面可能正在建立索引以使数据库更为有用,但是同时又使表变得不可用)。
11、ALLOW ROW/PAGE LOCKS
这里的ALLOW设置用于确定索引是否允许行锁和页锁。
12、MAXDOP
该选项用于为构建索引覆盖关于最大并行度的系统设置。并行度是指将有多少个进程用于一个数据库操作。有一个称为最大并行度的系统设置,允许限制每个操作中的处理器数。索引创建的MAXDOP选项允许将并行度设置为高于或者低于基本系统设置。只要合适就行。
13、ON
SQL Server允许通过使用ON选项将数据和索引单独存放。这样做有以下优点:
- 索引需要的空间可以分散到其他的驱动器中。
- 用于索引操作的I/O不会加重物理数据检索的负担。
下面简单补充下XML索引的概念。
XML索引是SQL Server2005新增功能。
除了IGNORE_DUP_KEY和ONLINE之外,XML的创建语法支持前面的CREATE语句中所看到的所有相同选项。
在SQL Server中,可以再类型为XML的列上创建索引。这样做的主要要求如下。
- 在包含需要索引的XML的表上必须具有群集索引。
- 在创建“辅助”索引之前,必须先在XML数据列上创建“主”XML索引。
- XML索引只能放在XML类型的列上创建(而且XML索引是可以再改类型的列上创建的唯一一种索引)。
- XML列必须是基表的一部分-不能在视图上创建索引。
1、主XML索引
在XML索引上创建的第一个索引必须声明为"主索引"。当创建主索引时,SQL Server创建一个新的群集索引,这个群集索引将基表的群集索引和来自任何指定的XML节点的数据组合在一起。
2、辅助XML索引
类似于指向群集索引的群集键的非群集索引,辅助XML索引以很相似的方法指向主XML索引。一旦创建了主XML索引,就只能在XML列上创建多达248个以上的XML索引。
二、修改索引
ALTER INDEX命令在其用来做什么方面多少有些欺骗性。截止到现在,ALTER命令总是与修改对象的定义有关。例如ALTER表以添加或禁用约束和列。ALTER INDEX是不同的-该命令与维护有关,而与结构完全不相干。如果需修改索引的组成,那么只能DROP然后CREATE索引,或者用DROP_EXISTING=ON选项CREATE并使用索引。
ALTER INDEX的语法类似于下面这样:
ALTER INDEX {<name of index> | ALL}
ON<table or view name>
{ REBUILD
[[ WITH (
[PAD_INDEX = {ON | OFF}]
| [[,] FILLFACTOR = <fillfactor>
| [[,] SORT_IN_TEMPDB = { ON | OFF }]
| [[,] IGNORE_DUP_KEY = { ON | OFF }]
| [[,] STATISTICS_NORECOMPUTE = { ON | OFF }]
| [[,] ONLINE = { ON| OFF }]
| [[,] ALLOW_ROW_LOCKS = { ON | OFF }]
| [[,] ALLOW_PAGE_LOCKS = { ON | OFF }]
| [[,] MAXDOP = <max degree of parallelism>
)]
|[ PARTITION = <partition number>
[ WITH (< partition rebuild index option>
[,...N])]]]
| DISABLE
| REORGANIZE
[ PARTITION = <partition number> ]
[ WITH (LOB_COMPACTION = { ON | OFF })]
| SET ([ ALLOW_ROW_LOCKS = { ON | OFF} ]
| [[,] ALLOW_PAGE_LOCKS = { ON | OFF } ]
| [[,] IGNORE_DUP_KEY = { ON | OFF } ]
| [[,] STATISTICS_NORECOMPUTE = { ON | OFF }]
)
}[;]
其中一些选项与CREATE INDEX命令相同,因此这里将略过对这些选项的重新定义。除此之外,相当多的ALTER特定选项都是细节性的,且与处理碎片之类的事情有关。下面解释下参数
1、索引名
如果想维护一个特定的索引可以指定该索引,或者使用ALL表明想要维护与指定的表相关联的所有索引。
2、表名或视图名
要在其上维护的特定对象(表或视图)的名称。注意,必须是一个特定的表(可以给它提供一个列表,然后说“请处理所有这些!”)。
3、REBULD
如果使用该选项运行ALTER INDEX,那么将完全丢弃旧的索引并重新生成新的索引。结果是真正优化的索引,其中所有叶级和非叶级的页都按照定义进行了重新构建。如果是群集索引,那么也会重新组织物理数据。
默认情况下,页将被重新组织为差两行满。和CREATE TABLE语法一样,可以将FILLFACTOR设置为0~100之前的任何值。该值是在数据库完成重新组织后页被填满的程度(以百分比表示)。但在进行页拆分时,数据将被对半分部在两个页上-除了定期重建索引外,不得不断控制填充的百分比。 要小心使用该选项,一旦开始REBUILD,在完成索引重建钱,正在使用的索引实际上就没有了。依赖该索引的所有查询可能会变得异常慢。对于这类事情,首先需要在离线系统上测试,以了解整个过程将花多少时间。然后,计划在非高峰时段运行。
4、DISABLE
该选项名副其实,只是方式有些过激。如果该命令的全部作用只是为了让索引离线,直至您决定了进一步要做什么,则它是不错的选择,但它实际会把索引标记为不可用,一旦禁用了某个索引,在重新激活之前,必须重建索引(不是重新组织,而是重建)。
如果对表禁用了群集索引,那么也会禁用表。数据仍会保留,但在重建群集索引钱,不能被所有索引(因为他们都依赖群集索引)访问。
5、REORGANIZE 如果重新组织索引,就得到了比完全重建索引稍逊一点的完全优化,但这种方法可以联机进行(用户仍能使用索引)。
稍逊一点指的是什么?其实是REORGANIZE只在索引的叶级起作用,而不触及非叶级。这意味着未获得完全优化。但是,对于大部分的索引而言,那不是真正产生碎片的地方。
三、删除索引
如果不断地重新分析情况和添加索引,那么也不要忘记删除索引。记住在插入索引上的系统开销。
删除索引的语法如下:
DROP INDEX <table or view name>.<index name>
这样就可以删除索引了。
SQL Server索引设计
SQL Server索引的设计主要考虑因素如下:
检查WHERE条件和连接条件列;
使用窄索引;
检查列的选择性;
检查列的数据类型;
考虑列顺序;
考虑索引类型(聚集索引OR非聚集索引);
一、检查WHERE条件列和链接条件列
当一个查询提交到SQL Server时,查询优化器尝试为查询中引用的所有表查找最佳的数据访问机制。下面列出查询优化器针对WHERE和连接的工作方式:
- 优化器识别WHERE子句和连接条件中包含的列。
- 接着优化器检查这些列上的索引。
- 优化器通过从索引上维护的统计确定子句的选择性,评估每个索引的有效性。
- 最终,优化器根据前面几个步骤中手机的信息,估计读取所限定行开销最低的方法。
为了理解WHERE子句在查询中的重要性,来考虑一个示例。
SELECT * FROM Person WHERE Id = 100;
假设上面的表Id列为聚集索引。上面的语句有了WHERE子句,查询优化器将检查WHERE子句的列Id,确定Id列上有聚集索引,从聚集索引上的统计评估WHERE子句的高选择性,并且决定使用这个索引。
查询优化器的表现说明,WHERE子句列帮助优化器选择一个对查询最优的索引操作。这也适用于两个表之间的连接条件中使用的列。优化器查找到WHERE子句或连接条件列上的索引,如果可用,考虑使用该索引来从表中检索行。查询优化器在执行一个查询时,考虑WHERE子句或连接条件列上的索引。因此WHERE子句或连接条件中频繁使用的列上有索引将帮助优化器避免基本表的扫描。
但是,当一个表中的数据总量非常小以至于可以放入一个数据页,那么表扫描可能比索引查找更快,如果有一个好的索引,但是仍然进行扫描,可以考虑这个问题。
二、使用窄索引
可以在表中的一个列组合上创建索引,但是为了最好的性能,尽量在索引中使用较少的列。还应该避免在索引中使用宽数据类型的列。
- 窄索引:索引中的列数尽可能少;
- 宽数据类型:占用空间比较大的数据类型,如:CHAR、VARCHAR、NVARCHAR、CLOB等。除非绝对必须,否则在索引中要把大尺寸的宽数据类型的列的使用降到最少。
窄索引可以在8KB的索引页面上容纳比宽索引更多的行,这将有如下优点:
- 减少I/O数量(读取更少的8KB页面);
- 使数据库缓存更有效,因为SQL Server可以缓存更少的索引页面,从而减少内存中的索引页面所需的逻辑读操作;
- 减少数据库存储空间;
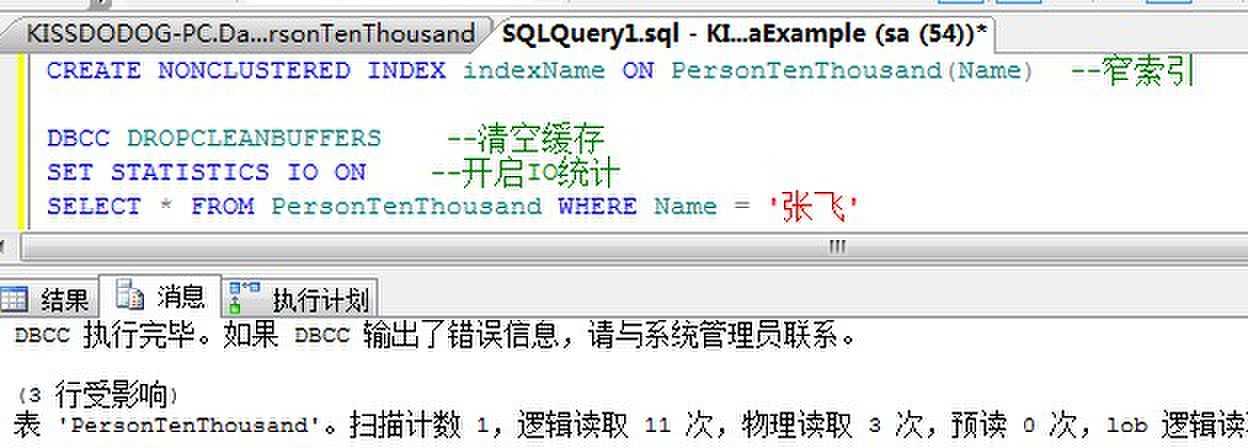
下面以后一个示例来说明窄索引的好处:
第一次,我们的索引仅仅包含Name列:
第二次,我们的索引INCLUDE多了两列:
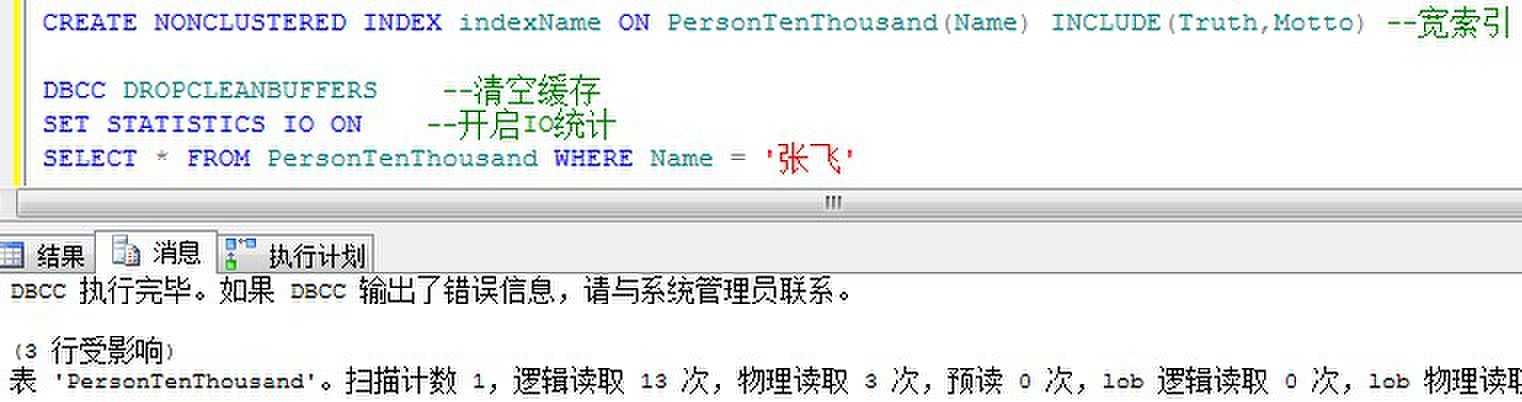
我们看到。包含多了两个列之后,逻辑读取比一个列多?为什么呢?因为包含多了两个列,索引需要占用更大的空间,一个数据页放的索引行少了,就需要读取更多的数据页。
三、索引列的选择性
索引,特别是非聚集索引,主要在索引中有相当高级别的选择性的情况下是有益的。所谓选择性,指的是列中唯一值的百分比。列中的唯一值百分比越高,选择性就越高,从而索引的溢出就越大。如果一个表中有2000条记录,表索引列有1990个不同的值,那么这个索引的选择性就是1980/2000=0.99。
在前面的学习中已经了解到,在非聚集索引中的查询实际上只是开始。要找到真正的数据,仍需要对聚集索引再执行一次循环遍历。甚至使用堆上的非聚集索引,仍然需要执行多个单独的物理读操作。
如果在非聚集索引中的一个查找将要在聚集索引上产生多个额外的查找,那么进行表扫描可能更好。这里可能产生的影响实际上是非常惊人的。如果被索引的列唯一性达不到90%~95%,那么考虑由非聚集索引创建的循环过程是不值得的。比如一个性别选项,设置为了bit,然后建索引。查询优化器是不会考虑使用这种索引的。
由以上的分析,可知主键的选择性是100%,选择性越接近主键,建在该列的索引的效率就会越高。
索引的可选择性是衡量索引的利用率的方法,比如在极端的情况下,一个表记录数是1000,而索引列的值只有5个不同的值,则索引的可选择性很差(只有0.005)。这样的情形使用全表扫描要比采用索引还好。
下面来实操下,计算下索引的选择性,当然测试表数据小,可能查询时即使有了索引,SQLServer也未必会用。
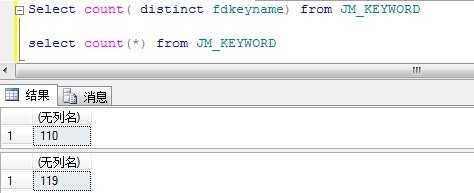
由以上信息可计算得到对fdkeyname列的索引选择性为
110/119 = 0.924
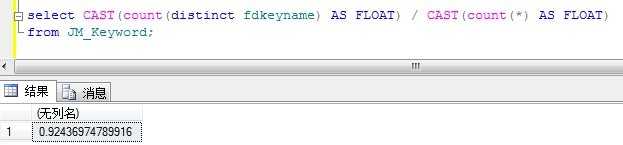
这样还是麻烦啊?难道手工算吗?下面给出一条SQL语句查出选择性的方法:
SELECT CAST(count(DISTINCT fdkeyname) AS FLOAT) / CAST(count(*) AS FLOAT)
FROM JM_Keyword;
选择性规则的一个例外与外键有关,如果表中有一列是外键,那么在该列上有一个索引,这很可能是有益的。为什么是外键而不是其他列呢?外键常常是与它们引用的表连接的目标。不管选择性如何,索引在连接性能方面是非常有帮助的,因为它们允许合并连接。合并连接从每个表中获取一行进行比较,查看它们是否和连接条件匹配。因为两个表中的相关列上都存在索引,所以对两个行的查找是非常快的。
下面以一个示例来说明问题:
我在一个Person表中的性别列建立了一个索引,然后来查看查询优化器的查询方式:
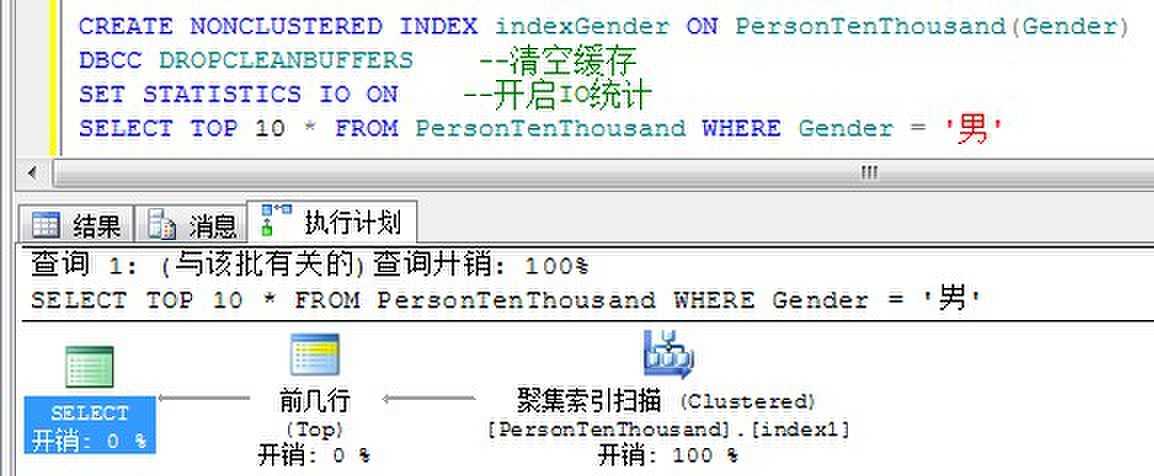
为什么查询优化器不选择从Gender列的索引来查找数据呢?
我要返回前10条性别为"男"数据,如果使用索引,我们知道这个Gender列上的索引的选择性大约为50%。SQL Server即使通过索引找到了前10条性别为男的聚集列,也还要再通过Id到聚集索引中去查找数据,这样还不如直接扫描聚集表快。因此SQL Server的查询优化器忽略了这个索引。
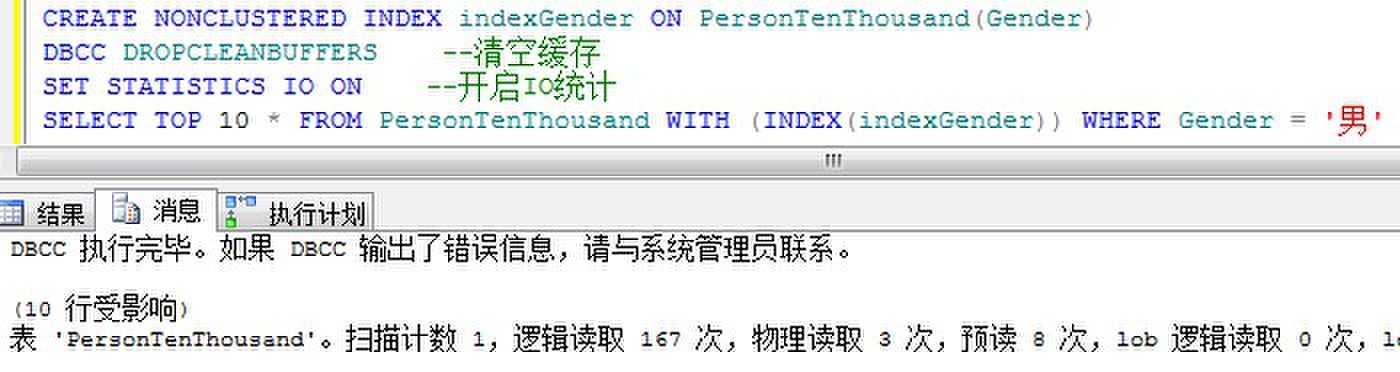
通过WITH INDEX(索引名)可以强制使用索引查找,下面给出这两种查询方式的读取次数比较:
强制索引方式读取:
查询优化器选择读取:
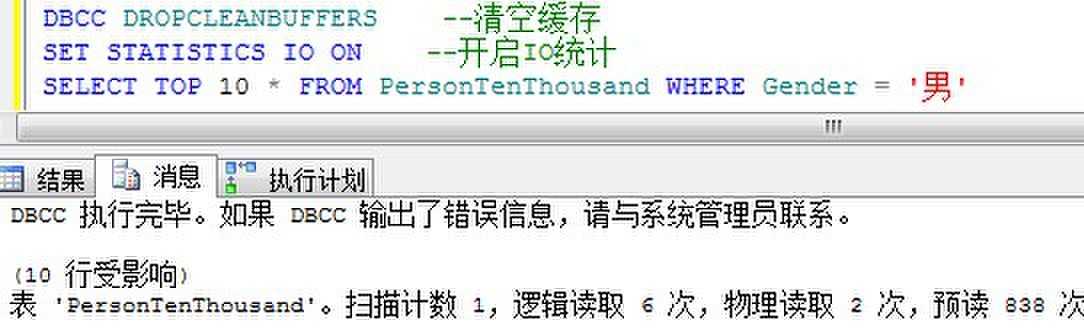
由上面我们可以看到,强制使用索引的话,逻辑读取高,但是预读少。我们知道预读是与分析并行执行,而且能够载入缓存中的。从SQL Server的选择来看,基本上可以得出一个结论,逻辑读比预读更加占用时间。
四、检查索引的数据类型
索引列的数据类型也是很重要的。例如,在一个整数键值上的索引查询是非常快的,这是因为int数据类型的尺寸很小,而且算数操纵很容易。也可以使用int数据的其他变种(bigint,smallint,tinyint)作为索引列,而字符串数据类型(char、varchar、nchar、ncarchar、)需要字符串匹配操作,这通常比整数匹配操作的开销更大。
假设希望在一列上创建索引但却有两个候选列,一个是int数据类型,一个是char(4)数据类型。这两种数据类型在SQL Server 2008中大小都是4字节,但是仍然应该首选int数据类型作为索引。因为char(4)数据类型中的值1实际上保存为1后面跟着3个空格,4个字节组合是0x35、0x20、0x20、0x20。CPU不理解如何在这个数据上执行算数运算。因此在算数操作之前要将其转换为一个整数,而在int数据类型中,值1被保存为0x00000001。CPU可以简单地在这个数据上执行算数运算。
五、索引列顺序
索引键值在索引的第一列上排序,然后再一次再下一列中排序。
假设我们的在一张表中建立一个复合索引:
CREATE NONCLUSTERED INDEX indexName ON Table(c1,c2)
那么索引中的数据大概如下:
| c1 | c2 |
| 1 | 1 |
| 1 | 2 |
| 2 | 1 |
| 2 | 2 |
| 3 | 1 |
| 3 | 2 |
SELECT * FROM Table WHERE c1 = 1 或 2
SELECT * FROM Table WHERE c2 = 1 或 2 AND c1 = 1 或 2
(c2,c1)对上面两个查询都有利,但是(c1,c2)上的索引就不合适,因为它首先在c1上排序,而第一个SQL语句需要在c2上排序。
这就好比使用电话本。所有项都是按先姓后名的方式进行索引-如果值知道要通电话的人的名是“备”,那么这种排列顺序不能带来什么好处。另一方面,如果只知道他的姓是“刘”,那么索引将可以用来缩小查找范围。
六、考虑索引类型
考虑索引的类型 SQL Server中有两种主要的索引类型:聚集索引和非聚集索引。这两种类型都为B-树结构。两者之间的主要区别是聚集索引中的叶子页是表的数据。因此表中的数据和聚集索引的顺序相同,这意味着,聚集索引就是该表。在决定使用索引类型时,两种索引类型的叶子级别上的差别变得非常重要。
一个表只有一个聚集索引,应该明智地选择它。
SQLServer在默认情况下,主键和聚集索引是一起创建的。如果不想将主键声明为聚集索引,那么在创建表时,只需添加NONCLUSTERED关键字。
CREATE TABLE MyTableKeyExample
{
Column1 int IDENTITY
PRIMARY KEY NONCLUSTERED,
Column2 int
}
一旦创建了索引,改变它的唯一方法是删除和重建它,所以需要一开始就做对。
如果改变了聚集索引所在的列,那么SQL Server将需要对整个表完全重新排序(因为对于聚集索引,表的排列顺序和索引顺序是相同的)。
对于数据比较多的表,改变聚集索引,需要重新排序的数据非常多,要从以下几个方面进行考虑。
它将需要花费多长时间。 是否有足够的空间?为了在聚集索引上执行重新排序,额外需要的平均空间量将为表已经占用空间量的1.2倍。确保有足够的空间来操作。 应当使用SORT_IN_TEMPDB选项吗?如果tempdb位于与主数据库不同的物理阵列上,并且它有足够的空间,那么答案是肯定的。
1、正面观点
如果列常作为范围查询的对象,那么聚集索引对这类查询是很有用的。这类查询通常使用between语句或<or>符号。使用GROUP BY以及利用MAX、MIN和COUNT聚合函数的查询也是使用范围和偏好聚集索引的查询的重要示例。聚集索引适合用于此处,是因为搜索可以直接到达物理数据中的特定点,可一直读数据,直到范围的末端,然后停止。这种方法非常有效。当想要数据基于聚集键排序(ORDER BY),聚集也是极好的方法。
2、反面观点
有两种情况下,你可能不想创建聚集索引。
(1)、当有更好的位置来使用它时。不要因为列看上去适合做聚集索引就将它用作聚集索引(主键是最常见的罪魁祸首)-要确定没有更合适的其他列。
(2)、在将要以非连续的顺序进行大量插入时。这会进行页拆分,并且会消耗大量时间。
例如,一个交易系统,用
ARXXXX
GLXXXX
APXXXX
作为主键,并使用默认的聚集索引,那么在插入数据的时候,经常会发生页拆分。因为数据会按照聚集索引进行排序,那么不停的录入数据,就可能会经常性地发生页拆分,引起短暂停顿。
幸运的是,有一些方法可以避免以上情形:
选择在插入时是连续的聚集键。可以以此创建一个标识列,或者也可以使用另一个列,该列对于任何输入交易来说,在逻辑上都是连续的。
选择不在这个表上使用聚集索引。对于类似的这里的情形来说,这通常是最好的选择,因为在对上非聚集索引中的插入一般比在聚集键上的插入更快。
何时应该使用聚集索引与非聚集索引
动作描述 使用聚集索引 使用非聚集索引 列经常被分组排序 应 应 返回某范围内的数据 应 不应 一个或极少不同值 不应 不应 小数目的不同值 应 不应 大数目的不同值 不应 应 频繁更新的列 不应 应 外键列 应 应 主键列 应 应 频繁修改索引列 不应 应
事实上,我们可以通过前面聚集索引和非聚集索引的定义的例子来理解上表。如:返回某范围内的数据一项。比如你的某个表有一个时间列,恰好您把聚合索引建立在了该列,这时你查询2010年1月1日到2013年1月1日之间的全部数据时,这个速度就将是很快的,因为你的这本字段正文是按日期进行排序的,聚集索引只需要找到要检索的所有数据中的开头和结尾数据即可;而不像非聚集索引,必须先查到目录中查到每一项数据对应的页码,然后再根据页码查到具体内容。
3、结合实际,谈索引使用的误区
下面列出在实践中的一些误区:
1、主键就是索引
这种想法是极端错误的,是对聚集索引的一种浪费。虽然SQL SERVER默认是在竹简上简历聚集索引的。通常,我们会在每个表都建立一个Id列,以区分每条数据,并且这个Id列是自动增大的,增长量一半设为1。以一个办公自动化的紫铜为例子。如果将Id列设为主键,SQL SERVER会将此列默认为聚集索引,这样做有好处,就是可以让你的数据在数据库中按照Id进行物理排序,但这样做的意义不大。聚集索引的速优势是非常明显的,而每个表中只能有一个聚集索引的规则,这使得聚集索引变得更加珍贵。
从我们前面谈到的聚集索引的定义我们可以看出,使用聚集索引的最大好处就是能够根据查询要求,迅速缩小查询范围,避免全表扫描。在实际应用中,因为Id号是自动生成的,我们并不知道每条记录的Id号,所以我们很难在时间中用Id号来进行查询。这个主键作为聚集索引成为一种资源浪费。其次,让每个ID号都不同的字段作为聚集索引也不符合“大数目的不同值情况下不应建立聚合索引”规则;当然,这种情况只是针对用户经常修改记录内容,特别是索引项的时候会负作用,但对于查询速度并没有影响。在办公自动化系统中,无论是系统首页显示的需要用户签收的文件、会议还是用户进行文件查询等任何情况下进行数据查询都离不开字段的是“日期”还有用户本身的“用户名”。
通常,办公自动化的首页会显示每个用户尚未签收的文件或会议。虽然我们的where语句可以仅仅限制当前用户尚未签收的情况,但如果您的系统已建立了很长时间,并且数据量很大,那么,每次每个用户打开首页的时候都进行一次全表扫描,这样做意义是不大的,绝大多数的用户1个月前的文件都已经浏览过了,这样做只能徒增数据库的开销而已。事实上,我们完全可以让用户打开系统首页时,数据库仅仅查询这个用户近3个月来未阅览的文件,通过“日期”这个字段来限制表扫描,提高查询速度。如果您的办公自动化系统已经建立的2年,那么您的首页显示速度理论上将是原来速度8倍,甚至更快。
在这里之所以提到“ 理论上”三字,是因为如果您的聚集索引还是盲目地建在ID这个主键上时,您的查询速度是没有这么高的,即使您在“日期”这个字段上建立的索引(非聚合索引)。下面我们就来看一下在1000万条数据量的情况下各种查询的速度表现(3个月内的数据为25万条): (1)仅在主键上建立聚集索引,并且不划分时间段:
Select gid,fariqi,neibuyonghu,title from tgongwen
用时:128470毫秒(即:128秒) (2)在主键上建立聚集索引,在fariq上建立非聚集索引:
select gid,fariqi,neibuyonghu,title from Tgongwen
where fariqi> dateadd(day,-90,getdate())
用时:53763毫秒(54秒) (3)将聚合索引建立在日期列(fariqi)上:
select gid,fariqi,neibuyonghu,title from Tgongwen
where fariqi> dateadd(day,-90,getdate())
用时:2423毫秒(2秒)
虽然每条语句提取出来的都是25万条数据,各种情况的差异却是巨大的,特别是将聚集索引建立在日期列时的差异。事实上,如果您的数据库真的有1000万容量的话,把主键建立
在ID列上,就像以上的第1、2种情况,在网页上的表现就是超时,根本就无法显示。这也是我摒弃ID列作为聚集索引的一个最重要的因素。
得出以上速度的方法是:在各个select语句前加:declare @d datetime set @d=getdate()
并在select语句后加: select [语句执行花费时间(毫秒)]=datediff(ms,@d,getdate())
2、只要建立索引就能显著提高查询速度
事实上,我们可以发现上面的例子中,第2、3条语句完全相同,且建立索引的字段也相同;不同的仅是前者在fariqi字段上建立的是非聚合索引,后者在此字段上建立的是聚合索引,但查询速度却有着天壤之别。所以,并非是在任何字段上简单地建立索引就能提高查询速度。从建表的语句中,我们可以看到这个有着1000万数据的表中fariqi字段有5003个不同记录。在此字段上建立聚合索引是再合适不过了。在现实中,我们每天都会发几个文件,这几个文件的发文日期就相同,这完全符合建立聚集索引要求的:“既不能绝大多数都相同,又不能只有极少数相同”的规则。由此看来,我们建立“适当”的聚合索引对于我们提高查询速度是非常重要的。 事实上,我们可以发现上面的例子中,第2、3条语句完全相同,且建立索引的字段也相同;不同的仅是前者在fariqi字段上建立的是非聚合索引,后者在此字段上建立的是聚合索引,但查询速度却有着天壤之别。所以,并非是在任何字段上简单地建立索引就能提高查询速度。从建表的语句中,我们可以看到这个有着1000万数据的表中fariqi字段有5003个不同记录。在此字段上建立聚合索引是再合适不过了。在现实中,我们每天都会发几个文件,这几个文件的发文日期就相同,这完全符合建立聚集索引要求的:“既不能绝大多数都相同,又不能只有极少数相同”的规则。由此看来,我们建立“适当”的聚合索引对于我们提高查询速度是非常重要的。
3、把所有需要提高查询速度的字段都加进聚集索引,以提高查询速度
上面已经谈到:在进行数据查询时都离不开字段的是“日期”还有用户本身的“用户名”。既然这两个字段都是如此的重要,我们可以把他们合并起来,建立一个复合索引(compound index)。 很多人认为只要把任何字段加进聚集索引,就能提高查询速度,也有人感到迷惑:如果把复合的聚集索引字段分开查询,那么查询速度会减慢吗?带着这个问题,我们来看一下以下的查询速度(结果集都是25万条数据):(日期列fariqi首先排在复合聚集索引的起始列,用户名neibuyonghu排在后列)
(1)select gid,fariqi,neibuyonghu,title from Tgongwen where fariqi>‘2004-5-5‘
查询速度:2513毫秒
(2)select gid,fariqi,neibuyonghu,title from Tgongwen where fariqi>‘2004-5-5‘ and neibuyonghu=‘办公室‘
查询速度:2516毫秒
(3)select gid,fariqi,neibuyonghu,title from Tgongwen where neibuyonghu=‘办公室‘
查询速度:60280毫秒
从以上试验中,我们可以看到如果仅用聚集索引的起始列作为查询条件和同时用到复合聚集索引的全部列的查询速度是几乎一样的,甚至比用上全部的复合索引列还要略快(在查询结果集数目一样的情况下);而如果仅用复合聚集索引的非起始列作为查询条件的话,这个索引是不起任何作用的。当然,语句1、2的查询速度一样是因为查询的条目数一样,如果复合索引的所有列都用上,而且查询结果少的话,这样就会形成“索引覆盖”,因而性能可以达到最优。同时,请记住:无论您是否经常使用聚合索引的其他列,但其前导列一定要是使用最频繁的列。
其他书上没有的索引使用经验总结 1、用聚合索引比用不是聚合索引的主键速度快 下面是实例语句:(都是提取25万条数据)
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi=‘2004-9-16‘
使用时间:3326毫秒
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where gid<=250000
使用时间:4470毫秒 这里,用聚合索引比用不是聚合索引的主键速度快了近1/4。
2、用聚合索引列比用一般的主键作order by时速度快,特别是在小数据量情况下
select gid,fariqi,neibuyonghu,reader,title from Tgongwen order by fariqi
用时:12936
select gid,fariqi,neibuyonghu,reader,title from Tgongwen order by gid
用时:18843
这里,用聚合索引比用一般的主键作order by时,速度快了3/10。事实上,如果数据量很小的话,用聚集索引作为排序列要比使用非聚集索引速度快得明显的多;而数据量如果很大的话,如10万以上,则二者的速度差别不明显。
3、使用聚合索引列内的时间段,搜索时间会按数据占整个数据表的百分比成比例减少,而无论聚合索引使用了多少个
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi>‘2004-1-1‘
用时:6343毫秒(提取100万条)
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi>‘2004-6-6‘
用时:3170毫秒(提取50万条)
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi=‘2004-9-16‘
用时:3326毫秒(和上句的结果一模一样。如果采集的数量一样,那么用大于号和等于号是一样的)
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi>‘2004-1-1‘ and fariqi<‘2004-6-6‘
用时:3280毫秒
4 、日期列不会因为有分秒的输入而减慢查询速度
下面的例子中,共有100万条数据,2004年1月1日以后的数据有50万条,但只有两个不同的日期,日期精确到日;之前有数据50万条,有5000个不同的日期,日期精确到秒。
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi>‘2004-1-1‘ order by fariqi
用时:6390毫秒
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi<‘2004-1-1‘ order by fariqi
用时:6453毫秒 5、其他注意事项 “水可载舟,亦可覆舟”,索引也一样。索引有助于提高检索性能,但过多或不当的索引也会导致系统低效。因为用户在表中每加进一个索引,数据库就要做更多的工作。过多的索引甚至会导致索引碎片。 所以说,我们要建立一个“适当”的索引体系,特别是对聚合索引的创建,更应精益求精,以使您的数据库能得到高性能的发挥。 当然,在实践中,作为一个尽职的数据库管理员,您还要多测试一些方案,找出哪种方案效率最高、最为有效。
六、聚集索引的重要性和如何选择聚集索引
在上一节的标题中,笔者写的是:实现小数据量和海量数据的通用分页显示存储过程。这是因为在将本存储过程应用于“办公自动化”系统的实践中时,笔者发现这第三种存储过程在小数据量的情况下,有如下现象:
1、分页速度一般维持在1秒和3秒之间。
2、在查询最后一页时,速度一般为5秒至8秒,哪怕分页总数只有3页或30万页。 虽然在超大容量情况下,这个分页的实现过程是很快的,但在分前几页时,这个1-3秒的速度比起第一种甚至没有经过优化的分页方法速度还要慢,借用户的话说就是“还没有ACCESS数据库速度快”,这个认识足以导致用户放弃使用您开发的系统。
笔者就此分析了一下,原来产生这种现象的症结是如此的简单,但又如此的重要:排序的字段不是聚集索引! 本篇文章的题目是:“查询优化及分页算法方案”。笔者只所以把“查询优化”和“分页算法”这两个联系不是很大的论题放在一起,就是因为二者都需要一个非常重要的东西――聚集索引。 在前面的讨论中我们已经提到了,聚集索引有两个最大的优势: 1、以最快的速度缩小查询范围。 2、以最快的速度进行字段排序。
第1条多用在查询优化时,而第2条多用在进行分页时的数据排序。
而聚集索引在每个表内又只能建立一个,这使得聚集索引显得更加的重要。聚集索引的挑选可以说是实现“查询优化”和“高效分页”的最关键因素。 但要既使聚集索引列既符合查询列的需要,又符合排序列的需要,这通常是一个矛盾。 笔者前面“索引”的讨论中,将fariqi,即用户发文日期作为了聚集索引的起始列,日期的精确度为“日”。这种作法的优点,前面已经提到了,在进行划时间段的快速查询中,比用ID主键列有很大的优势。
但在分页时,由于这个聚集索引列存在着重复记录,所以无法使用max或min来最为分页的参照物,进而无法实现更为高效的排序。而如果将ID主键列作为聚集索引,那么聚集索引除了用以排序之外,没有任何用处,实际上是浪费了聚集索引这个宝贵的资源。
为解决这个矛盾,笔者后来又添加了一个日期列,其默认值为getdate()。用户在写入记录时,这个列自动写入当时的时间,时间精确到毫秒。即使这样,为了避免可能性很小的重合,还要在此列上创建UNIQUE约束。将此日期列作为聚集索引列。
有了这个时间型聚集索引列之后,用户就既可以用这个列查找用户在插入数据时的某个时间段的查询,又可以作为唯一列来实现max或min,成为分页算法的参照物。 经过这样的优化,笔者发现,无论是大数据量的情况下还是小数据量的情况下,分页速度一般都是几十毫秒,甚至0毫秒。而用日期段缩小范围的查询速度比原来也没有任何迟钝。 聚集索引是如此的重要和珍贵,所以笔者总结了一下,一定要将聚集索引建立在: 1、您最频繁使用的、用以缩小查询范围的字段上; 2、您最频繁使用的、需要排序的字段上。
聚集索引的叶子页存储的就是表的数据。因此,表行物理上按照聚集索引列排序,因为表数据只能有一种物理顺序,所以一个表只能有一个聚集索引。
当我们创建主键约束时,如果不存在聚集索引并且该索引没有被明确指定为非聚集索引,SQL Server会自动将其创建为唯一的聚集索引,这并不是说主键列就一定是聚集索引,这只是默认行为而已。
示例,建表时通过指定主键为非聚集索引使主键列不为聚集列:
CREATE TABLE MyTableKeyExample
{
Column1 int IDENTITY PRIMARY KEY NONCLUSTERED,
Column2 int
}
一、堆表与聚集表
没有聚集索引的表称为堆表。堆表的数据列没有任何特别的顺序,连接到表的相邻页面。与访问大的聚集表相比,对标这种无组织的结构通常增大了访问大的堆表的开销。
有聚集索引的表称为聚集表,聚集表是B树结构,数据量大时,能够大幅减少读次数。
二、与非聚集索引的关系
SQL Server中聚集索引和非聚集索引之间有一个有趣的关系,非聚集索引的一个索引列包含指向表的对应数据行的指针。这个指针被称为行定位器。行定位器的值取决于数据表是堆表还是聚集表。当时堆表时,行定位器是指向堆中数据行的RID指针。对于具有聚集索引的表,行定位器是聚集索引键值。
下面用一个表格来说明这种关系
假设有一个2列的表:
| RID(这不是实际列) | 列1 | 列2 |
| 1 | A1 | A2 |
| 2 | B1 | B2 |
堆表:
| 索引列(列1) | 行定位器 |
| A1 | RID = 1 指向表中第一行数据 |
| B1 | RID = 2 指向表中第二行数据 |
聚集表,假设我们将列2设为聚集索引列:
| 索引列(列1) | 行定位器 |
| A1 | A2 指向聚集键 |
| B1 | B2 指向聚集键 |
由此可见,通过非聚集索引列查找一行数据,还需要多一步-通过RID获得实际数据。这个RID在堆表是行指针,在聚集表是聚集键值。
三、聚集索引的建议
1、首先创建聚集索引
对于聚集表而言,因为所有非聚集索引在其索引行上都保存一个聚集索引键值,所以非聚集索引和聚集索引创建的顺序非常重要。如果非聚集索引先于聚集索引创建,那么非聚集索引的行定位器将包含指向堆表的RID的指针。然后再创建聚集索引时,会将所有非聚集索引的RID指针改为聚集键,这实际上相当于重新建立了非聚集索引。 为了最好的性能,最好在创建任何非聚集索引之前创建聚集索引。这将使得非聚集索引在创建的时候将他们的行定位器直接设置为聚集索引值。这对最终的性能没有太大影响,但是SQL Server工作量少很多,速度快很多。如果你是在线上运行着的系统进行维护操作,这尤其有用。
2、保持窄索引
因为所有的非聚集索引将聚集索引键作为行定位器,为了最佳的性能,应使聚集索引的总体长度尽可能小。
试想,假如创建了个宽的聚集索引,如CHAR(500),这将在每个非聚集索引中添加一个500字节的值。就算非聚集索引什么都不放,光聚集索引键值占用的空间,它一页的数据页仅仅能存放16个数据行左右。
保持窄聚集索引能有效减少逻辑读操作与磁盘I/O。
3、一步重建聚集索引
因为聚集索引上有非聚集索引的依赖性,用单独的DROP INDEX 和 CREATE INDEX语句重建聚集索引将导致所有非聚集索引被重建两次(DROP,行定位器指向堆表数据行指针,CREATE行定位器指向新的聚集键值)。为了避免这种情况,使用CREATE INDEX语句的DROP_EXISTING子句来在一个单独的原子步骤中重建聚集索引。相似地,也可以在非聚集索引上使用DROP_EXISTING子句。
CREATE CLUSTERED INDEX index1 ON PersonTenThousand(Id) WITH (DROP_EXISTING = ON)
4、何时使用聚集索引
在某些情况下,使用聚集索引是非常有帮助的。
1、检索一定范围的数据
因为聚集索引的叶子页面就是表的实际数据,聚集索引列的顺序就是表中数据行的物理顺序。如果数据行的物理顺序与查询请求的数据顺序相同,磁盘刺头可以顺序地读取所有行,而不需要太多的磁头移动。
假设我聚集索引建立在ID列,我需要读取ID BETWEEN 1 AND 100或ID > 100的数据,那么所有数据行在磁盘上排列在一起。这使磁头可以移动到磁盘上第一行的位置,然后用最少的磁头移动顺序读出所有数据。另一方面,如果行在磁盘上没有以正确的物理顺序排列,磁头必须随机地从一个位置移动到另一个位置来读取所有相关的行。磁头的物理移动是磁盘操作开销的最主要部分,将行以合适的物理顺序在磁盘上排序(使用聚集索引)优化了I/O开销。
2、读取预先排序的数据
聚集索引在数据读取需要排序时特别有效,如果在可能需要排序的一列或多列上创建一个聚集索引,那么行将被按该顺序物理排序,这消除了数据读取之后排序的开销。
在没有聚集索引的情况下,检索范围排序的数据:
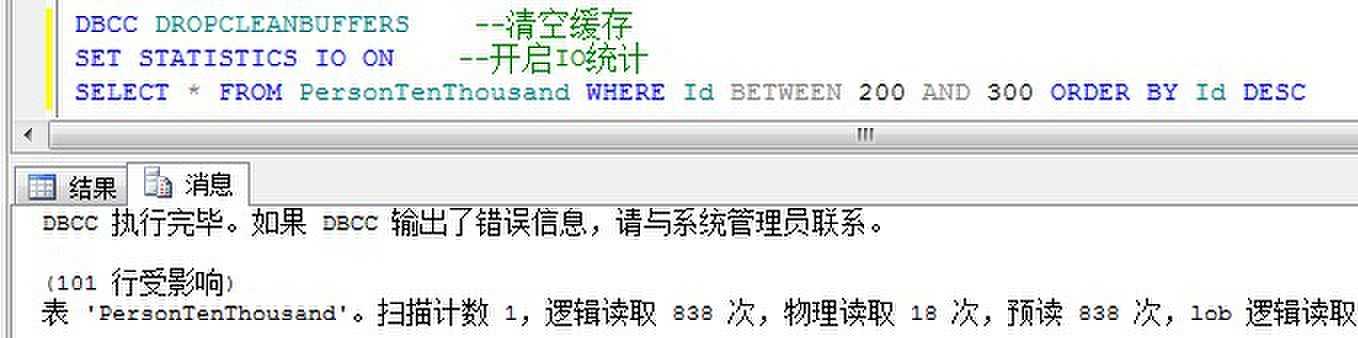
在有聚集索引的情况下,检索范围排序的数据:
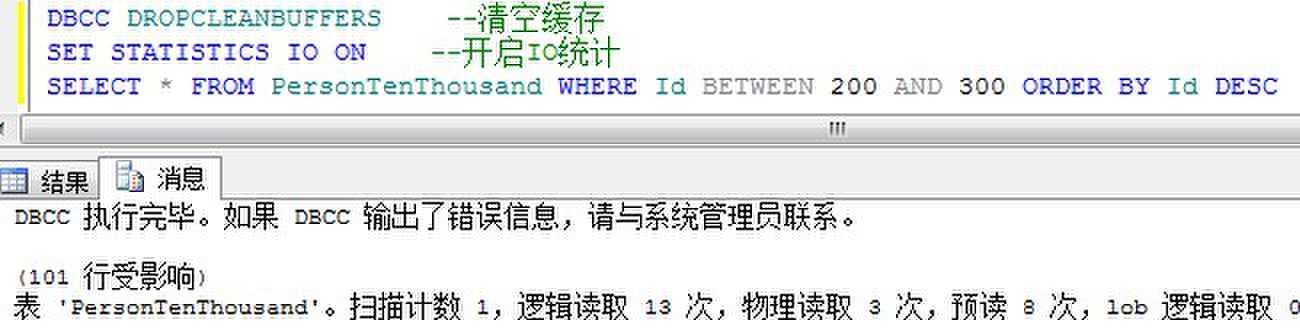
从中看到,有聚集索引的范围排序返回数据非常快速,因为对于聚集列,本身就是已经排好顺序存放于数据库中的。
5、何时不使用聚集索引
在某些情况下,最好不使用聚集索引。
1、频繁更新的列
如果聚集索引列频繁更新,将导致所有非聚集索引行的行定位器相应更新,从而显著地增加相关操作查询的开销。还将阻塞这段时间引用相同部分和非聚集索引的其他查询,从而影响数据库的并行性。因此,应该避免在大量更新的列上创建聚集索引。
2、宽的关键字
因为所有非聚集索引将聚集键作为其行定位器,所以为了性能,应该避免在非常宽或太多列上创建聚集索引。上面红色加粗字体特别说明了原因。
3、太多并行的顺序插入
如果希望并发地添加许多新行,那么对于性能来讲,将他们分布到表的各个数据页面更好一些。但是,如果将所有行按照与聚集索引相同的顺序添加,那么所有的插入操作都在表的最后一个页面上进行。这可能在磁盘的对应山区造成一个巨大的“热点”,为了避免磁盘热点,不应该将数据行按照物理位置相同的顺序排列。可以通过创建另一列上的索引(该索引不会将行按照新航相同的顺序来排列)来插入操作随机地分布到整个表。这个问题只在大量同时插入时发生。
允许在表的尾部插入,能够避免需要容纳新行时发生的页拆分。如果并行插入数据降低,那么按照新行的顺序来排列数据行(使用聚集索引)将避免页拆分。但是,如果磁盘热点成为性能瓶颈,那么新行可以通过降低表的填充因子来容纳到中间页面。另外,“热”的页面将在内存中,这也有利于性能。
最后附上一个设置非主键为聚集索引列的方法:
1. 查看所有的索引,默认情况下主键上都会建立聚集索引
查看索引: sp_helpindex person 查看约束: sp_helpconstraint person
2. --删除主键约束,把【1】中查询出的主键上的索引约束【如:PK__person__117F9D94】去除掉。去掉主键字段上面的主键约束,此时该字段不是主键了。 alter table person drop constraint PK_Person
3.--创建聚集索引到其它列
create clustered index test_index on person(Name)
4.—修改原来的主键字段还是为主键,此时会自动建立非聚集索引【因为已经有了聚集索引】
sp_helpindex person
sp_helpconstraint person
alter table person drop constraint PK_Person
create clustered index test_index on person(Name)
alter table person add primary key (id)
alter table person add primary key (id)
