Pyspide
Posted songdongdong6
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pyspide相关的知识,希望对你有一定的参考价值。
Pyspider
- 三大组件的介绍:
Secheduler
组件特点:
任务优先级
周期定时任务
流量控制???????
基于时间周期或前链标签的重抓取调度
Self_update_projects() : 从projectdb中检查project,是否有过期,需不需要重爬
Self _check_task_done() : 从消息队列中取出消息(task)
Self_check_request() :
Self] _check_cronjob() :
Self_check_select() :
Self_check_delete() : 检查是否有需要删除的project,pyspider默认Status为STOP,且24小时之后自行删除
Self _try_dump_cnt() :
fetcher
dataurl支持,用于假抓取模拟传递
method, header, cookies, proxy, etag, last_modified, timeout等等抓取调度控制
从task中获得url
callback默认为None
fetch判断是否使用异步(默认全部使用)
判断url类型,其实就是判断是否使用phantomjs(ps:这边的startwith=data没懂)判断是否是js, splash。若都不是,则为普通的HTTP请求
Http_fetch可以看到就是处理cookie,重定向,robots.txt等一系列的方法
processor
内置的PyQuery,以jQuery解析页面
在脚本中完全控制调度抓取的各项参数
可以向后链传递信息
异常捕获
我还没具体看,简单的看了一眼先得出以下结论:
去取来自fetcher的task,调用task中process变量的callback函数(python脚本,存在projectdb中)
将合适的数据输出到result
有其他后续任务则重新放入消息队列并返回到scheduler中。
webui
前端页面是用Flask框架搭建的Web页面,具有以下功能:
web 的可视化任务监控
web 脚本编写,单步调试
异常捕获、log捕获、print捕获等
从别的地方复制过来的:
Pyspider的架构设计
pyspider爬虫可以分为下面几个核心组件:
Fetcher - 根据url抓取互联网资源,下载html内容。Fetcher通过异步IO的方式实现,可以支持很大并发量的抓取,瓶颈主要在IO开销和IP资源上。单个ip如果爬取过快,很容易触动了bbs的反爬虫系统,很容易被屏蔽,可以使用ip代理池的方式解决ip限制的问题。如果没有ip代理池可以通过pyspider的限速机制,防止触碰反爬虫发机制。支持多节点部署。
Processor - 处理我们编写的爬虫脚本。比如,提取页面中的链接,提取翻页链接,提取页面中的详细信息等,这块比较消耗CPU资源。支持多节点部署。
WebUI - 可视化的界面,支持在线编辑、调试爬虫脚本;支持爬虫任务的实时在线监控;可通过界面启动、停止、删除、限速爬虫任务。支持多节点部署。
Scheduler - 定时任务组件。每个url对应一个task,scheduler负责task的分发,新的url的入库,通过消息队列协调各个组件。只能单节点部署。
ResultWorker - 结果写入组件。支持爬虫结果的自定义实现,比如我们实现了基于RDS的自定义结果写入。可以不实现,默认采用sqlite作为结果输出,可以导出为execel,json等格式。
单机架构图:
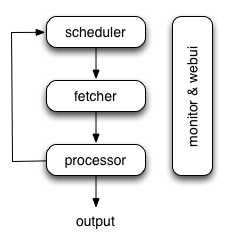
详细流程:
- 1步: 用户通过WebUI界面写好脚本,调试、保存好之后,点击Run启动爬虫脚本。WebUI会通过xmlrpc的方式调用scheduler的new_task方法,创建新的爬虫任务。
- 2步:scheduler通过xmlrpc的方式得到爬虫任务后(json_string定义),开始了一些更新项目状态,更新优先级,更新时间等处理。处理完这些逻辑后,通过send_task方法把url发往fetcher。
- ·3步:fetcher通过异步IO的方式抓取html页面,然后把结果发往processor。
- ·4步:processor拿到fetcher发过来的html页面后,调用用户的index_page方法。在 index_page方法中获取页面中的超链接,同时回调detial_page方法。Processor把解析后的结果发送到ResultWorker
- ·5步: ResultWorker获取到最终的结果,写入储存介质中
- 7步:processor中的index_page除了可以提取所需页面的详情外,还可以获取翻页链接,然后把获取后的分页链接发往scheduler,从而形成一整个闭环。
集群环境下:
Fetcher, Processor, Scheduler, ResultWorker,它们均通过Redis的队列(基于list实现)互相通信,Scheduler是控制中,负责爬虫任务(task)的分发。一个url的爬虫就是一个task,task对象中有task_id,默认基于url的md5值实现,用于url去重。每个task都有一个默认的优先级,用户可以使用@priority在index_page和detail_page方法上使用;通过自定义优先级,我们可以实现页面的深度优先或广度优先的遍历。
以上是关于Pyspide的主要内容,如果未能解决你的问题,请参考以下文章