urlparse模块
Posted chillytao-suiyuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了urlparse模块相关的知识,希望对你有一定的参考价值。
urlparse模块中为操作URL字符串提供了3种方法:
urlparse()
urlunparse()
urljoin()
1.urlparse()方法主要将URL字符串拆分成一个6元素元组
>>> from urllib.parse import urlparse >>> url = "http://www.cnblogs.com/thunderLL/p/6643022.html?pid=‘8766352‘" >>> url_turple = urlparse(url) >>> for i,each in enumerate(url_turple): print(i,each) 0 http 1 www.cnblogs.com 2 /thunderLL/p/6643022.html 3 4 pid=‘8766352‘ 5 >>>
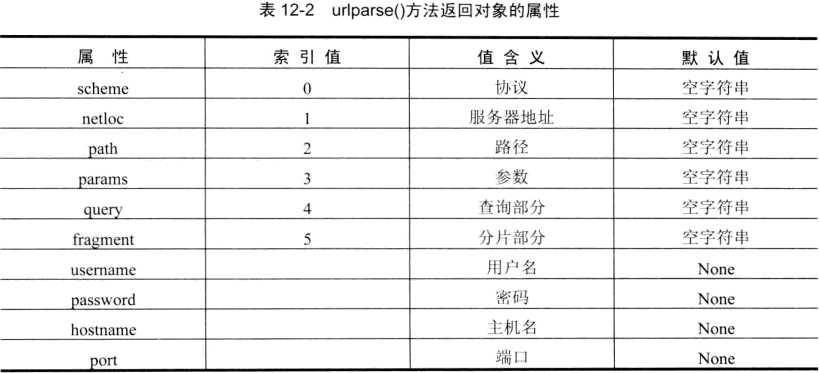
2.urlunparse()方法主要将URL的6元素元组变成url路径;与urlparse方法作用相反
>>> from urllib.parse import urlunparse
>>> path = urlunparse((‘http‘,‘www.cnblogs.com‘,‘/thunderLL/p/6643022.html‘,‘‘,‘pid=8766352‘,‘‘))
>>> path
‘http://www.cnblogs.com/thunderLL/p/6643022.html?pid=8766352‘
3.urljoin()方法

>>> from urllib.parse import urljoin >>> url1 = urljoin(‘http://www.baidu.com/admin/‘,‘module-urllib2/request-objects.html‘) >>> url1 ‘http://www.baidu.com/admin/module-urllib2/request-objects.html‘ >>> url2 = urljoin(‘http://www.baidu.com/admin‘,‘module-urllib2/request-objects.html‘) >>> url2 ‘http://www.baidu.com/module-urllib2/request-objects.html‘
urljoin()方法拼接两个URL(基地址和相对地址)得到的地址url1和url2,这两个URL区别在于基地址后面有无/,导致的运行结果存在差异
URL基地址后面没有/则该处会被替换掉
以上是关于urlparse模块的主要内容,如果未能解决你的问题,请参考以下文章