Docker三剑客之Docker Swarm
Posted zhujingzhi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Docker三剑客之Docker Swarm相关的知识,希望对你有一定的参考价值。
一、什么是Docker Swarm

Swarm是Docker公司推出的用来管理docker集群的平台,几乎全部用GO语言来完成的开发的,代码开源在https://github.com/docker/swarm, 它是将一群Docker宿主机变成一个单一的虚拟主机,Swarm使用标准的Docker API接口作为其前端的访问入口,换言之,各种形式的Docker
Client(compose,docker-py等)均可以直接与Swarm通信,甚至Docker本身都可以很容易的与Swarm集成,这大大方便了用户将原本基于单节点的系统移植到Swarm上,同时Swarm内置了对Docker网络插件的支持,用户也很容易的部署跨主机的容器集群服务。
Docker Swarm 和 Docker Compose 一样,都是 Docker 官方容器编排项目,但不同的是,Docker Compose 是一个在单个服务器或主机上创建多个容器的工具,而 Docker Swarm 则可以在多个服务器或主机上创建容器集群服务,对于微服务的部署,显然 Docker Swarm 会更加适合。
从 Docker 1.12.0 版本开始,Docker Swarm 已经包含在 Docker 引擎中(docker swarm),并且已经内置了服务发现工具,我们就不需要像之前一样,再配置 Etcd 或者 Consul 来进行服务发现配置了。
Swarm deamon只是一个调度器(Scheduler)加路由器(router),Swarm自己不运行容器,它只是接受Docker客户端发来的请求,调度适合的节点来运行容器,这就意味着,即使Swarm由于某些原因挂掉了,集群中的节点也会照常运行,放Swarm重新恢复运行之后,他会收集重建集群信息。
二、Docker Swarm 基本结构图
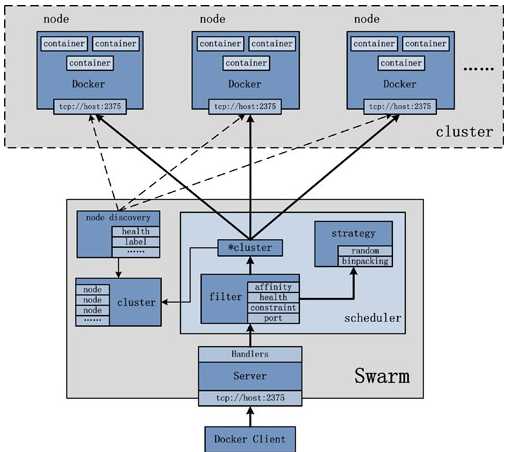
在结构图可以看出 Docker Client使用Swarm对 集群(Cluster)进行调度使用。
上图可以看出,Swarm是典型的master-slave结构,通过发现服务来选举manager。manager是中心管理节点,各个node上运行agent接受manager的统一管理,集群会自动通过Raft协议分布式选举出manager节点,无需额外的发现服务支持,避免了单点的瓶颈问题,同时也内置了DNS的负载均衡和对外部负载均衡机制的集成支持
三.Swarm的几个关键概念
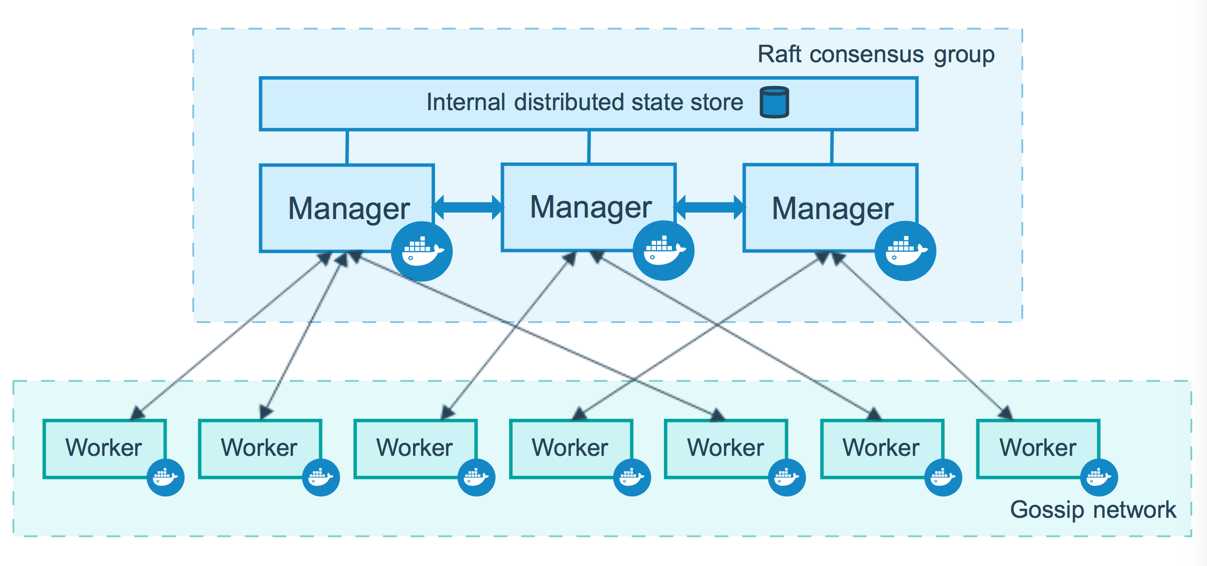
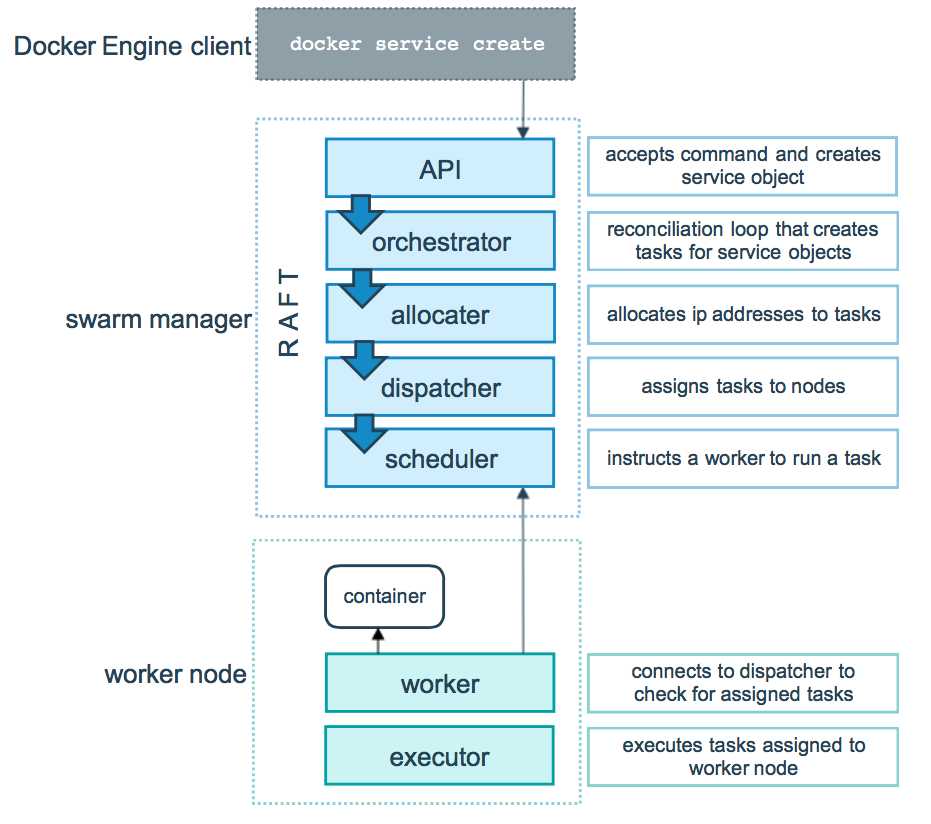
1.Swarm 集群的管理和编排是使用嵌入docker引擎的SwarmKit,可以在docker初始化时启动swarm模式或者加入已存在的swarm 2.Node 一个节点是docker引擎集群的一个实例。您还可以将其视为Docker节点。您可以在单个物理计算机或云服务器上运行一个或多个节点,但生产群集部署通常包括分布在多个物理和云计算机上的Docker节点。 要将应用程序部署到swarm,请将服务定义提交给 管理器节点。管理器节点将称为任务的工作单元分派 给工作节点。 Manager节点还执行维护所需群集状态所需的编排和集群管理功能。Manager节点选择单个领导者来执行编排任务。 工作节点接收并执行从管理器节点分派的任务。默认情况下,管理器节点还将服务作为工作节点运行,但您可以将它们配置为仅运行管理器任务并且是仅管理器节点。代理程序在每个工作程序节点上运行,并报告分配给它的任务。工作节点向管理器节点通知其分配的任务的当前状态,以便管理器可以维持每个工作者的期望状态。 3.Service 一个服务是任务的定义,管理机或工作节点上执行。它是群体系统的中心结构,是用户与群体交互的主要根源。创建服务时,你需要指定要使用的容器镜像。 4.Task 任务是在docekr容器中执行的命令,Manager节点根据指定数量的任务副本分配任务给worker节点 ------------------------------------------使用方法------------------------------------- docker swarm:集群管理,子命令有init, join, leave, update。(docker swarm --help查看帮助) docker service:服务创建,子命令有create, inspect, update, remove, tasks。(docker service--help查看帮助) docker node:节点管理,子命令有accept, promote, demote, inspect, update, tasks, ls, rm。(docker node --help查看帮助) node是加入到swarm集群中的一个docker引擎实体,可以在一台物理机上运行多个node,node分为: manager nodes,也就是管理节点 worker nodes,也就是工作节点 1)manager node管理节点:执行集群的管理功能,维护集群的状态,选举一个leader节点去执行调度任务。 2)worker node工作节点:接收和执行任务。参与容器集群负载调度,仅用于承载task。 3)service服务:一个服务是工作节点上执行任务的定义。创建一个服务,指定了容器所使用的镜像和容器运行的命令。 service是运行在worker nodes上的task的描述,service的描述包括使用哪个docker 镜像,以及在使用该镜像的容器中执行什么命令。 4)task任务:一个任务包含了一个容器及其运行的命令。task是service的执行实体,task启动docker容器并在容器中执行任务。
四、Swarm的工作模式
1. Node
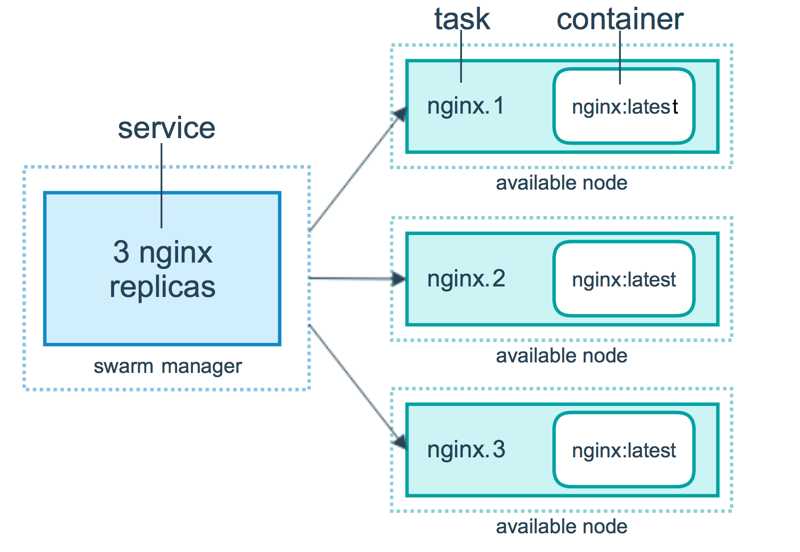
2. Service
3. 任务与调度
4. 服务副本与全局服务
五、Swarm的调度策略
Swarm在调度(scheduler)节点(leader节点)运行容器的时候,会根据指定的策略来计算最适合运行容器的节点,目前支持的策略有:spread, binpack, random. 1)Random 顾名思义,就是随机选择一个Node来运行容器,一般用作调试用,spread和binpack策略会根据各个节点的可用的CPU, RAM以及正在运 行的容器的数量来计算应该运行容器的节点。 2)Spread 在同等条件下,Spread策略会选择运行容器最少的那台节点来运行新的容器,binpack策略会选择运行容器最集中的那台机器来运行新的节点。 使用Spread策略会使得容器会均衡的分布在集群中的各个节点上运行,一旦一个节点挂掉了只会损失少部分的容器。 3)Binpack Binpack策略最大化的避免容器碎片化,就是说binpack策略尽可能的把还未使用的节点留给需要更大空间的容器运行,尽可能的把容器运行在 一个节点上面。
六、Swarm Cluster模式特性
1)批量创建服务 建立容器之前先创建一个overlay的网络,用来保证在不同主机上的容器网络互通的网络模式 2)强大的集群的容错性 当容器副本中的其中某一个或某几个节点宕机后,cluster会根据自己的服务注册发现机制,以及之前设定的值--replicas n, 在集群中剩余的空闲节点上,重新拉起容器副本。整个副本迁移的过程无需人工干预,迁移后原本的集群的load balance依旧好使! 不难看出,docker service其实不仅仅是批量启动服务这么简单,而是在集群中定义了一种状态。Cluster会持续检测服务的健康状态 并维护集群的高可用性。 3)服务节点的可扩展性 Swarm Cluster不光只是提供了优秀的高可用性,同时也提供了节点弹性扩展或缩减的功能。当容器组想动态扩展时,只需通过scale 参数即可复制出新的副本出来。 仔细观察的话,可以发现所有扩展出来的容器副本都run在原先的节点下面,如果有需求想在每台节点上都run一个相同的副本,方法 其实很简单,只需要在命令中将"--replicas n"更换成"--mode=global"即可! 复制服务(--replicas n) 将一系列复制任务分发至各节点当中,具体取决于您所需要的设置状态,例如“--replicas 3”。 全局服务(--mode=global) 适用于集群内全部可用节点上的服务任务,例如“--mode global”。如果大家在 Swarm 集群中设有 7 台 Docker 节点,则全部节点之上都将存在对应容器。 4. 调度机制 所谓的调度其主要功能是cluster的server端去选择在哪个服务器节点上创建并启动一个容器实例的动作。它是由一个装箱算法和过滤器 组合而成。每次通过过滤器(constraint)启动容器的时候,swarm cluster 都会调用调度机制筛选出匹配约束条件的服务器,并在这上面运行容器。 ------------------Swarm cluster的创建过程包含以下三个步骤---------------------- 1)发现Docker集群中的各个节点,收集节点状态、角色信息,并监视节点状态的变化 2)初始化内部调度(scheduler)模块 3)创建并启动API监听服务模块 一旦创建好这个cluster,就可以用命令docker service批量对集群内的容器进行操作,非常方便! 在启动容器后,docker 会根据当前每个swarm节点的负载判断,在负载最优的节点运行这个task任务,用"docker service ls" 和"docker service ps + taskID" 可以看到任务运行在哪个节点上。容器启动后,有时需要等待一段时间才能完成容器创建。
七、Docker Swarm 服务发现
八、Dcoker Swarm 集群部署
温馨提示:
机器环境(三台机器,centos系统)
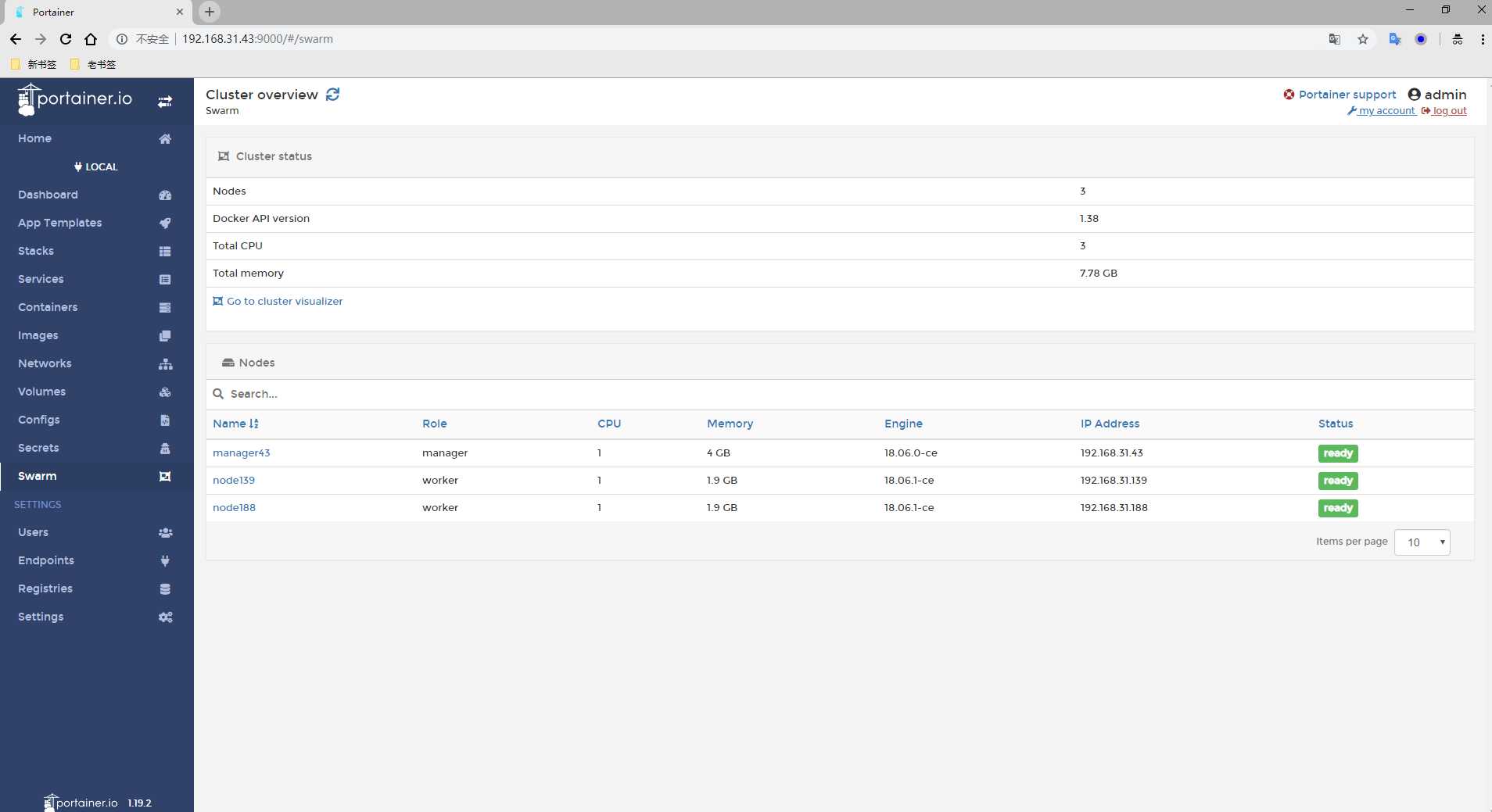
IP:192.168.31.43 主机名:manager43 担任角色:swarm manager
IP:192.168.31.188 主机名:node188 担任角色:swarm node
IP:192.168.31.139 主机名:node139 担任角色:swarm node
1、准备工作
1) 修改主机名 # 192.168.31.43 主机上执行 [[email protected] ~]# hostnamectl set-hostname manager43 # 192.168.31.188 主机上执行 [[email protected] ~]# hostnamectl set-hostname node188 # 192.168.31.139 主机上执行 [[email protected] ~]# hostnamectl set-hostname node139 2)配置hosts文件(可配置可不配置) [[email protected] ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.31.43 manager43 192.168.31.188 node188 192.168.31.139 node139 # 使用scp复制到node主机 [[email protected] ~]# scp /etc/hosts [email protected]:/etc/hosts [[email protected] ~]# scp /etc/hosts [email protected]:/etc/hosts 3) 设置防火墙 关闭三台机器上的防火墙。如果开启防火墙,则需要在所有节点的防火墙上依次放行2377/tcp(管理端口)、7946/udp(节点间通信端口)、4789/udp(overlay 网络端口)端口。 [[email protected] ~]# systemctl disable firewalld.service [[email protected] ~]# systemctl stop firewalld.service 4) 安装docker并配置加速器(在三台主机都要安装哟...) [[email protected] ~]# yum -y install docker [[email protected] ~]# yum -y install docker [[email protected] ~]# yum -y install docker
也可以安装最新版docker,可查考:docker安装教程
加速器配置,可查考:docker加速器配置教程
2、创建Swarm并添加节点
1) 创建Swarm集群 [[email protected] ~]# docker swarm init --advertise-addr 192.168.31.43 Swarm initialized: current node (z2n633mty5py7u9wyl423qnq0) is now a manager. To add a worker to this swarm, run the following command: # 这就是添加节点的方式(要保存初始化后token,因为在节点加入时要使用token作为通讯的密钥) docker swarm join --token SWMTKN-1-2lefzq18zohy9yr1vskutf1sfb2a590xz9d0mjj2m15zu9eprw-2938j5f50t35ycut0vbj2sx0s 192.168.31.43:2377 To add a manager to this swarm, run ‘docker swarm join-token manager‘ and follow the instructions. 上面命令执行后,该机器自动加入到swarm集群。这个会创建一个集群token,获取全球唯一的 token,作为集群唯一标识。后续将其他节点加入集群都会用到这个token值。 其中,--advertise-addr参数表示其它swarm中的worker节点使用此ip地址与manager联系。命令的输出包含了其它节点如何加入集群的命令。 这里无意中遇到了一个小小的问题: # 在次执行上面的命令,回报下面的错误 [[email protected] ~]# docker swarm init --advertise-addr 192.168.31.43 Error response from daemon: This node is already part of a swarm. Use "docker swarm leave" to leave this swarm and join another one. # 解决方法 [[email protected] ~]# docker swarm leave -f 这里的leave就是在集群中删除节点,-f参数强制删除,执行完在重新执行OK 2) 查看集群的相关信息 [[email protected] ~]# docker info 上面的命令执行后 找到Swarm的关键字,就可以看到相关信息了 [[email protected] ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION 3jcmnzjh0e99ipgshk1ykuovd * manager43 Ready Active Leader 18.06.0-ce 上面的命令是查看集群中的机器(注意上面node ID旁边那个*号表示现在连接到这个节点上) 3) 添加节点主机到Swarm集群 上面我们在创建Swarm集群的时候就已经给出了添加节点的方法 # 192.168.31.188 主机上执行 [[email protected] ~]# docker swarm join --token SWMTKN-1-2lefzq18zohy9yr1vskutf1sfb2a590xz9d0mjj2m15zu9eprw-2938j5f50t35ycut0vbj2sx0s 192.168.31.43:2377 This node joined a swarm as a worker. # 192.168.31.139 主机上执行 [[email protected] ~]# docker swarm join --token SWMTKN-1-2lefzq18zohy9yr1vskutf1sfb2a590xz9d0mjj2m15zu9eprw-2938j5f50t35ycut0vbj2sx0s 192.168.31.43:2377 This node joined a swarm as a worker. 如果想要将其他更多的节点添加到这个swarm集群中,添加方法如上一致 在manager43主机上我们可以看一下集群中的机器及状态 [[email protected] ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION 3jcmnzjh0e99ipgshk1ykuovd * manager43 Ready Active Leader 18.06.0-ce vww7ue2xprzg46bjx7afo4h04 node139 Ready Active 18.06.1-ce c5klw5ns4adcvumzgiv66xpyj node188 Ready Active 18.06.1-ce -------------------------------------------------------------------------------------------------------------------- 温馨提示:更改节点的availablity状态 swarm集群中node的availability状态可以为 active或者drain,其中: active状态下,node可以接受来自manager节点的任务分派; drain状态下,node节点会结束task,且不再接受来自manager节点的任务分派(也就是下线节点) [[email protected] ~]# docker node update --availability drain node139 # 将node139节点下线。如果要删除node139节点,命令是"docker node rm --force node139" node139 [[email protected] ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION 3jcmnzjh0e99ipgshk1ykuovd * manager43 Ready Active Leader 18.06.0-ce vww7ue2xprzg46bjx7afo4h04 node139 Ready Drain 18.06.1-ce c5klw5ns4adcvumzgiv66xpyj node188 Ready Active 18.06.1-ce 如上,当node1的状态改为drain后,那么该节点就不会接受task任务分发,就算之前已经接受的任务也会转移到别的节点上。 再次修改为active状态(及将下线的节点再次上线) [[email protected] ~]# docker node update --availability active node139 node139 [[email protected] ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION 3jcmnzjh0e99ipgshk1ykuovd * manager43 Ready Active Leader 18.06.0-ce vww7ue2xprzg46bjx7afo4h04 node139 Ready Active 18.06.1-ce c5klw5ns4adcvumzgiv66xpyj node188 Ready Active 18.06.1-ce
3、在Swarm中部署服务(nginx为例)
Docker 1.12版本提供服务的Scaling、health check、滚动升级等功能,并提供了内置的dns、vip机制,实现service的服务发现和负载均衡能力 1) 创建网络在部署服务 # 创建网络 [[email protected] ~]# docker network create -d overlay nginx_net a52jy33asc5o0ts0rq823bf0m [[email protected] ~]# docker network ls | grep nginx_net a52jy33asc5o nginx_net overlay swarm # 部署服务 [[email protected] ~]# docker service create --replicas 1 --network nginx_net --name my_nginx -p 80:80 nginx # 就创建了一个具有一个副本(--replicas 1 )的nginx服务,使用镜像nginx olexfmtdf94sxyeetkchwhehg overall progress: 1 out of 1 tasks 1/1: running [==================================================>] verify: Service converged 在manager-node节点上使用上面这个覆盖网络创建nginx服务: 其中,--replicas 参数指定服务由几个实例组成。 注意:不需要提前在节点上下载nginx镜像,这个命令执行后会自动下载这个容器镜像(比如此处创建tomcat容器,就将下面命令中的镜像改为tomcat镜像)。 # 使用 docker service ls 查看正在运行服务的列表 [[email protected] ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS olexfmtdf94s my_nginx replicated 1/1 nginx:latest *:80->80/tcp 2) 查询Swarm中服务的信息 -pretty 使命令输出格式化为可读的格式,不加 --pretty 可以输出更详细的信息: [[email protected] ~]# docker service inspect --pretty my_nginx ID: zs7fw4ereo5w7ohd4n9ii06nt Name: my_nginx Service Mode: Replicated Replicas: 1 Placement: UpdateConfig: Parallelism: 1 On failure: pause Monitoring Period: 5s Max failure ratio: 0 Update order: stop-first RollbackConfig: Parallelism: 1 On failure: pause Monitoring Period: 5s Max failure ratio: 0 Rollback order: stop-first ContainerSpec: Image: nginx:[email protected]:b73f527d86e3461fd652f62cf47e7b375196063bbbd503e853af5be16597cb2e Init: false Resources: Networks: nginx_net Endpoint Mode: vip Ports: PublishedPort = 80 Protocol = tcp TargetPort = 80 PublishMode = ingress # 查询到哪个节点正在运行该服务。如下该容器被调度到manager-node节点上启动了,然后访问http://192.168.31.43即可访问这个容器应用(如果调度到其他节点,访问也是如此) [[email protected] ~]# docker service ps my_nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS yzonph0zu7km my_nginx.1 nginx:latest manager43 Running Running about an hour ago 温馨提示:如果上面命令执行后,上面的 STATE 字段中刚开始的服务状态为 Preparing,需要等一会才能变为 Running 状态,其中最费时间的应该是下载镜像的过程 有上面命令可知,该服务在manager-node节点上运行。登陆该节点,可以查看到nginx容器在运行中 [[email protected] ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 0dc7103f8030 nginx:latest "nginx -g ‘daemon of…" About an hour ago Up About an hour 80/tcp my_nginx.1.yzonph0zu7km0211uj0ro5brj 3) 在Swarm中动态扩展服务(scale) 当然,如果只是通过service启动容器,swarm也算不上什么新鲜东西了。Service还提供了复制(类似kubernetes里的副本)功能。可以通过 docker service scale 命令来设置服务中容器的副本数 比如将上面的my_nginx容器动态扩展到4个 [[email protected] ~]# docker service scale my_nginx=4 my_nginx scaled to 4 overall progress: 4 out of 4 tasks 1/4: running [==================================================>] 2/4: running [==================================================>] 3/4: running [==================================================>] 4/4: running [==================================================>] verify: Service converged 和创建服务一样,增加scale数之后,将会创建新的容器,这些新启动的容器也会经历从准备到运行的过程,过一分钟左右,服务应该就会启动完成,这时候可以再来看一下 nginx 服务中的容器 [[email protected] ~]# docker service ps my_nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS yzonph0zu7km my_nginx.1 nginx:latest manager43 Running Running about an hour ago mlprstt9ds5x my_nginx.2 nginx:latest node139 Running Running 52 seconds ago y09lk90tdzdp my_nginx.3 nginx:latest node139 Running Running 52 seconds ago clolfl3zlvj0 my_nginx.4 nginx:latest node188 Running Running 2 minutes ago 可以看到,之前my_nginx容器只在manager-node节点上有一个实例,而现在又增加了3个实例。 这4个副本的my_nginx容器分别运行在这三个节点上,登陆这三个节点,就会发现已经存在运行着的my_nginx容器 4) 模拟宕机node节点 特别需要清楚的一点: 如果一个节点宕机了(即该节点就会从swarm集群中被踢出),则Docker应该会将在该节点运行的容器,调度到其他节点,以满足指定数量的副本保持运行状态。 比如: 将node139宕机后或将node139的docker服务关闭,那么它上面的task实例就会转移到别的节点上。当node139节点恢复后,它转移出去的task实例不会主动转移回来, 只能等别的节点出现故障后转移task实例到它的上面。使用命令"docker node ls",发现node139节点已不在swarm集群中了(状态为:Down)。 [[email protected] ~]# systemctl stop docker [[email protected] ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION ppk7q0bjond8a58xja7in1qid * manager43 Ready Active Leader 18.06.0-ce mums8azgbrffnecp3q8fz70pl node139 Down Active 18.06.1-ce z3n36maf03yjg7odghikuv574 node188 Ready Active 18.06.1-ce 然后过一会查询服务的状态列表 [[email protected] ~]# docker service ps my_nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS yzonph0zu7km my_nginx.1 nginx:latest manager43 Running Running about an hour ago wb1cpk9k22rl my_nginx.2 nginx:latest node188 Running Running about a minute ago mlprstt9ds5x \\_ my_nginx.2 nginx:latest node139 Shutdown Running 4 minutes ago rhbj4bcr4t2c my_nginx.3 nginx:latest manager43 Running Running about a minute ago y09lk90tdzdp \\_ my_nginx.3 nginx:latest node139 Shutdown Running 4 minutes ago clolfl3zlvj0 my_nginx.4 nginx:latest node188 Running Running 6 minutes ago 上面我们可以发现node139故障后,它上面之前的两个task任务已经转移到node188和manager43节点上了 登陆到node188和manager43节点上,可以看到这两个运行的task任务。当访问192.168.31.188和192.168.31.43节点的80端口,swarm的负载均衡会把请求路由到一个任意节点的可用的容器上 [[email protected] ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ae4c5c2e6f3f nginx:latest "nginx -g ‘daemon of…" 4 minutes ago Up 4 minutes 80/tcp my_nginx.3.rhbj4bcr4t2c3y2f8vyfmbi21 0dc7103f8030 nginx:latest "nginx -g ‘daemon of…" About an hour ago Up About an hour 80/tcp my_nginx.1.yzonph0zu7km0211uj0ro5brj [[email protected] ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES a63ef253f7dd nginx:latest "nginx -g ‘daemon of…" 3 minutes ago Up 3 minutes 80/tcp my_nginx.2.wb1cpk9k22rl1ydab7aozl2b5 74a1a1db81d4 nginx:latest "nginx -g ‘daemon of…" 8 minutes ago Up 8 minutes 80/tcp my_nginx.4.clolfl3zlvj0ewmh85c2ljnza 再次在node188和manager43节点上将从node139上转移过来的两个task关闭 [[email protected] ~]# docker stop my_nginx.3.rhbj4bcr4t2c3y2f8vyfmbi21 my_nginx.3.rhbj4bcr4t2c3y2f8vyfmbi21 [[email protected] ~]# docker stop my_nginx.2.wb1cpk9k22rl1ydab7aozl2b5 my_nginx.2.wb1cpk9k22rl1ydab7aozl2b5 再次查询服务的状态列表,发现这两个task又转移到node139上了 [[email protected] ~]# docker service ps my_nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS yzonph0zu7km my_nginx.1 nginx:latest manager43 Running Running 2 hours ago j2q61f8jtzba my_nginx.2 nginx:latest node188 Running Running 24 seconds ago wb1cpk9k22rl \\_ my_nginx.2 nginx:latest node188 Shutdown Complete 29 seconds ago mlprstt9ds5x \\_ my_nginx.2 nginx:latest node139 Shutdown Running 11 minutes ago oz9wyjuldw1t my_nginx.3 nginx:latest manager43 Running Running 40 seconds ago rhbj4bcr4t2c \\_ my_nginx.3 nginx:latest manager43 Shutdown Complete 45 seconds ago y09lk90tdzdp \\_ my_nginx.3 nginx:latest node139 Shutdown Running 11 minutes ago clolfl3zlvj0 my_nginx.4 nginx:latest node188 Running Running 12 minutes ago 结论:即在swarm cluster集群中启动的容器,在worker node节点上删除或停用后,该容器会自动转移到其他的worker node节点上 5) Swarm 动态缩容服务(scale) 同理,swarm还可以缩容,同样是使用scale命令 如下,将my_nginx容器变为1个 [[email protected] ~]# docker service scale my_nginx=1 my_nginx scaled to 1 overall progress: 1 out of 1 tasks 1/1: verify: Service converged [[email protected] ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS zs7fw4ereo5w my_nginx replicated 1/1 nginx:latest *:80->80/tcp [[email protected] ~]# docker service ps my_nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS yzonph0zu7km my_nginx.1 nginx:latest manager43 Running Running 11 hours ago wb1cpk9k22rl my_nginx.2 nginx:latest node188 Shutdown Complete 9 hours ago mlprstt9ds5x \\_ my_nginx.2 nginx:latest node139 Shutdown Shutdown 29 seconds ago rhbj4bcr4t2c my_nginx.3 nginx:latest manager43 Shutdown Complete 9 hours ago y09lk90tdzdp \\_ my_nginx.3 nginx:latest node139 Shutdown Shutdown 29 seconds ago 通过docker service ps my_nginx 可以看到node节点上已经为Shutdown状态了 在登录到node节点主机上查看 [[email protected] ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES f93c0a27374a nginx:latest "nginx -g ‘daemon of…" 9 hours ago Exited (0) 44 seconds ago my_nginx.2.j2q61f8jtzba9kb3unupkhl25 a63ef253f7dd nginx:latest "nginx -g ‘daemon of…" 9 hours ago Exited (0) 9 hours ago my_nginx.2.wb1cpk9k22rl1ydab7aozl2b5 [[email protected] ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e8ac2e44f5c4 nginx:latest "nginx -g ‘daemon of…" 9 hours ago Exited (0) 9 hours ago my_nginx.2.mlprstt9ds5xi48u1rzscgfdk 5b031aa5a2cc nginx:latest "nginx -g ‘daemon of…" 9 hours ago Exited (0) 9 hours ago my_nginx.3.y09lk90tdzdp8cwj6mm5oyr3f 登录node节点,使用docker ps -a 查看,会发现容器被stop而非rm 6) 除了上面使用scale进行容器的扩容或缩容之外,还可以使用docker service update 命令。 可对 服务的启动 参数 进行 更新/修改。 [[email protected] ~]# docker service update --replicas 3 my_nginx my_nginx overall progress: 3 out of 3 tasks 1/3: running [==================================================>] 2/3: running [==================================================>] 3/3: running [==================================================>] verify: Service converged [[email protected] ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS zs7fw4ereo5w my_nginx replicated 3/3 nginx:latest *:80->80/tcp [[email protected] ~]# docker service ps my_nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS yzonph0zu7km my_nginx.1 nginx:latest manager43 Running Running 11 hours ago j3hduzd9pret my_nginx.2 nginx:latest node188 Running Running 18 seconds ago wb1cpk9k22rl \\_ my_nginx.2 nginx:latest node188 Shutdown Complete 9 hours ago mlprstt9ds5x \\_ my_nginx.2 nginx:latest node139 Shutdown Shutdown 4 minutes ago gng96vc5vqpv my_nginx.3 nginx:latest node139 Running Running 18 seconds ago rhbj4bcr4t2c \\_ my_nginx.3 nginx:latest manager43 Shutdown Complete 9 hours ago y09lk90tdzdp \\_ my_nginx.3 nginx:latest node139 Shutdown Shutdown 4 minutes ago docker service update 命令,也可用于直接 升级 镜像等 [[email protected] ~]# docker service update --image nginx:new my_nginx [[email protected] ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS zs7fw4ereo5w my_nginx replicated 3/3 nginx:new *:80->80/tcp 注意IMAGE列 变成了nginx:new 7) 为了下面的直观显示,我这里把my_nginx服务直接删除了 [[email protected] ~]# docker service rm my_nginx 这样就会把所有节点上的所有容器(task任务实例)全部删除了
4、Swarm中使用Volume(挂在目录,mount命令)
1) 查看volume的帮助信息 [[email protected] ~]# docker volume --help Usage: docker volume COMMAND Manage volumes Commands: create Create a volume inspect Display detailed information on one or more volumes ls List volumes prune Remove all unused local volumes rm Remove one or more volumes Run ‘docker volume COMMAND --help‘ for more information on a command. 2) 创建一个volume [[email protected] ~]# docker volume create --name testvolume testvolume # 查看创建的volume [[email protected] ~]# docker volume ls DRIVER VOLUME NAME local testvolume # 查看volume详情 [[email protected] ~]# docker volume inspect testvolume [ { "CreatedAt": "2018-10-21T10:50:02+08:00", "Driver": "local", "Labels": {}, "Mountpoint": "/var/lib/docker/volumes/testvolume/_data", "Name": "testvolume", "Options": {}, "Scope": "local" } ] 3) 创建新的服务并挂载testvolume(nginx为例) [[email protected] ~]# docker service create --replicas 3 --mount type=volume,src=testvolume,dst=/zjz --name test_nginx nginx sh7wc8yzcvr0xaedo4tnraj7l overall progress: 3 out of 3 tasks 1/3: running [==================================================>] 2/3: running [==================================================>] 3/3: running [==================================================>] verify: Service converged 温馨提示: 参数src写成source也可以;dst表示容器内的路径,也可以写成target # 查看创建服务 [[email protected] ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS sh7wc8yzcvr0 test_nginx replicated 3/3 nginx:latest [[email protected] ~]# docker service ps test_nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS m7m41kwt4q6w test_nginx.1 nginx:latest node188 Running Running 56 seconds ago kayh81q1o1kx test_nginx.2 nginx:latest node139 Running Running 56 seconds ago eq11v0rcwy38 test_nginx.3 nginx:latest manager43 Running Running 56 seconds ago # 查看有没有挂载成功(登录各个节点的容器看看有没有指定的目录并创建文件测试) # 容器中操作 [[email protected] ~]# docker exec -it 63451219cb4e /bin/bash [email protected]:/# cd /zjz/ [email protected]:/zjz# ls [email protected]:/zjz# echo "gen wo xue docker" > docker.txt [email protected]:/zjz# ls docker.txt 执行docker volume inspect testvolume 可以看到本地的路径(上面已经执行过了) 本地路径:/var/lib/docker/volumes/testvolume/_data [[email protected] ~]# cd /var/lib/docker/volumes/testvolume/_data [[email protected] _data]# ls docker.txt [[email protected] _data]# cat docker.txt gen wo xue docker 还可以将node节点机上的volume数据目录做成软链接 [[email protected] _data]# ln -s /var/lib/docker/volumes/testvolume/_data /zjz [[email protected] _data]# cd /zjz/ [[email protected] zjz]# ls docker.txt [[email protected] zjz]# echo "123" > 1.txt [[email protected] zjz]# ll 总用量 8 -rw-r--r-- 1 root root 4 10月 21 11:04 1.txt -rw-r--r-- 1 root root 18 10月 21 11:00 docker.txt # 容器中查看 [[email protected] zjz]# docker exec -it 63451219cb4e /bin/bash [email protected]:/# cd /zjz/ [email protected]:/zjz# ls 1.txt docker.txt [email protected]:/zjz# cat 1.txt 123 [email protected]:/zjz# cat docker.txt gen wo xue docker # 还有一种挂载方式简单说一下吧,上面的会了下面的肯定简单 命令格式: docker service create --mount type=bind,target=/container_data/,source=/host_data/ 其中,参数target表示容器里面的路径,source表示本地硬盘路径 # 示例创建并挂载并使用网络 [[email protected] ~]# docker service create --replicas 1 --mount type=bind,target=/usr/share/nginx/html/,source=/opt/web/ --network nginx_net --name zjz_nginx -p 8880:80 nginx
5、多服务Swarm集群部署
问:上面我们只是对单独的一个nginx服务进行的集群部署,那如果要统一编排多个服务呢?
答:docker 三剑客中有个compose 这个就是对单机进行统一编排的,它的实现是通过docker-compose.yml的文件,这里我们就可以结合compose和swarm进行多服务的编排(docker compose教程)
温馨提示: 我们这里要部署的服务有三个(nginx服务,visualizer服务,portainer服务) 都是集群 GUI 管理服务 docker service部署的是单个服务,我们可以使用docker stack进行多服务编排部署 1) 编写docker-compose.yml文件 [[email protected] ~]# mkdir testswarm [[email protected] ~]# cd testswarm/ [[email protected] testswarm]# cat docker-compose.yml version: "3" services: nginx: image: nginx ports: - 8888:80 deploy: mode: replicated replocas: 3 visualizer: image: dockersamples/visualizer ports: - "8080:8080" volumes: - "/var/run/docker.sock:/var/run/docker.sock" deploy: replicas: 1 placement: constraints: [node.role == manager] portainer: image: portainer/portainer ports: - "9000:9000" volumes: - "/var/run/docker.sock:/var/run/docker.sock" deploy: replicas: 1 placement: constraints: [node.role == manager] 2) 通过这个yml文件部署服务 [[email protected] testswarm]# docker stack deploy -c docker-compose.yml deploy_deamon Creating network deploy_deamon_default Creating service deploy_deamon_portainer Creating service deploy_deamon_nginx Creating service deploy_deamon_visualizer 通过上面的执行过程可以看出这样创建会默认创建一个网络并使用它,名字都是我们给的名字的前缀加上服务名 # 查看创建服务 [[email protected] testswarm]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS xj2f1t5ax3nm deploy_deamon_nginx replicated 3/3 nginx:latest *:8888->80/tcp ky9qpldr5abb deploy_deamon_portainer replicated 1/1 portainer/portainer:latest *:9000->9000/tcp r47ff177x1ir deploy_deamon_visualizer replicated 1/1 dockersamples/visualizer:latest *:8080->8080/tcp [[email protected] testswarm]# docker service ps deploy_deamon_nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS z3v4uc1ujsnq deploy_deamon_nginx.1 nginx:latest node139 Running Running about a minute ago jhg3ups0cko5 deploy_deamon_nginx.2 nginx:latest manager43 Running Running about a minute ago 3e6guv791x21 deploy_deamon_nginx.3 nginx:latest node188 Running Running about a minute ago [[email protected] testswarm]# docker service ps deploy_deamon_portainer ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS whyuvy82cvvw deploy_deamon_portainer.1 portainer/portainer:latest manager43 Running Running about a minute ago [[email protected] testswarm]# docker service ps deploy_deamon_visualizer ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS wge5w1eqykg3 deploy_deamon_visualizer.1 dockersamples/visualizer:latest manager43 Running Starting 7 seconds ago
测试
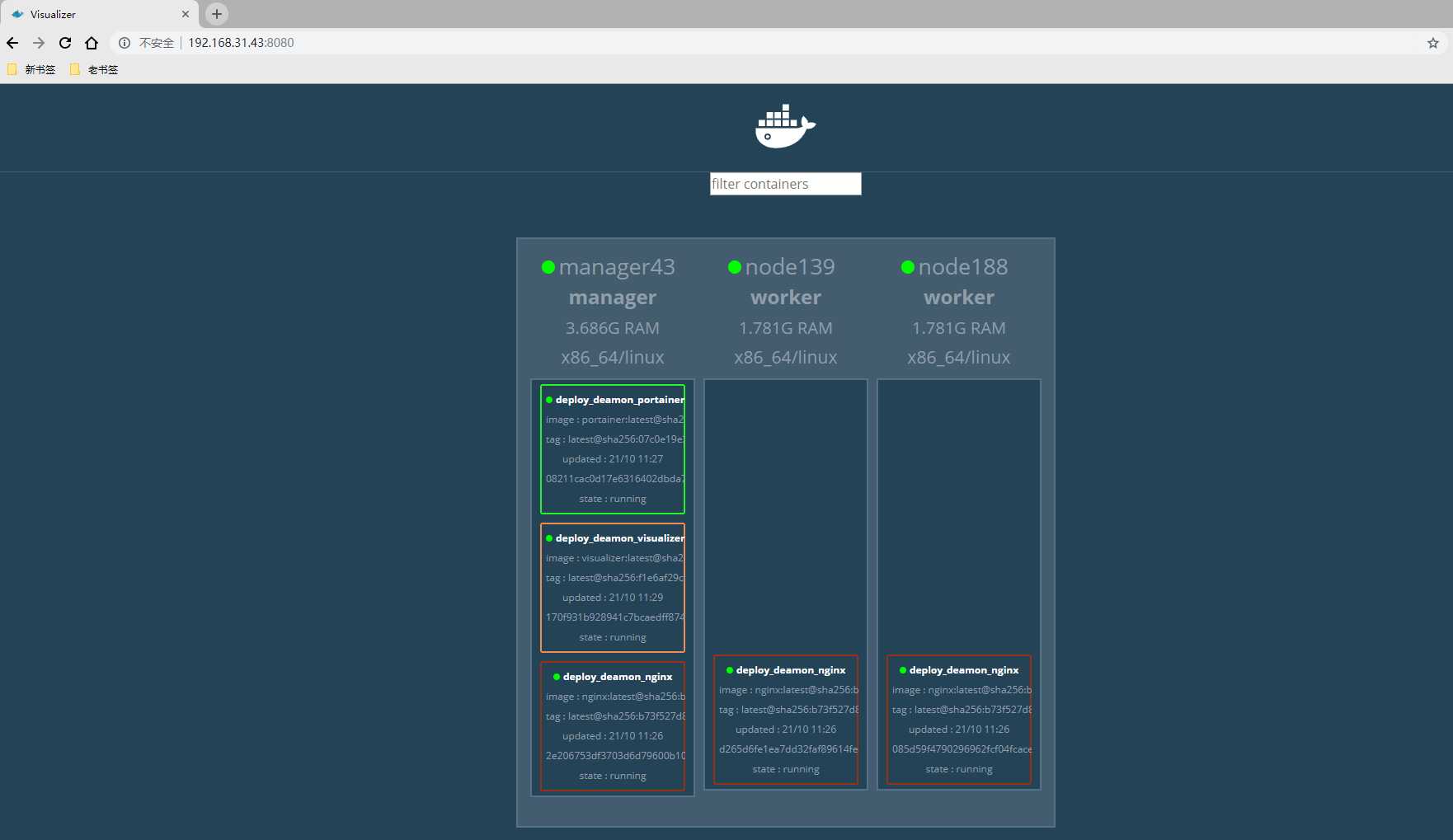
九、Docker Swarm 容器网络
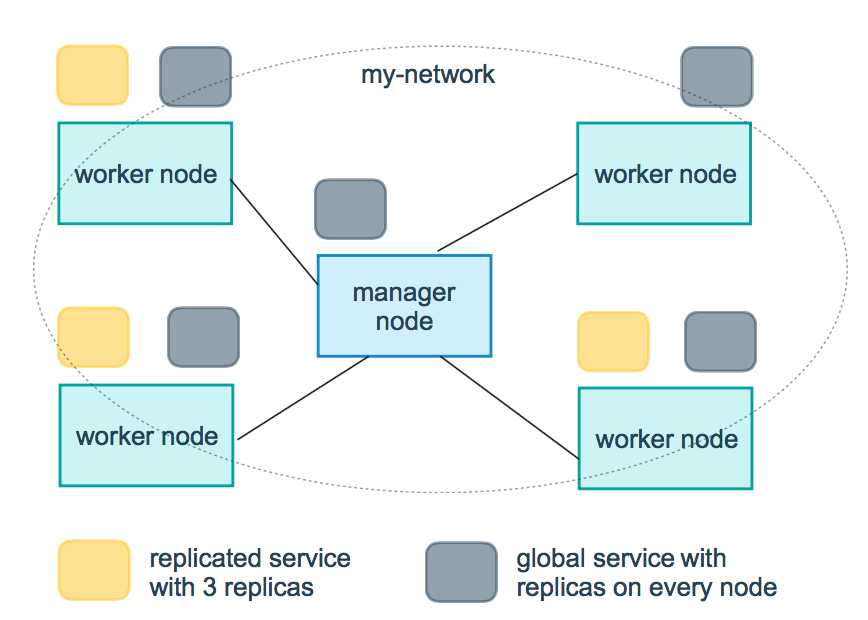
在Docker版本1.12之后swarm模式原生支持覆盖网络(overlay networks),可以先创建一个覆盖网络,然后启动容器的时候启用这个覆盖网络, 这样只要是这个覆盖网络内的容器,不管在不在同一个宿主机上都能相互通信,即跨主机通信!不同覆盖网络内的容器组之间是相互隔离的(相互ping不通)。 swarm模式的覆盖网络包括以下功能: 1)可以附加多个服务到同一个网络。 2)默认情况下,service discovery为每个swarm服务分配一个虚拟IP地址(vip)和DNS名称,使得在同一个网络中容器之间可以使用服务名称为互相连接。 3)可以配置使用DNS轮循而不使用VIP 4)为了可以使用swarm的覆盖网络,在启用swarm模式之间你需要在swarm节点之间开放以下端口: 5)TCP/UDP端口7946 – 用于容器网络发现 6)UDP端口4789 – 用于容器覆盖网络 实例如下: -----------在Swarm集群中创建overlay网络------------ [[email protected] ~]# docker network create --driver overlay --opt encrypted --subnet 10.10.19.0/24 ngx_net 参数解释: –opt encrypted 默认情况下swarm中的节点通信是加密的。在不同节点的容器之间,可选的–opt encrypted参数能在它们的vxlan流量启用附加的加密层。 --subnet 命令行参数指定overlay网络使用的子网网段。当不指定一个子网时,swarm管理器自动选择一个子网并分配给网络。 [[email protected] ~]# docker network ls NETWORK ID NAME DRIVER SCOPE d7aa48d3e485 bridge bridge local 9e637a97a3b9 docker_gwbridge bridge local b5a41c8c71e7 host host local 7f4fx3jf4dbr ingress overlay swarm 3x2wgugr6zmn ngx_net overlay swarm 0808a5c72a0a none null local 由上可知,Swarm当中拥有2套覆盖网络。其中"ngx_net"网络正是我们在部署容器时所创建的成果。而"ingress"覆盖网络则为默认提供。 Swarm 管理节点会利用 ingress 负载均衡以将服务公布至集群之外。 在将服务连接到这个创建的网络之前,网络覆盖到manager节点。上面输出的SCOPE为 swarm 表示将服务部署到Swarm时可以使用此网络。 在将服务连接到这个网络后,Swarm只将该网络扩展到特定的worker节点,这个worker节点被swarm调度器分配了运行服务的任务。 在那些没有运行该服务任务的worker节点上,网络并不扩展到该节点。 ------------------将服务连接到overlay网络------------------- [[email protected] ~]# docker service create --replicas 5 --network ngx_net --name my-test -p 80:80 nginx 上面名为"my-test"的服务启动了3个task,用于运行每个任务的容器都可以彼此通过overlay网络进行通信。Swarm集群将网络扩展到所有任务处于Running状态的节点上。 [[email protected] ~]# docker service ls ID NAME REPLICAS IMAGE COMMAND dsaxs6v463g9 my-test 5/5 nginx 在manager-node节点上,通过下面的命令查看哪些节点有处于running状态的任务: [[email protected] ~]# docker service ps my-test ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR 8433fuiy7vpu0p80arl7vggfe my-test.1 nginx node2 Running Running 2 minutes ago f1h7a0vtojv18zrsiw8j0rzaw my-test.2 nginx node1 Running Running 2 minutes ago ex73ifk3jvzw8ukurl8yu7fyq my-test.3 nginx node1 Running Running 2 minutes ago cyu73jd8psupfhken23vvmpud my-test.4 nginx manager-node Running Running 2 minutes ago btorxekfix4hcqh4v83dr0tzw my-test.5 nginx manager-node Running Running 2 minutes ago 可见三个节点都有处于running状态的任务,所以my-network网络扩展到三个节点上。 可以查询某个节点上关于my-network的详细信息: [[email protected] ~]# docker network inspect ngx_net [ { "Name": "ngx_net", "Id": "3x2wgugr6zmn1mcyf9k1du27p", "Scope": "swarm", "Driver": "overlay", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": null, "Config": [ { "Subnet": "10.10.19.0/24", "Gateway": "10.10.19.1" } ] }, "Internal": false, "Containers": { "00f47e38deea76269eb03ba13695ec0b0c740601c85019546d6a9a17fd434663": { "Name": "my-test.5.btorxekfix4hcqh4v83dr0tzw", "EndpointID": "ea962d07eee150b263ae631b8a7f8c1950337c11ef2c3d488a7c3717defd8601", "MacAddress": "02:42:0a:0a:13:03", "IPv4Address": "10.10.19.3/24", "IPv6Address": "" }, "957620c6f7abb44ad8dd2d842d333f5e5c1655034dc43e49abbbd680de3a5341": { "Name": "my-test.4.cyu73jd8psupfhken23vvmpud", "EndpointID": "f33a6e9ddf1dd01bcfc43ffefd19e19514658f001cdf9b2fbe23bc3fdf56a42a", "MacAddress": "02:42:0a:0a:13:07", "IPv4Address": "10.10.19.7/24", "IPv6Address": "" } }, "Options": { "com.docker.network.driver.overlay.vxlanid_list": "257" }, "Labels": {} } ] 从上面的信息可以看出在manager-node节点上,名为my-test的服务有一个名为my-test.5.btorxekfix4hcqh4v83dr0tzw和 my-test.4.cyu73jd8psupfhken23vvmpud的task连接到名为ngx_net的网络上(另外两个节点node1和node2同样可以用上面命令查看) [[email protected] ~]# docker network inspect ngx_net ....... "Containers": { "7d9986fad5a7d834676ba76ae75aff2258f840953f1dc633c3ef3c0efd2b2501": { "Name": "my-test.3.ex73ifk3jvzw8ukurl8yu7fyq", "EndpointID": "957ca19f3d5480762dbd14fd9a6a1cd01a8deac3e8e35b23d1350f480a7b2f37", "MacAddress": "02:42:0a:0a:13:06", "IPv4Address": "10.10.19.6/24", "IPv6Address": "" }, "9e50fceada1d7c653a886ca29d2bf2606debafe8c8a97f2d79104faf3ecf8a46": { "Name": "my-test.2.f1h7a0vtojv18zrsiw8j0rzaw", "EndpointID": "b1c209c7b68634e88e0bf5e100fe03435b3096054da6555c61e6c207ac651ac2", "MacAddress": "02:42:0a:0a:13:05", "IPv4Address": "10.10.19.5/24", "IPv6Address": "" } }, ......... [[email protected] web]# docker network inspect ngx_net ........ "Containers": { "4bdcce0ee63edc08d943cf4a049eac027719ff2dc14b7c3aa85fdddc5d1da968": { "Name": "my-test.1.8433fuiy7vpu0p80arl7vggfe", "EndpointID": "df58de85b0a0e4d128bf332fc783f6528d1f179b0f9f3b7aa70ebc832640d3bc", "MacAddress": "02:42:0a:0a:13:04", "IPv4Address": "10.10.19.4/24", "IPv6Address": "" } }, 可以通过查询服务来获得服务的虚拟IP地址,如下: [[email protected] ~]# docker service inspect --format=‘{{json .Endpoint.VirtualIPs}}‘ my-test [{"NetworkID":"7f4fx3jf4dbrp97aioc05pul4","Addr":"10.255.0.6/16"},{"NetworkID":"3x2wgugr6zmn1mcyf9k1du27p","Addr":"10.10.19.2/24"}] 由上结果可知,10.10.19.2其实就是swarm集群内部的vip,整个网络结构如下图所示:
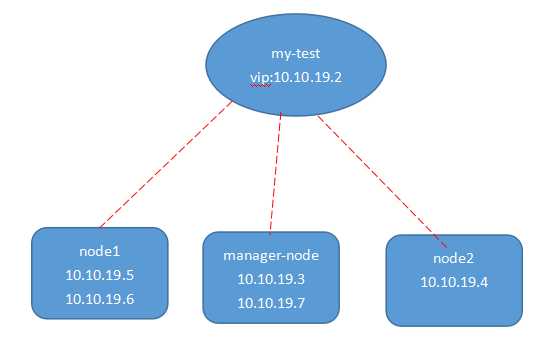
加入ngx_net网络的容器彼此之间可以通过IP地址通信,也可以通过名称通信。
[[email protected] ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 4bdcce0ee63e nginx:latest "nginx -g ‘daemon off" 22 minutes ago Up 22 minutes 80/tcp my-test.1.8433fuiy7vpu0p80arl7vggfe [[email protected] ~]# docker exec -ti 4bdcce0ee63e /bin/bash [email protected]:/# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 1786: [email protected]: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default link/ether 02:42:0a:ff:00:08 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.255.0.8/16 scope global eth0 valid_lft forever preferred_lft forever inet 10.255.0.6/32 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::42:aff:feff:8/64 scope link valid_lft forever preferred_lft forever 1788: [email protected]: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:12:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 1 inet 172.18.0.3/16 scope global eth1 valid_lft forever preferred_lft forever inet6 fe80::42:acff:fe12:3/64 scope link valid_lft forever preferred_lft forever 1791: [email protected]: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default link/ether 02:42:0a:0a:13:04 brd ff:ff:ff:ff:ff:ff link-netnsid 2 inet 10.10.19.4/24 scope global eth2 valid_lft forever preferred_lft forever inet 10.10.19.2/32 scope global eth2 valid_lft forever preferred_lft forever inet6 fe80::42:aff:fe0a:1304/64 scope link valid_lft forever preferred_lft forever [email protected]:/# ping 10.10.19.3 PING 10.10.19.3 (10.10.19.3): 56 data bytes 64 bytes from 10.10.19.3: icmp_seq=0 ttl=64 time=0.890 ms 64 bytes from 10.10.19.3: icmp_seq=1 ttl=64 time=0.622 ms .....- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max/stddev = 0.622/0.756/0.890/0.134 ms [email protected]:/# ping 10.10.19.6 PING 10.10.19.6 (10.10.19.6): 56 data bytes 64 bytes from 10.10.19.6: icmp_seq=0 ttl=64 time=0.939 ms 64 bytes from 10.10.19.6: icmp_seq=1 ttl=64 time=0.590 ms ----------------------------使用swarm模式的服务发现-------------------------- 默认情况下,当创建了一个服务并连接到某个网络后,swarm会为该服务分配一个VIP。此VIP根据服务名映射到DNS。在网络上的容器共享该服务的DNS映射, 所以网络上的任意容器可以通过服务名访问服务。 在同一overlay网络中,不用通过端口映射来使某个服务可以被其它服务访问。Swarm内部的负载均衡器自动将请求发送到服务的VIP上,然后分发到所有的 active的task上。 如下示例: 在同一个网络中添加了一个centos服务,此服务可以通过名称my-test访问前面创建的nginx服务: [[email protected] ~]# docker service create --name my-centos --network ngx_net centos 查询centos运行在哪个节点上(上面创建命令执行后,需要一段时间才能完成这个centos服务的创建) [[email protected] ~]# docker service ps my-centos ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR e03pqgkjs3l1qizc6v4aqaune my-centos.1 centos node2 Running Preparing 4 seconds ago 登录centos运行的节点(由上可知是node2节点),打开centos的交互shell: [[email protected] ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS NAMES e4554490d891 centos:latest "/bin/bash" About an hour ago Up About an hour my-centos.1.9yk5ie28gwk9mw1h1jovb68ki [[email protected] ~]# docker exec -ti my-centos.1.9yk5ie28gwk9mw1h1jovb68ki /bin/bash [email protected]:/# nslookup my-test Server: 127.0.0.11 Address 1: 127.0.0.11 Name: my-test Address 1: 10.10.19.2 10.10.19.2 从centos容器内部,使用特殊查询 查询DNS,来找到my-test服务的所有容器的IP地址: [email protected]:/# nslookup tasks.my-test Server: 127.0.0.11 Address 1: 127.0.0.11 Name: tasks.my-test Address 1: 10.10.19.4 my-test.1.8433fuiy7vpu0p80arl7vggfe Address 2: 10.10.19.5 my-test.2.f1h7a0vtojv18zrsiw8j0rzaw Address 3: 10.10.19.6 my-test.3.ex73ifk3jvzw8ukurl8yu7fyq Address 2: 10.10.19.7 my-test.4.cyu73jd8psupfhken23vvmpud Address 3: 10.10.19.3 my-test.5.btorxekfix4hcqh4v83dr0tzw 从centos容器内部,通过wget来访问my-test服务中运行的nginx网页服务器 [email protected]:/# wget -O- my-test Connecting to my-test (10.10.19.2:80) <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> ... Swarm的负载均衡器自动将HTTP请求路由到VIP上,然后到一个active的task容器上。它根据round-robin选择算法将后续的请求分发到另一个active的task上。 -----------------------------------为服务使用DNS round-robin----------------------------- 在创建服务时,可以配置服务直接使用DNS round-robin而无需使用VIP。这是通过在创建服务时指定 --endpoint-mode dnsrr 命令行参数实现的。 当你想要使用自己的负载均衡器时可以使用这种方式。 如下示例(注意:使用DNS round-robin方式创建服务,不能直接在命令里使用-p指定端口) [[email protected] ~]# docker service create --replicas 3 --name my-dnsrr-nginx --network ngx_net --endpoint-mode dnsrr nginx [[email protected] ~]# docker service ps my-dnsrr-nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR 65li2zbhxvvoaesndmwjokouj my-dnsrr-nginx.1 nginx node1 Running Running 2 minutes ago 5hjw7wm4xr877879m0ewjciuj my-dnsrr-nginx.2 nginx manager-node Running Running 2 minutes ago afo7acduge2qfy60e87liz557 my-dnsrr-nginx.3 nginx manager-node Running Running 2 minutes ago 当通过服务名称查询DNS时,DNS服务返回所有任务容器的IP地址: [email protected]:/# nslookup my-dnsrr-nginx Server: 127.0.0.11 Address 1: 127.0.0.11 Name: my-dnsrr-nginx Address 1: 10.10.19.10 my-dnsrr-nginx.3.0sm1n9o8hygzarv5t5eq46okn.my-network Address 2: 10.10.19.9 my-dnsrr-nginx.2.b3o1uoa8m003b2kk0ytl9lawh.my-network Address 3: 10.10.19.8 my-dnsrr-nginx.1.55za4c83jq9846rle6eigiq15.my-network 需要注意的是:一定要确认VIP的连通性 通常Docker官方推荐使用dig,nslookup或其它DNS查询工具来查询通过DNS对服务名的访问。因为VIP是逻辑IP,ping并不是确认VIP连通性的正确的工具。
以上是关于Docker三剑客之Docker Swarm的主要内容,如果未能解决你的问题,请参考以下文章