BTM学习小记
Posted kjkj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BTM学习小记相关的知识,希望对你有一定的参考价值。
BTM的原理跟LDA很像,下面是该模型的概率图:
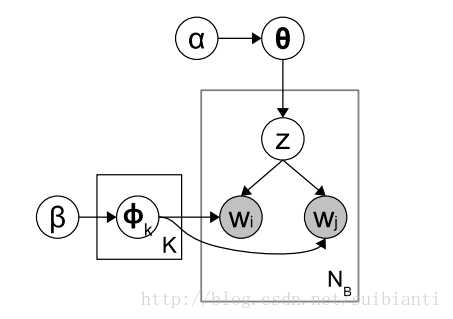
由该图可以看出来,与LDA的区别在于确定主题分布和词分布后相应地取两个词(而LDA只取一个,即类比常见的骰子说法:先投掷K面的骰子得到主题z,再根据相应的V面骰子,连续投掷两次,得到一对词汇),这俩词叫做biterm(就是在把一个文档分词之后,对这些词的设置一个距离指标,从第I个到第j个词之间两两结对,都可以看作一对biterm).从原文档得到biterm代码如下:
def build_Biterms(self, sentence):
"""
获取 document 的 biterms
:param sentence: word id list sentence 是切词后的每一词的ID 的列表
:return: biterm list
"""
win = 15 # 设置窗口大小
biterms = []
for i in xrange(len(sentence)-1):
for j in xrange(i+1, min(i+win+1, len(sentence))):
biterms.append(Biterm(int(sentence[i]),int(sentence[j])))
return biterms
BTM利用了整个文本集合来估计一个theta,解决了稀疏问题(我们通常有海量数据)。放宽了mixture of unigram中对整个文档必须同属于一个主题z的约束(相当于从整个文档放松到了窗口长度内的两个词),加强了LDA中每个词对应于一个Z的假设(BTM中约束了窗长内的两个词组成一个biterm对应于一个z)。这个假设很接近于人类认知,因为我们知道,通常在较短的一段文本内,topic变化不大。
以上是关于BTM学习小记的主要内容,如果未能解决你的问题,请参考以下文章