2017-2018-1 20155315 《信息安全系统设计基础》第13周学习总结
教材学习内容总结
- 本周老师让我们学习的是自己觉得最终要的一章,我学习的是第十章。在我看来,不论是什么产品,都存在设计端与使用端,更确切的说,正因为有使用端,才需要设计端。因此,使用端的使用感受最为重要,而作为一个对外的平台与程序,I/O系统是基础和核心,也因此我选择系统级I/O进行深入学习。
- 主要知识点:
- 输入是从I/O设备复制数据到主存
- 输出是从主存复制数据到I/O设备
UnixI/O
- 每个unix文件都是一个m字节的序列。
- unixI/O是由内核提供的。
- I/O设备都是文件,输入就是写文件,输出就是读文件。
- 程序要求内核打开文件来说明它想要访问相应的I/O设备,内存返回描述符,
fd = Open("文件名",flag参数,mode参数);,此时fd就是一个描述符。 - 每个进程都有三个文件,头文件是
- 文件位置k是字节偏移量,初始为0,用seek查找当前位置。
- 读是将文件复制n个字节到内存中,文件位置增加到k+n,当n大于文件字节的时候,会返回EOF错误,表示读到文章结尾。
文件
- 普通文件分文本文件和二进制文件,文本文件致函ASCII或Unicode字符。
- 对内核而言,文本文件和二进制文件没有区别
- 文本文件每一行都是字符序列
- 目录是一组包含链接的文件。
- 路径名是一个字符串,有绝对路径和相对路径。
打开和关闭文件
打开文件
int open(char *filename, int flags, mode_t mode)flags 行为 O_RDONLY 只读 O_WRONLY 只写 O_RDWR 可读可写 O_CREAT 文件不存在即创建一个截断文件 O_TRUNC 文件存在就截断 O_APPEND 写之前设置是文件在文件结尾 关闭文件
int close(int fd);
读写文件
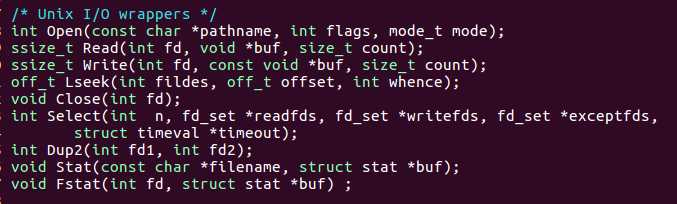
读文件
ssize_t Read(int fd, void *buf, size_t count);返回值 意义 -1 错误 0 读到文章末尾 其他 实际传送的字节数量 写文件
ssize_t Write(int fd, const void *buf, size_t count);一次一个字节地从标准输入复制到标准输出
#include "csapp.h" int main(void) { char c; while(read(STDIN_FILENO,&c,1)!=0) write(STDOUT_FILENO,&c,1); exit(0); }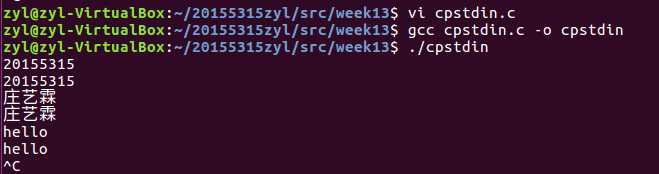
- ssize_t被定义为long,是有符号的;size_t被定义为unsigned long,是无符号数
- 可能出现不足值
- 读时遇到FOF
- 从终端读文本行
- 读和写网络套接字
RIO(Robust I/O)
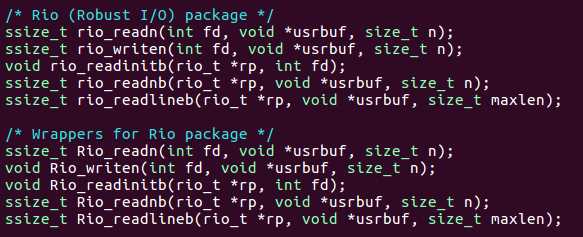
无缓冲的输入输出:直接在内存和文件之间传送数据
ssize_t rio_readn(int fd, void *usrbuf, size_t n); ssize_t rio_writen(int fd, void *usrbuf, size_t n);- read遇到EOF只能返回一个不足值,write不会返回不足值。
- 被中断时函数会重启read或write
带缓冲的输入输出:数据存在缓冲区
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n); ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen);- readlineb读取一行文本到缓冲区(包括换行符),用NULL(0)结束,最多读maxlen-1个字节
- rio_readnb读取n个字节到缓冲区
一次一行地从标准输入复制一个文本文件到标准输出
#include "csapp.h" int main(int argc,char **argv) { int n; rio_t rio; char buf[MAXLINE]; rio_readinitb(&rio,STDIN_FILENO); while((n=rio_readlineb(&rio,buf,MAXLINE))!=0) rio_writen(STDOUT_FILENO,buf,n); }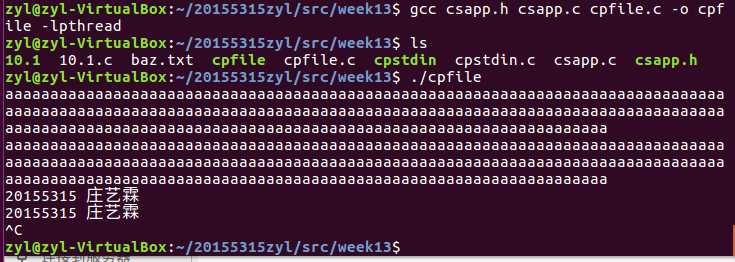
我的理解:读文件主要有三部分。一是init函数初始化,将文件描述符与读缓存区联系在一起;二是readline或readnb将文本复制到读缓存区;三是内部的read函数,当缓冲区为空,调用read填满,非空的时候,read从读缓存区复制字节到用户缓冲区,也就是说,涉及到两个缓冲。
读取
读取元数据
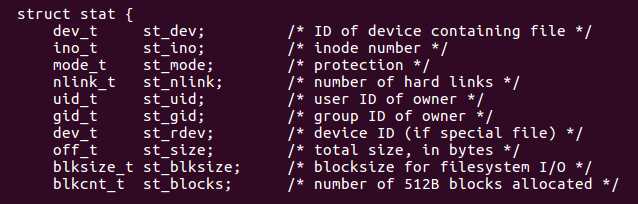
- stat函数以一个文件名作为输入,fstat以文件描述符作为输入
| st_mode | 文件访问许可位和文件类型 |
|---|---|
| S_ISREG(m) | 普通文件 |
| S_ISDIR(m) | 目录文件 |
| S_ISSOCK(m) | 网络套接字 |
查询和处理一个文件的st_mode位。
#include "csapp.h" int main(int argc,char **argv) { struct stat stat; char *type,*readok; Stat(argv[1],&stat); if(S_ISREG(stat.st_mode)) type = "regular"; else if(S_ISDIR(stat.st_mode)) type = "directory"; else type = "other"; if((stat.st_mode & S_IRUSR)) readok = "yes"; else readok = "no"; printf("type:%s,read:%s\\n",type,readok); }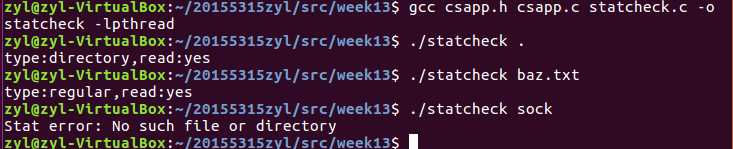
读取目录
opendir
readdir//返回inode和文件名,出错返回NULL,设置errno共享文件
- 描述符表:每个进程有一个独立的描述表,相当于本地文件
- 文件表:打开文件的集合,所有的进程共享,包括当前的文件地址、引用计数及一个指向v-node中对应项的指针,相当于总表
- v-node表:所有进程共享,包含stat中的大多数信息,相当于详情。
- 多个描述符可通过不同的文件表表项来引用同一个文件。
- 多进程时,子进程继承父进程,复制父进程的描述符表,在内核删除相应表项前,父子进程都要关闭描述符。
重定向
dup2函数,复制oldfd到newfd,若newfd已经打开,dup2会先关闭它。
标准I/O
练习题
10.1
代码
#include "csapp.h" int main() { int fd1,fd2; fd1=open("foo.txt",O_RDONLY,0); close(fd1); fd2=open("baz.txt",O_RDONLY,0); printf("fd2=%d\\n",fd2); exit(0); }- 运行结果
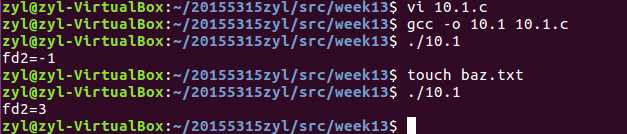
答案:Unix进程生命周期开始时,打开的描述符赋给了stdin(描述符0)、stdout((描述符1)和stderr(描述符2)。open函数总是返回最低的未打开的描述符,所以第一次调用open会返回描述符3,调用close函数会释放描述符3。最后对open的调用会返回描述符3,因此程序的翰出是“fd2=3”。当文件不存在是,输出“fd2=-1”
10.2
#include "csapp.h"
int main()
{
int fd1,fd2;
char c;
fd1=open("foobar.txt",O_RDONLY,0);
fd2=open("foobar.txt",O_RDONLY,0);
read(fd1,&c,1);
read(fd2,&c,1);
printf("c=%c\\n",c);
exit(0);
}- 运行结果

- 答案:fd2读操作读取foobar.txt的第一个字节。
10.3
#include "csapp.h"
int main()
{
int fd;
char c;
fd = open("foobar.txt",O_RDONLY,0);
if(fork()==0)
{
read(fd,&c,1);
exit(0);
}
wait(NULL);
read(fd,&c,1);
printf("c=%c\\n",c);
exit(0);
}
- 运行结果

- 答案:描述符fd在父子进程中都指向同一个打开文件表表项,当子进程读取文件的第一个字节时,文件位置加1。因此,父进程会读取第二个字节,也就是o
10.4
如何用dup2将标准输入重定向到描述符5?
回答:dup2(5,0)
10.5
#include "csapp.h"
int main()
{
int fd1,fd2;
char c;
fd1=open("foobar.txt",O_RDONLY,0);
fd2=open("foobar.txt",O_RDONLY,0);
read(fd2,&c,1);
dup2(fd2,fd1);
read(fd1,&c,1);
printf("c=%c\\n",c);
exit(0);
}- 答案:将fd1重定向到fd2,因此第二个fd1指的是fd2+1
- 运行结果

回答:将fdl重定向到了fd2,输出实际上是c=o
教材学习中的问题和解决过程
问题1: 使用带缓存的RIO包的时候,为什么要先设定一个缓存区,再将其中的数据转移到缓冲区呢?
解决1:
带缓冲的I/O是指进程对输入输出流进行了改进,提供了一个流缓冲,当用fwrite函数网磁盘写数据时,先把数据写入流缓冲区中,当达到一定条件,比如流缓冲区满了,或刷新流缓冲,这时候才会把数据一次送往内核提供的块缓冲,再经块缓冲写入磁盘。
也就是说,如果直接将数据写入缓存区就系统调用,与不带缓存的RIO是一样的,设定双重缓冲是为保证算法的效率,减少系统调用的次数。
问题2: 为什么使用一个static缓冲区就不是线程安全的?什么是线程安全?
解决2:
非线程安全是指多线程操作同一个对象可能会出现问题。而线程安全则是多线程操作同一个对象不会有问题。
我的理解:static缓冲区是静态的,就好像是静态变量一样,本地操作即单一线程调用的时候是不会出错的,但它不是可以共享的,也就是说其他线程调用的时候就可能出现问题。
代码学习中的问题和解决过程
问题1: 编译书p629代码时

解决1: 将csapp.c、csapp.h和cpfile.c编译在一起gcc csapp.h csapp.c cpfile.c -o cpfile -lpthread
问题2: 编译书p634代码时
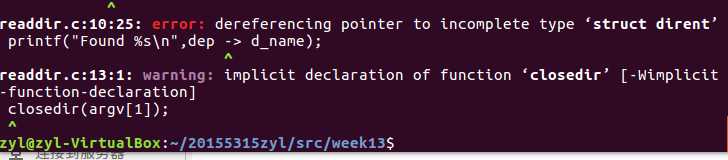
解决2: 使用man readdir发现有一个系统调用版本和c版本,使用man 3 readdir发现在csapp.h中缺少dirent.h头文件,加上之后编译通过,运行成功
代码托管
(statistics.sh脚本的运行结果截图)
结对及互评
其他(感悟、思考等,可选)
认真学习I/O相关知识后,知道了输入输出的更多知识,也了解到系统在处理输入输出的时候会操作什么改变什么,希望对今后的学习有所帮助。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 5/5 | 1/1 | 25/25 | |
| 第二周 | 236/241 | 3/4 | 30/55 | |
| 第三周 | 169/410 | 2/6 | 30/85 | |
| 第四周 | 169/410 | 2/8 | 50/135 | |
| 第五周 | 1177/1587 | 2/10 | 30/165 | |
| 第六周 | 1826/3413 | 2/12 | 30/195 | |
| 第七周 | 977/4390 | 3/15 | 30/225 | |
| 第八周 | 977/4390 | 2/17 | 30/255 | |
| 第九周 | 977/4390 | 2/19 | 30/285 | |
| 第十周 | 977/4390 | 0/15 | 30/315 | |
| 第十一周 | 977/4390 | 2/21 | 25/335 | |
| 第十二周 | 977/4390 | 0/21 | 25/360 | |
| 第十三周 | 977/4390 | 2/23 | 30/390 |
- 计划学习时间:20小时
- 实际学习时间:30小时
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)