图像搜索技术之visual words
Posted carlber
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像搜索技术之visual words相关的知识,希望对你有一定的参考价值。
谷歌的以图搜图技术就用到了图像搜索技术,以下就是介绍再过去的十年以图搜图技术的发展和技术点,现在的深度学习是如何做到以图搜图的。
以图搜图的检索又称为基于内容的检索(简称CBIR),如下图所示:
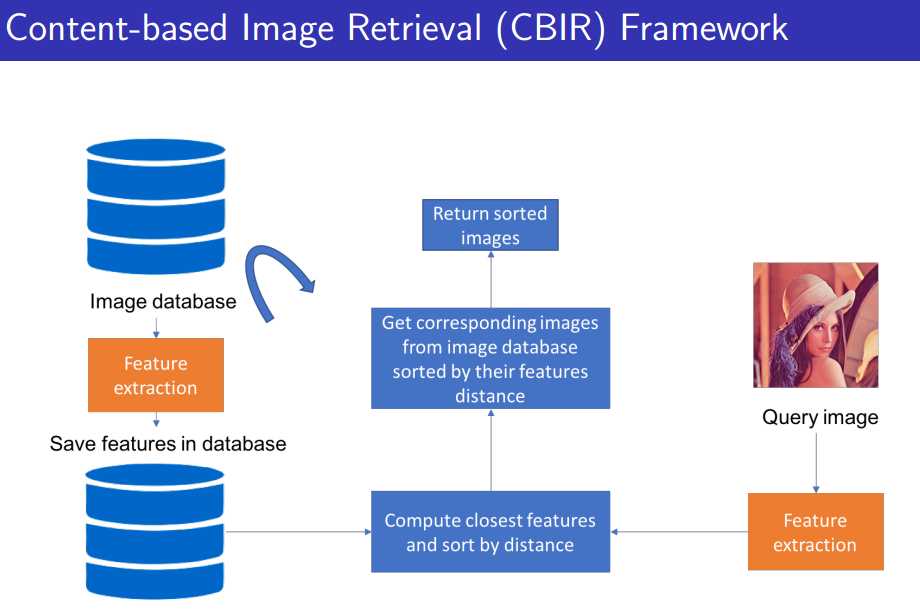
图像检索你肯定得有个图像的数据库(Image database),不然你的图像数据哪来的呢?然后你肯定得有个要查询的图片(Query Image),在image database 里面去检索要查询的图片,从图像的像素级别去比对,这肯定不太现实,运算量很大。所以这里就有了对图片进行特征提取,转化为特征向量的形式,这样的话就只需要在图像的向量空间去进行比对即可,也就是去计算一些余弦距离啊,L2距离啊,欧式距离啊等等。这样就得到了图像对比的结果。所以CBIR最重要的一点就是特征提取。不同的想法或者不同的工作其实就区别在我们的特征是怎么提取的。
上述提到的是把每张图片转化为一个特征向量的形式,但是在工业界是如何进行快速的实时响应呢?大家在用百度或谷歌的时候你扔一张图片其实它很快就检索出来了,基本上是毫秒级别的。但是大家想想看,如果你的Image Database中的图片非常多,尤其是搜索引擎这样的量级,肯定是以亿为最小的单位进行计算的。那这样的话两两之间的特征向量之间的距离计算肯定是非常耗时的,所以在工业界里边都有一种索引技术在里面,叫做哈希索引技术,如下图所示:
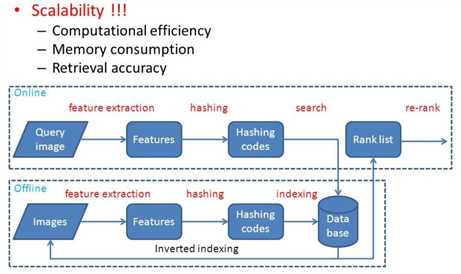
这个哈希的索引技术,就是会把图像的特征向量如2048维去映射到一个更小的子空间里面,比如说128维。并且这128维是不是0就是1的二进制码,叫做hashing codes。所以这里的计算是能大大大量减少的。首先维度减少,且都变成了二进制化的数。这样的技术既不减少比对的效果(可能从95%减少到94%,但是速度效率提高了成百上千倍),计算量还大大减少。
所以以上是CBIR里的关键技术,总的来说你不仅要玩特征,还要把特征玩的小,轻,快。接下来就是做以上两点的笔记。
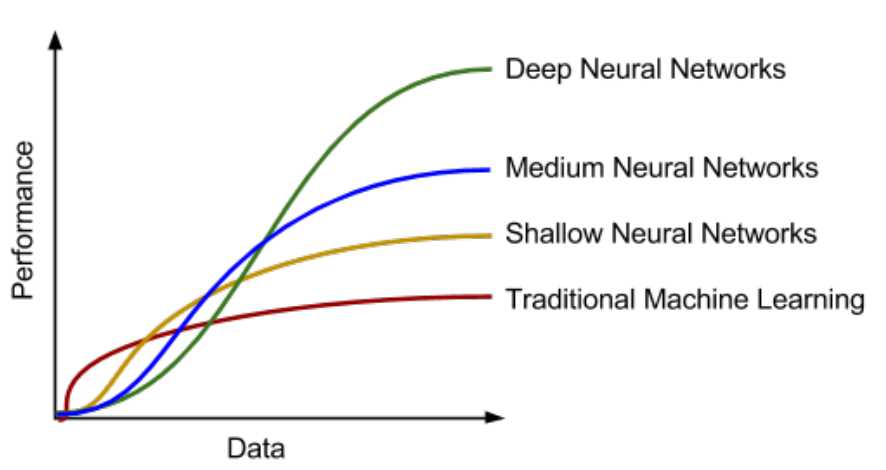
上边这张图是传统机器学习算法和深度学习算法随数据的增加性能的表现。这张图在面试中经常会遇到。会让你画这张图。因为传统的机器学习在数据量少的情况下还是很占优势的。
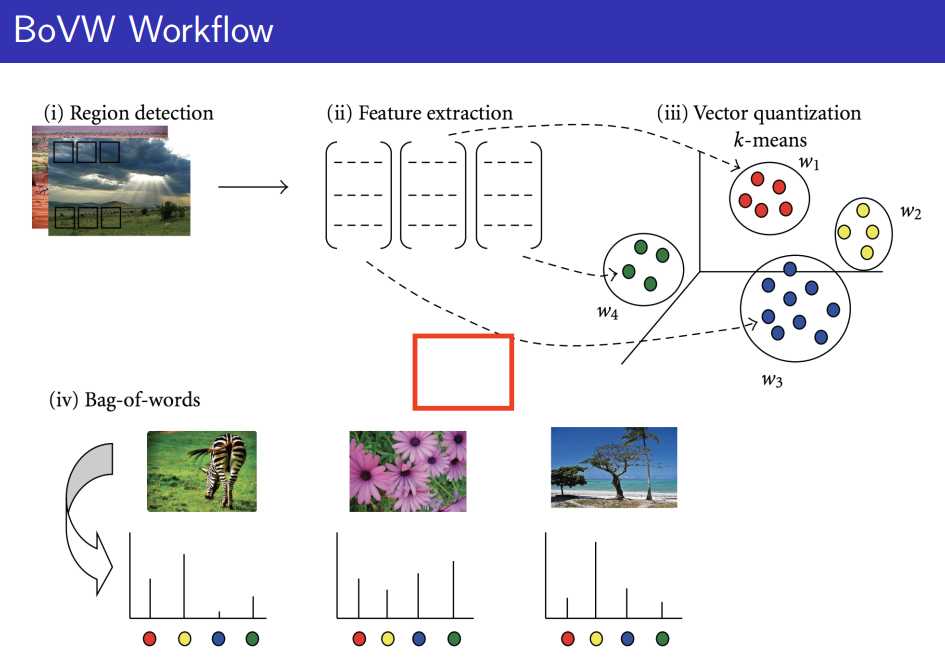
先回顾以下从2000年到2010年中计算机视觉中称霸这10年的代名词,就好像这几年深度学习这个词。它叫做BOW或者BOVW。叫视觉单词。那什么是视觉单词模型呢?

那先扔掉视觉不看,先看单词模型(词袋模型)。抛个问题:你怎么衡量两篇文章的相似度呢?你就看这两篇文章中出现的主要的特征单词,并且统计这些单词的频率。那举个例子来说,如下图:
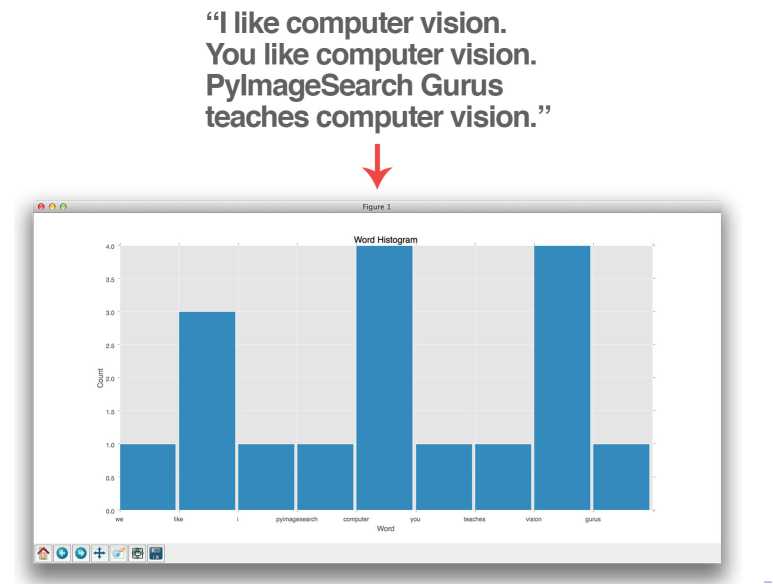
所以把上图中每个单词的出现频率统计出来,弄成直方图的形式,那这个直方图就是特征向量。这个就是词袋模型。
那再计算机视觉领域来说就是视觉词袋模型,又称视觉单词模型。刚才我们是对一个文档进行建模进行表征,但是在计算机视觉领域来说我们是对一张图片进行表征。那怎么建模,怎么表征它的情况呢?
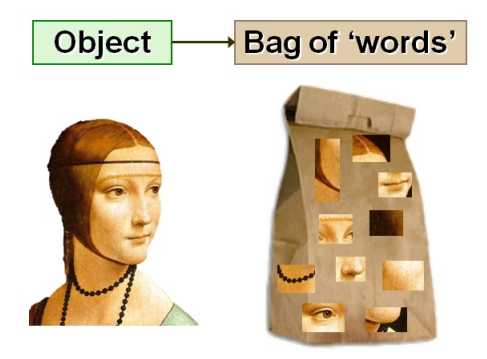
如上图中表征一个人,你是如何描述这个人的呢?她脸部比较修长,头发很有特色,还带着头箍,黑色的项链,鼻子比较细长,樱桃小嘴啥的。换句话说你是把这张图像分成了很多小的细节,用这些细节去表征这张图像。那现在就要用计算机的东西把刚才所描述的这些事给实现出来。那怎么实现呢?
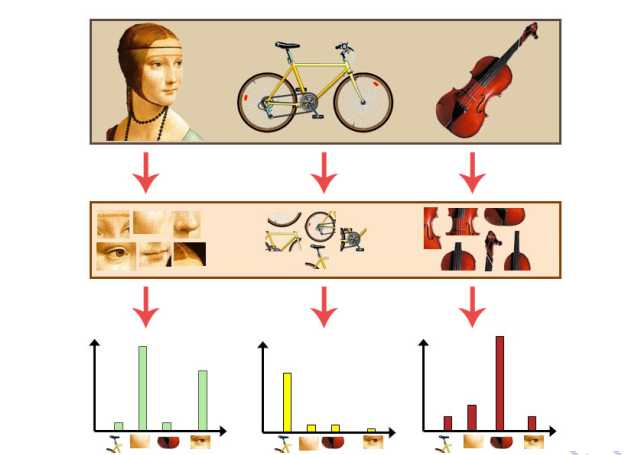
对上图中的每张图像进行一个直方图的统计,什么样的直方图的统计呢?你可能想的是对不同的part它的直方图的词频的统计。你应该是希望得到一种统一的,一种可对比的,可统计计数的一种度量标准。这个标准,比如说可以类似于新华字典,在新华字典里面大约有3000个字,那在计算机视觉里呢,就有3000多个视觉的词,那每一个词呢,可能代表一种概念,我们看第一张图片,来对他进行直方图词频统计的时候,哪些概念词频统计比较高呢?哦,鼻子的部分,眼睛的部分。那哪些部分比较低呢?哦,自行车的座椅,吉他的下半部分边缘。所以只有我人像对应的词频才会相对来说比较高。第二张图呢?以此类推吧,他应该是与自行车相关部件相对应的词频比较高,人像吉他所对应的部分比较低。第三张图同理。
以上就是词袋模型的思想,总结一下就是:我希望在计算机视觉这个表征空间里面,构建一种类似新华字典的视觉字典,并且我希望能够得到每一张图片他在这些视觉的新华字典上的词频的直方图的统计,那么一旦这个统计完成了,那么每张图像的视觉的表示其实就表示成了直方图的统计。那么图像与图像之间的距离就转化成了直方图意义上的距离。
那什么是视觉单词(Visual Word)的?visual word 本质上其实就是一个local feature的东西。视觉单词其实就是一个局部特征算子的东西,最基本的local feature其实是有非常非常多的,如sift等。但是它无外乎跑不出两个本质的东西,第一个就是local feature有两部分组成,第一部分组成就是个X,Y,也就是个坐标(位置信息)。也就是下图中的红色蓝色部分,也就是会出现在哪?第二部分就是这个local feature的描述符是什么,比方说下边这张图中,塔的最顶尖的部分是个local feature,那你如何告诉我这个塔的最顶尖部分与另外个塔的部分是相似的呢?
你总归有个描述符来描述它,这个描述符可能是一个128维的特征向量,也可能是个256维的特征向量,根据不同的local feature可能有不同维度的特征向量,但是没关系,只要有个特征向量,这两个部分的相似度或distance就是可以量化的。这样就可以衡量出两张图片有哪些区域是匹配上的。
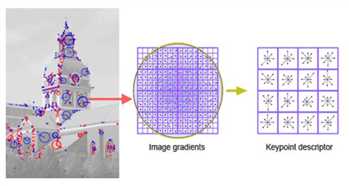
在计算机视觉里面最重要的local feature是SIFT(scale invarient feature transform),所以它逃不掉我们刚才所说的两个组成要素,一是检测器,检测位置的。二是描述符,用来描述它的特征向量的,如下图所示。换句话说,SIFT这个东西不是机器学习学出来的。而是科学家们根据数学统计或者梯度计算出来的。
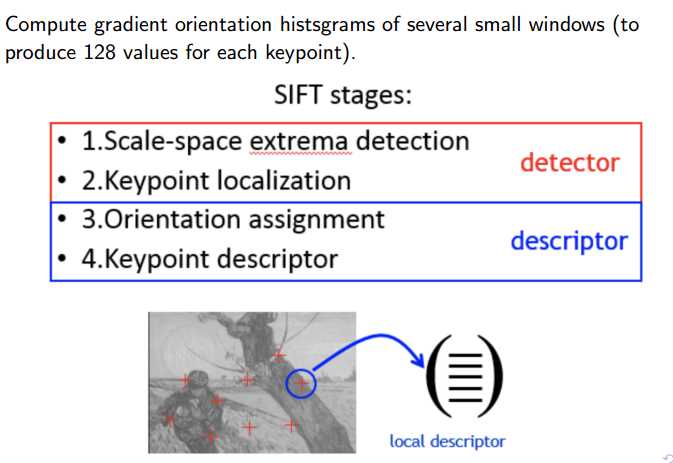
所以说opencv里面这个SIFT函数返回两种东西:一是local feature 的位置信息,x y的坐标,二是local feature 的特征描述符。比如说128维的向量,这是描述前边的坐标位置的算子。
那SIFT Matching这件事是怎么做的呢?如下图所示的两张图片,对其做Sift matching 。
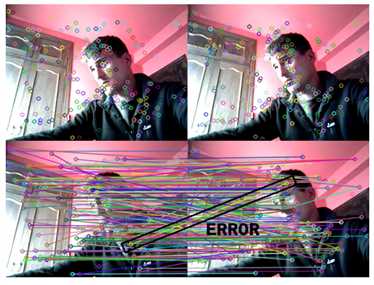
它的做法怎么弄?对于左边的每个local feature 而言,你去右边的图找最接近的那一个点,但是对于SIFT matching而言,它会去找最近的两个点,就是nearest number和second nearest number,什么意思呢?对于左边的一个点,你要去找右图中离他最近的两个点,然后把离这两个点的距离做比值,如果这个比值大于一定的阈值,他来决定你这个点是不是能和右图做match。这样做的好处在于降低一些误匹配。opencv里面这个函数里面可以修改阈值的参数。
看上图中有个匹配错误的地方,人的衣服匹配到了人的脑门上,那怎么修改这种错误呢?你看大部分匹配的都是正确的,且匹配的点大部分都是平行的,都是水平连线过去的,只有黑色的匹配错误的那个地方是错误的,是不符合大部分方向的。这里有种方法叫做几何校验,这种基于几何校验的方式叫做随即一致性采样。
那总结一下视觉单词的构建方法:
(1)feature extraction
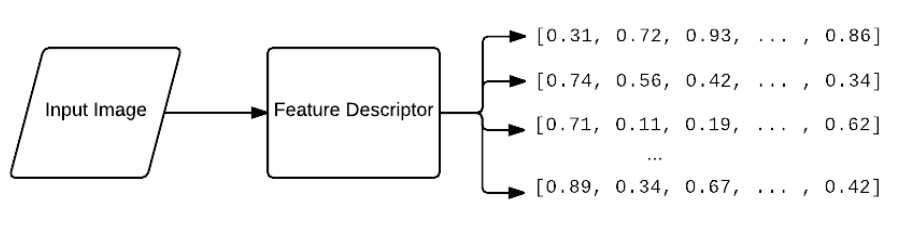
(2) codebook construction
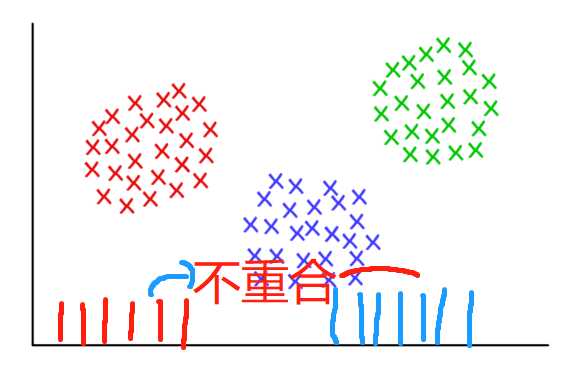
假设你的data base 里面有一万张图片,且每一张图片你能够提取出1000个特征点,那么你拥有的特征点的个数是多少?那就是10000 * 1000个特征点。但是你想想看,你能不能把这一千万个特征点当作你的codebook 内容?首先你会觉得太多,二是这一千万个特征点的描述肯定不相同,因为每个特征点有128维,肯定有区别的地方,虽然大部分地方是相同的,没有那么巧合。如果你把这一千万个特征点当作你的codebook 内容,你把每张图片进行直方图的统计,完蛋,恰好每张图片直方图统计出来的那个词频他没有重合的区域,因为这一千万个每个特征点都是独一无二的,你把每一张图片去投影到1000万的这样的量级上,这个直方图的横坐标是一千万,每张图呢,有一千个点,那每个点都是独一无二的,那么每个点你投影下来,都自己加1,那图像二的点是从另外一个区域进行加1,所以你如何去衡量这两张图像呢?都没有重合的区域就是0啊,那你没有两张图片是能够重合的。
那如何让他们重合呢,我们就构建一个类似于新华字典的个数,3000个,或者5000。然后你希望把每一个图像的这个local feature 投影到这上面,来做比对,这样就有公共的部分了。那如何把1000万变为5000呢?那就用聚类的方法做降维,1000万我可以把它聚成5000类,每一个类都有一个中心点,那每一个类的中心点呢,就是我的codebook, 这个时候你既能够表征那1000万个特征点,而又不至于维度那么高,而且还有公共的区域。
(3)vector quantization
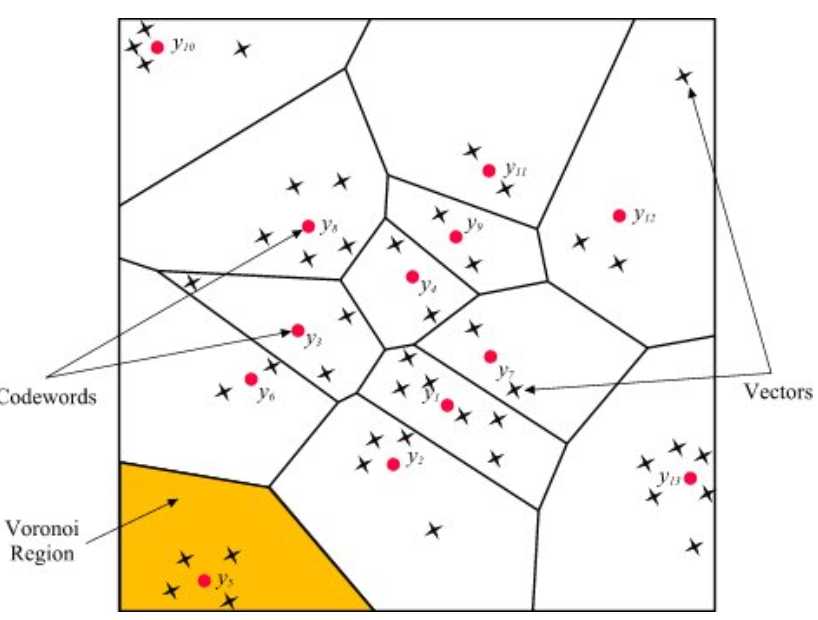
上图中每个黑颜色的xx代表local feature或者key point。红颜色的点是聚类出来的central point,即codewords。对于黄颜色的区域,4个key point 可用y5这个点进行表达。这就是第三步做的工作,其实就是你输入进来的图片的特征点比方说那四个点可用Y5来进行表达,Y5进行自加1,最终统计出来为4。这样来进行直方图的计算啦。
总结:
以上是关于图像搜索技术之visual words的主要内容,如果未能解决你的问题,请参考以下文章