数据分析面试准备(待更)
Posted yuanninesuns
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析面试准备(待更)相关的知识,希望对你有一定的参考价值。
目录:
一.python如何安装第三方包
二.Numpy的语法
三.Pandas的语法
四.Matplotlib的语法
五.Sklearn的语法
六.大数据组件的知识
七.Linux的基本命令
八.Excel
九.SQL
十.统计概率
十一.机器学习
十二.python中函数的参数
一.python如何安装第三方包
import numpy as np
1.pycharm中以点击的方式安装
2.Anaconda环境下,先conda create创建虚拟环境,再activate激活虚拟环境,为了更安全。在其中pip install。在此过程中可以配置清华镜像,使下载速度加快
3.如果第二种方式失败,可能由于网络或者包的问题,就上网将包下载到本地,然后pip install 【路径/文件】即可
二.Numpy的语法
参考https://www.jianshu.com/p/a260a8c43e44
1 代码示例: 2 >>> import numpy as np 3 >>> a = np.arange(15).reshape(3,5) 4 >>> a 5 array([[ 0, 1, 2, 3, 4], 6 [ 5, 6, 7, 8, 9], 7 [10, 11, 12, 13, 14]]) 8 >>> a.shape 9 (3, 5) 10 >>> a.ndim 11 2 12 >>> a.dtype.name 13 ‘int64‘ 14 >>> a.dtype 15 dtype(‘int64‘) 16 >>> a.size 17 15 18 >>> a.itemsize#表示数组中每个元素的字节大小。 19 8 20 >>> type(a) 21 <class ‘numpy.ndarray‘> 22 >>> 23 >>> b = np.array([1,2,3,4,5,6,7,8,9]) 24 >>> b 25 array([1, 2, 3, 4, 5, 6, 7, 8, 9]) 26 >>> c = np.array([1,2,3,4,5,6,‘7‘,‘a‘,‘b‘]) 27 >>> c 28 array([‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘, ‘6‘, ‘7‘, ‘a‘, ‘b‘], dtype=‘<U21‘) 29 >>> type(b) 30 <class ‘numpy.ndarray‘> 31 >>> type(c) 32 <class ‘numpy.ndarray‘> 33 >>> c.dtype#ndarray.dtype用来描述数组中元素的类型,ndarray中的所有元素都必须是同一种类型,如果在构造数组时,
传入的参数不是同一类型的,不同的类型将进行统一转化。除了标准的Python类型外,
NumPy额外提供了一些自有的类型,如numpy.int32、numpy.int16以及numpy.float64等
34 dtype(‘<U21‘) 35 >>> b.dtype 36 dtype(‘int64‘) 37 >>> c.itemsize 38 84 39 >>> b.itemsize 40 8
1 #NumPy中创建数组的方式有若干种。最简单的,可以直接利用Python中常规的list和tuple进行创建。 2 >>> import numpy as np 3 >>> a = np.array([1,2,3,4,5,6]) 4 >>> b = np.array((1,2,3,4,5,6)) 5 >>> a 6 array([1, 2, 3, 4, 5, 6]) 7 >>> b 8 array([1, 2, 3, 4, 5, 6])
1 >>> import numpy as np 2 >>> a = np.array([[1,2,3],[2,3,4]]) 3 >>> a 4 array([[1, 2, 3], 5 [2, 3, 4]]) 6 >>> b = np.array([[1,2,3],[2,3,4],[3,4,5]]) 7 >>> b 8 array([[1, 2, 3], 9 [2, 3, 4], 10 [3, 4, 5]])
1 #创建数组的时候,可以明确的规定数组的类型。 2 >>> c = np.array([1,2,3], dtype = complex) 3 >>> c 4 array([1.+0.j, 2.+0.j, 3.+0.j]) 5 >>> d = np.array([[1,2,3],[4,5,6]], dtype = ‘<U1‘) 6 >>> d 7 array([[‘1‘, ‘2‘, ‘3‘], 8 [‘4‘, ‘5‘, ‘6‘]], dtype=‘<U1‘)
1 >>> import numpy as np 2 >>> a = np.zeros((3,4)) 3 >>> a 4 array([[0., 0., 0., 0.], 5 [0., 0., 0., 0.], 6 [0., 0., 0., 0.]]) 7 >>> b = np.zeros((2,2,2)) 8 >>> b 9 array([[[0., 0.], 10 [0., 0.]], 11 12 [[0., 0.], 13 [0., 0.]]]) 14 >>> c = np.ones((3,3)) 15 >>> c 16 array([[1., 1., 1.], 17 [1., 1., 1.], 18 [1., 1., 1.]]) 19 >>> d = np.ones((3,3), dtype = np.int16) 20 >>> d 21 array([[1, 1, 1], 22 [1, 1, 1], 23 [1, 1, 1]], dtype=int16) 24 >>> e = np.arange(15) 25 >>> e 26 array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]) 27 >>> f = np.arange(15).reshape(3,5) 28 >>> f 29 array([[ 0, 1, 2, 3, 4], 30 [ 5, 6, 7, 8, 9], 31 [10, 11, 12, 13, 14]]) 32 >>> g = np.arange(0,15,3) 33 >>> g 34 array([ 0, 3, 6, 9, 12]) 35 >>> h = np.arange(0,3,0.3) 36 >>> h 37 array([0. , 0.3, 0.6, 0.9, 1.2, 1.5, 1.8, 2.1, 2.4, 2.7]) 38 39 >>> from numpy import pi 40 >>> np.linspace( 0, 2, 9 ) # 9 numbers from 0 to 2 41 array([ 0. , 0.25, 0.5 , 0.75, 1. , 1.25, 1.5 , 1.75, 2. ]) 42 >>> x = np.linspace( 0, 2*pi, 100 ) # useful to evaluate function at lots of points 43 >>> f = np.sin(x)
1 >>> import numpy as np 2 >>> a = np.array([10,20,30,40]) 3 >>> b = np.arange(4) 4 >>> a 5 array([10, 20, 30, 40]) 6 >>> b 7 array([0, 1, 2, 3]) 8 >>> c = a - b 9 >>> c 10 array([10, 19, 28, 37]) 11 >>> a 12 array([10, 20, 30, 40]) 13 >>> b 14 array([0, 1, 2, 3]) 15 >>> b**2 16 array([0, 1, 4, 9]) 17 >>> b 18 array([0, 1, 2, 3]) 19 >>> a<35 20 array([ True, True, True, False]) 21 >>> a 22 array([10, 20, 30, 40])
1 #在NumPy中,*用于数组间元素对应的乘法,而不是矩阵乘法,矩阵乘法可以用dot()方法来实现。 2 >>> A = np.array([[1,2],[3,4]]) 3 >>> B = np.array([[0,1],[0,1]]) 4 >>> A 5 array([[1, 2], 6 [3, 4]]) 7 >>> B 8 array([[0, 1], 9 [0, 1]]) 10 >>> A*B # elementwise product 11 array([[0, 2], 12 [0, 4]]) 13 >>> A.dot(B) # matrix product 14 array([[0, 3], 15 [0, 7]]) 16 >>> np.dot(A,B) # another matrix product 17 array([[0, 3], 18 [0, 7]])
1 >>> a = np.random.random((2,3)) 2 >>> a 3 array([[0.62181697, 0.26165654, 0.34994938], 4 [0.95619296, 0.24614291, 0.42120462]]) 5 >>> a.sum() 6 2.8569633678947346 7 >>> a.min() 8 0.24614290611891454 9 >>> a.max() 10 0.9561929625193091
1 >>> b = np.arange(12).reshape(3,4) 2 >>> b 3 array([[ 0, 1, 2, 3], 4 [ 4, 5, 6, 7], 5 [ 8, 9, 10, 11]]) 6 >>> b.sum(axis = 0) # sum of each column 7 array([12, 15, 18, 21]) 8 >>> b.sum(axis = 1) # sum of each row 9 array([ 6, 22, 38]) 10 >>> b.min(axis = 0) # min of each column 11 array([0, 1, 2, 3]) 12 >>> b.min(axis = 1) # min of each row 13 array([0, 4, 8]) 14 >>> b.max(axis = 0) # max of each column 15 array([ 8, 9, 10, 11]) 16 >>> b.max(axis = 1) # max of each row 17 array([ 3, 7, 11]) 18 >>> b.cumsum(axis = 1) # cumulative sum along each row 19 array([[ 0, 1, 3, 6], 20 [ 4, 9, 15, 22], 21 [ 8, 17, 27, 38]]) 22 >>> b.cumsum(axis = 0) # cumulative sum along each column 23 array([[ 0, 1, 2, 3], 24 [ 4, 6, 8, 10], 25 [12, 15, 18, 21]])
1 >>> a = np.arange(10)**3 2 >>> a 3 array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729]) 4 >>> a[3] 5 27 6 >>> a[2:5] 7 array([ 8, 27, 64]) 8 >>> a[:6:2] = -1111 9 >>> a 10 array([-1111, 1, -1111, 27, -1111, 125, 216, 343, 512, 11 729]) 12 >>> a[::-1]#倒序 13 array([ 729, 512, 343, 216, 125, -1111, 27, -1111, 1, 14 -1111])
1 >>>b = np.arange(15).reshape(3,5) 2 >>>for element in b.flat:#flat属性是array中的每个元素的迭代器。 3 >>> print(element) 4 0 5 1 6 2 7 3 8 4 9 5 10 6 11 7 12 8 13 9 14 10 15 11 16 12 17 13 18 14
1 >>> import numpy as np 2 >>> a = np.ones((3,4), dtype = int) 3 >>> a 4 array([[1, 1, 1, 1], 5 [1, 1, 1, 1], 6 [1, 1, 1, 1]]) 7 >>> a.ravel() 8 array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]) 9 >>> a 10 array([[1, 1, 1, 1], 11 [1, 1, 1, 1], 12 [1, 1, 1, 1]]) 13 >>> b = a.ravel() 14 >>> b 15 array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]) 16 >>> a 17 array([[1, 1, 1, 1], 18 [1, 1, 1, 1], 19 [1, 1, 1, 1]]) 20 >>> c = a.reshape(2,-1)#除此之外,NumPy还提供了可以直接修改原始数组shape的方法——resize()。resize()方法和reshape()方法的最主要区别在于,reshape()方法返回一个特定shape的数组,而resize()方法会直接更改原数组。 21 >>> c 22 array([[1, 1, 1, 1, 1, 1], 23 [1, 1, 1, 1, 1, 1]]) 24 >>> a 25 array([[1, 1, 1, 1], 26 [1, 1, 1, 1], 27 [1, 1, 1, 1]]) 28 >>> a.T 29 array([[1, 1, 1], 30 [1, 1, 1], 31 [1, 1, 1], 32 [1, 1, 1]]) 33 >>> a 34 array([[1, 1, 1, 1], 35 [1, 1, 1, 1], 36 [1, 1, 1, 1]]) 37 >>> d = a.T 38 >>> d 39 array([[1, 1, 1], 40 [1, 1, 1], 41 [1, 1, 1], 42 [1, 1, 1]]) 43 >>> a.shape 44 (3, 4) 45 >>> b.shape 46 (12,) 47 >>> c.shape 48 (2, 6) 49 >>> d.shape 50 (4, 3)
1 #hstack()实现数组横向堆叠,vstack()实现数组纵向堆叠。 2 >>> a = np.floor(10*np.random.random((2,2))) 3 >>> a 4 array([[0., 8.], 5 [4., 8.]]) 6 >>> b = np.floor(10*np.random.random((2,2))) 7 >>> b 8 array([[1., 4.], 9 [4., 1.]]) 10 >>> np.vstack((a,b)) 11 array([[0., 8.], 12 [4., 8.], 13 [1., 4.], 14 [4., 1.]]) 15 >>> np.hstack((a,b)) 16 array([[0., 8., 1., 4.], 17 [4., 8., 4., 1.]])
1 >>> a = np.arange(12).reshape(3,4) 2 >>> a 3 array([[ 0, 1, 2, 3], 4 [ 4, 5, 6, 7], 5 [ 8, 9, 10, 11]]) 6 >>> np.split(a,3) 7 [array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])] 8 >>> np.h 9 np.half( np.hanning( np.histogram( np.histogramdd( np.hstack( 10 np.hamming( np.heaviside( np.histogram2d( np.hsplit( np.hypot( 11 >>> np.hsplit(a,4) 12 [array([[0], 13 [4], 14 [8]]), array([[1], 15 [5], 16 [9]]), array([[ 2], 17 [ 6], 18 [10]]), array([[ 3], 19 [ 7], 20 [11]])] 21 >>> np.vsplit(a,3) 22 [array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])]
- NumPy中,数组的复制有三种方式:
- Python通用的地址复制:通过 b = a 复制 a 的值,b 与 a 指向同一地址,改变 b 同时也改变 a。d=a
- 通过视图
ndarray.view()仅复制值,当对 c 值进行改变会改变 a 的对应的值,而改变 c 的 shape 不改变 a 的 shape。d = a.view() ndarray.copy()进行的完整的拷贝,产生一份完全相同的独立的复制。d = a.copy()
三.Pandas的语法
1 # 一般以pd作为pandas的缩写 2 import pandas as pd 3 4 # 读取文件 5 df = pd.read_csv(‘file.csv‘) 6 7 # 返回数据的大小 8 df.shape 9 10 # 显示数据的一些对象信息和内存使用 11 df.info() 12 13 # 显示数据的统计量信息 14 df.describe()
1 data = {‘animal‘: [‘cat‘, ‘cat‘, ‘snake‘, ‘dog‘, ‘dog‘, ‘cat‘, ‘snake‘, ‘cat‘, ‘dog‘, ‘dog‘], 2 ‘age‘: [2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3], 3 ‘visits‘: [1, 3, 2, 3, 2, 3, 1, 1, 2, 1], 4 ‘priority‘: [‘yes‘, ‘yes‘, ‘no‘, ‘yes‘, ‘no‘, ‘no‘, ‘no‘, ‘yes‘, ‘no‘, ‘no‘]} 5 6 labels = [‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘, ‘f‘, ‘g‘, ‘h‘, ‘i‘, ‘j‘] 7 8 df = pd.DataFrame(data, index=labels) 9 df[[‘age‘, ‘animal‘]] 10 df[[0,1]] 11 #以上两种表达方式等价 12 13 #位置索引 14 df.iloc[0:2, 0:2] 15 #loc与iloc的主要区别就是索引要用标签不能用序号 16 df.loc[[‘a‘, ‘b‘], [‘animal‘, ‘age‘]] 17 #ix可以用位置索引和标签索引的混合使用方式 18 df.ix[0:2, [‘animal‘, ‘age‘]] 19 #条件索引 20 df[(df[‘animal‘] == ‘cat‘) & (df[‘age‘] < 3)] 21 #找到缺失值 22 df[df[‘age‘].isnull()] 23 #填充缺失值 24 df[‘age‘].fillna(0, inplace=True) 25 #将字符值替换成布尔值 26 df[‘priority‘] = df[‘priority‘].map({‘yes‘: True, ‘no‘: False})
from pandas import Series,DataFrame #数据结构:Series和DataFrame。Series是一种类似于以为NumPy数组的对象,它由一组数据(各种NumPy数据类型)和与之相关的一组数据标签(即索引)组成的。可以用index和values分别规定索引和值。如果不规定索引,会自动创建 0 到 N-1 索引。 #Series可以设置index,有点像字典,用index索引 obj = Series([1,2,3],index=[‘a‘,‘b‘,‘c‘]) #print obj[‘a‘] #也就是说,可以用字典直接创建Series dic = dict(key = [‘a‘,‘b‘,‘c‘],value = [1,2,3]) dic = Series(dic) #下面注意可以利用一个字符串更新键值 key1 = [‘a‘,‘w‘,‘e‘] #注意下面的语句可以将 Series 对象中的值提取出来,不过要知道的字典是不能这么做提取的 dic1 = Series(obj,index = key1) obj = Series([1,2,3,4],index=[‘a‘,‘b‘,‘c‘,‘d‘]) frame = DataFrame(np.arange(9).reshape((3,3)),index = [‘a‘,‘c‘,‘d‘],columns = [‘Ohio‘,‘Texas‘,‘California‘]) #Series切片和索引 #print obj[obj < 2] #注意:利用标签的切片与python的切片不同,两端都是包含的(有道理) print obj[‘b‘:‘c‘] #对于DataFrame,列可以直接用名称 print frame[‘Ohio‘] #特殊情况:通过切片和bool型索引,得到的是行(有道理) print frame[:2] print frame[frame[‘Ohio‘] != 0] #下面的方式是对frame所有元素都适用,不是行或者列,下面的得到的是numpy.ndarray类型的数据 print frame[frame < 5],type(frame[frame < 5]) frame[frame < 5] = 0 print frame #对于DataFrame上的标签索引,用ix进行 print frame.ix[[‘a‘,‘d‘],[‘Ohio‘,‘Texas‘]] print frame.ix[2] #注意这里默认取行 #注意下面默认取行 print frame.ix[frame.Ohio > 0] #注意下面的逗号后面是列标 print frame.ix[frame.Ohio > 0,:2]
1 df.agg({‘ext price‘: [‘sum‘, ‘mean‘], 2 ‘quantity‘: [‘sum‘, ‘mean‘], 3 ‘unit price‘: [‘mean‘], 4 ‘sku‘: [get_max]})
1 import pandas as pd 2 df1 = pd.DataFrame([[1,2,3],[5,6,7],[3,9,0],[8,0,3]],columns=[‘x1‘,‘x2‘,‘x3‘]) 3 df2 = pd.DataFrame([[1,2],[4,6],[3,9]],columns=[‘x1‘,‘x4‘]) 4 print (df1) 5 print (df2) 6 df3 = pd.merge(df1,df2,how = ‘left‘,on=‘x1‘) 7 print (df3) 8 df4 = pd.merge(df1,df2,how = ‘right‘,on=‘x1‘) 9 print (df4) 10 df5 = pd.merge(df1,df2,how = ‘inner‘,on=‘x1‘) 11 print (df5) 12 df6 = pd.merge(df1,df2,how = ‘outer‘,on=‘x1‘) 13 print (df6)
四.Matplotlib的语法
参考:https://blog.csdn.net/Notzuonotdied/article/details/77876080
1 import matplotlib.pyplot as plt 2 import numpy as np 3 4 # 从[-1,1]中等距去50个数作为x的取值 5 x = np.linspace(-10, 10, 5000) 6 #print(x) 7 y = sin(x) 8 # 第一个是横坐标的值,第二个是纵坐标的值 9 plt.plot(x, y) 10 # 必要方法,用于将设置好的figure对象显示出来
1 import matplotlib.pyplot as plt 2 import numpy as np 3 4 # 多个figure 5 x = np.linspace(-1, 1, 50) 6 y1 = 2*x + 1 7 y2 = 2**x + 1 8 9 # 使用figure()函数重新申请一个figure对象 10 # 注意,每次调用figure的时候都会重新申请一个figure对象 11 plt.figure() 12 # 第一个是横坐标的值,第二个是纵坐标的值 13 plt.plot(x, y1) 14 15 # 第一个参数表示的是编号,第二个表示的是图表的长宽 16 plt.figure(num = 3, figsize=(8, 5)) 17 # 当我们需要在画板中绘制两条线的时候,可以使用下面的方法: 18 plt.plot(x, y2) 19 plt.plot(x, y1, 20 color=‘red‘, # 线颜色 21 linewidth=1.0, # 线宽 22 linestyle=‘--‘ # 线样式 23 )
1 # 设置轴线的lable(标签) 2 plt.xlabel("I am x") 3 plt.ylabel("I am y") 4 5 plt.xticks(())#隐藏横纵坐标 6 plt.yticks(())# 7 8 plt.scatter()#散点图 9 plt.bar()#条形图 10 plt.contourf()#等高线图 11 plt.imshow()#显示图片
五.Sklearn的语法
1 model.fit(X_train,Y_train)#训练 2 model.predict(X_test)#测试
六.大数据组件的知识
七.Linux的基本命令
八.Excel
九.SQL
十.统计概率
描述性统计(平均值,标准差,中位数)
excel中stdev.s是计算标准差的函数,假设有一组数值X1,X2,X3,......XN(皆为实数),其平均值(算术平均值)为μ
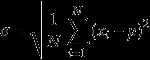
概率(独立事件,相关事件,期望,包括贝叶斯)
在一次实验中,一个事件的发生不会影响到另一个事件发生的概率。如,骰子掷出“6点”的事件和骰子掷出“1点”的事件是相互独立的。类似地,两个随机变量是独立的,若其在一事件给定观测量的条件概率分布和另一事件没有被观测的概率分布是一样的。大数定律规定,随着重复次数接近无穷大,数值的算术平均值几乎肯定地收敛于期望值。
贝叶斯公式:
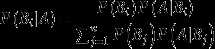
概率分布(离散概率分布,连续概率分布)
统计推断(抽样,置信区间,假设检验)
置信区间:置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度,其给出的是被测量参数的测量值的可信程度,即前面所要求的“一个概率”。

十一.机器学习
十二.python中函数的参数
必选参数、默认参数、可变参数、命名关键字参数和关键字参数
必选参数:
1 def power(x, n): 2 s = 1 3 while n > 0: 4 n = n - 1 5 s = s * x 6 return s
调用时如果传入的参数少了一个就会报错,所以x和n都是必选参数。
默认参数:
1 def power(x, n=2): 2 s = 1 3 while n > 0: 4 n = n - 1 5 s = s * x 6 return s 7 8 >>> power(5) 9 25 10 >>> power(5, 2) 11 25
可变参数
由于参数个数不确定,我们首先想到可以把a,b,c……作为一个list或tuple传进来,这样,函数可以定义如下:
1 def calc(numbers): 2 sum = 0 3 for n in numbers: 4 sum = sum + n * n 5 return sum 6 7 #但是调用的时候,需要先组装出一个list或tuple: 8 >>> calc([1, 2, 3]) 9 14 10 >>> calc((1, 3, 5, 7)) 11 84
定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。在函数内部,参数numbers接收到的是一个tuple,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括0个参数:
1 def calc(*numbers): 2 sum = 0 3 for n in numbers: 4 sum = sum + n * n 5 return sum 6 7 >>> calc(1, 2) 8 5 9 >>> calc() 10 0 11 >>> calc(1, 2, 3) 12 14 13 >>> calc(1, 3, 5, 7) 14 84
Python允许你在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去:
>>> nums = [1, 2, 3] >>> calc(*nums) 14 #*nums表示把nums这个list的所有元素作为可变参数传进去。这种写法相当有用,而且很常见。
命名关键字参数
如果要限制关键字参数的名字,就可以用命名关键字参数,例如,只接收city和job作为关键字参数。这种方式定义的函数如下:
1 def person(name, age, *, city, job): 2 print(name, age, city, job)
和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
1 >>> person(‘Jack‘, 24, city=‘Beijing‘, job=‘Engineer‘) 2 Jack 24 Beijing Engineer 3 4 #如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了: 5 def person(name, age, *args, city, job): 6 print(name, age, args, city, job) 7 8 #命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名,调用将报错 9 >>> person(‘Jack‘, 24, ‘Beijing‘, ‘Engineer‘) 10 Traceback (most recent call last): 11 File "<stdin>", line 1, in <module> 12 TypeError: person() takes 2 positional arguments but 4 were given 13 #由于调用时缺少参数名city和job,Python解释器把这4个参数均视为位置参数,但person()函数仅接受2个位置参数。 14 15 #命名关键字参数可以有缺省值,从而简化调用 16 #使用命名关键字参数时,要特别注意,如果没有可变参数,就必须加一个*作为特殊分隔符。如果缺少*,Python解释器将无法识别位置参数和命名关键字参数 17 18 #在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
关键字参数
关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
1 def person(name, age, **kw): 2 print(‘name:‘, name, ‘age:‘, age, ‘other:‘, kw) 3 4 >>> person(‘Bob‘, 35, city=‘Beijing‘) 5 name: Bob age: 35 other: {‘city‘: ‘Beijing‘} 6 >>> person(‘Adam‘, 45, gender=‘M‘, job=‘Engineer‘) 7 name: Adam age: 45 other: {‘gender‘: ‘M‘, ‘job‘: ‘Engineer‘} 8 9 >>> extra = {‘city‘: ‘Beijing‘, ‘job‘: ‘Engineer‘} 10 >>> person(‘Jack‘, 24, city=extra[‘city‘], job=extra[‘job‘]) 11 name: Jack age: 24 other: {‘city‘: ‘Beijing‘, ‘job‘: ‘Engineer‘} 12 13 >>> extra = {‘city‘: ‘Beijing‘, ‘job‘: ‘Engineer‘} 14 >>> person(‘Jack‘, 24, **extra) 15 name: Jack age: 24 other: {‘city‘: ‘Beijing‘, ‘job‘: ‘Engineer‘}
python连接数据库
1 import pymysql 2 import pandas as pd 3 import numpy as np 4 from get_a import * 5 from connect import * 6 7 #连接数据库,将数据导入dataframe 8 db = pymysql.connect("localhost", "root", "yuanxu135689", "mytrip") 9 cursor = db.cursor() 10 sql ="SELECT record_time,max(vehicle_speed),engine_rpm FROM TB_IOV_DEVICE_OBD_41030402427 where device_id=‘%s‘ GROUP BY record_time" % (41030402427) 11 dbdata = read_table(cursor, sql) 12 db.close() 13 dbdata.columns = [‘time‘, ‘speed‘, ‘rpm‘]
以上是关于数据分析面试准备(待更)的主要内容,如果未能解决你的问题,请参考以下文章