Scrapy突破反爬虫的限制
Posted linyujin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy突破反爬虫的限制相关的知识,希望对你有一定的参考价值。
7-1 爬虫和反爬的对抗过程以及策略
基本概念
爬虫:自动获取网站数据的程序,关键是批量的获取
反爬虫:使用技术手段防止爬虫程序的方法
误伤:反爬技术将普通用户识别为爬虫,如果误伤过高,效果再好也不能用
一般ip地址禁止是不太可能被使用的
成本:反爬虫需要的人力和机器成本
拦截:成功拦截爬虫,一般拦截率越高,误伤率越高
初级爬虫:简单粗暴,不管服务器压力,容易弄挂网站
数据保护:
失控的爬虫:由于某些情况下,忘记或者无法关闭的爬虫
商业竞争对手
爬虫和反爬虫对抗过程
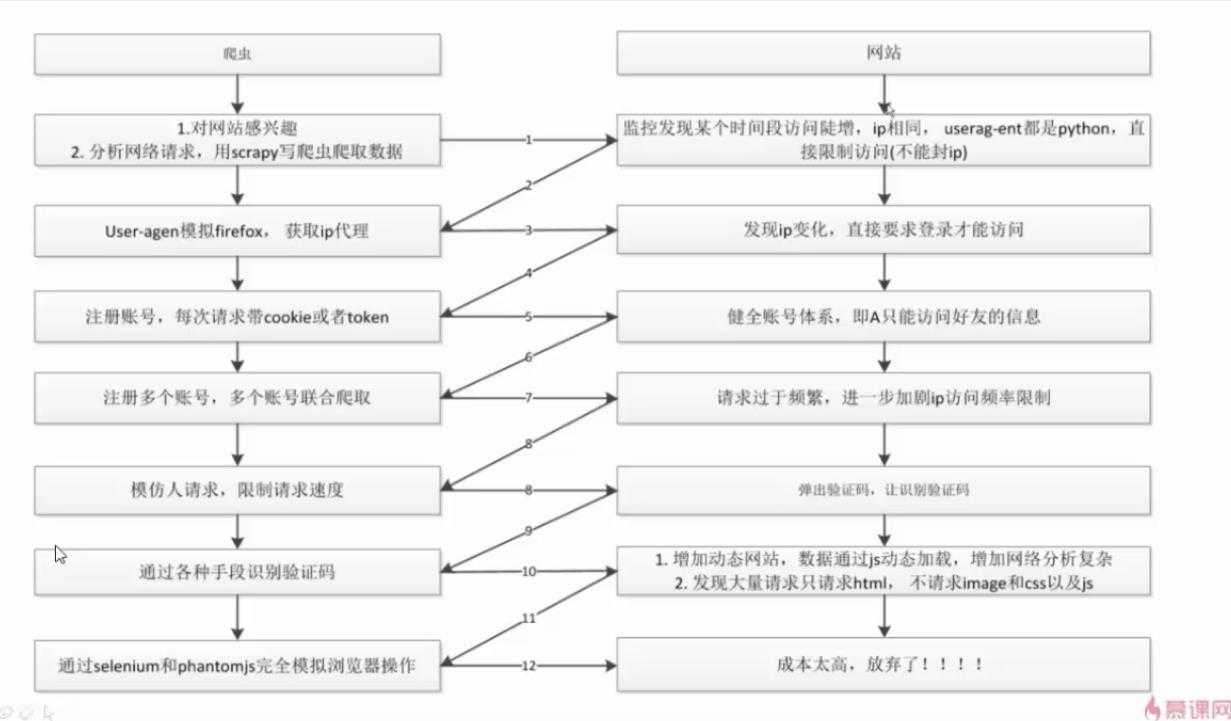
挺有趣的过程
7-2 scrapy架构源码分析
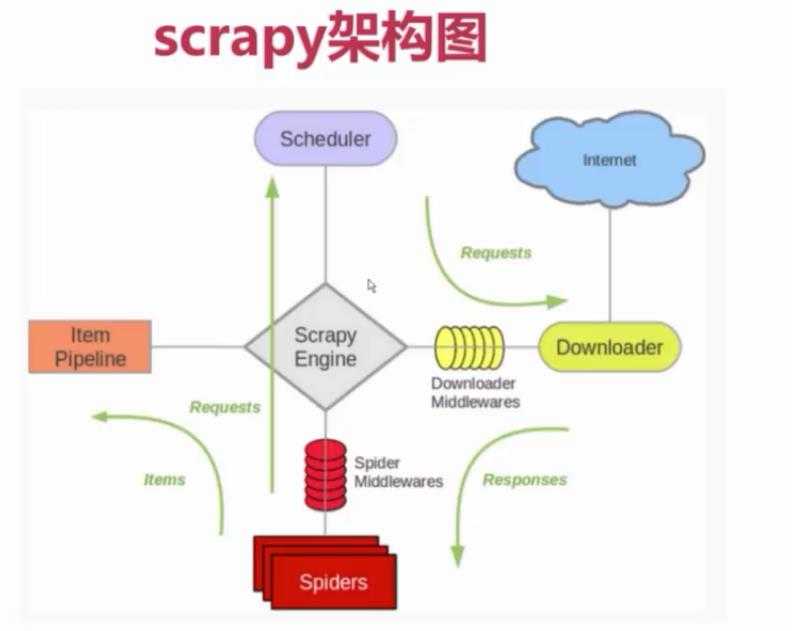
Scrapy Engine: 这是引擎,负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等!(像不像人的身体?)
Scheduler(调度器): 它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spiders来处理,
Spiders:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline:它负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的)
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses;和从Spiders出去的Requests)
数据在整个Scrapy的流向:
程序运行的时候,
引擎:Hi!Spider, 你要处理哪一个网站?
Spiders:我要处理23wx.com
引擎:你把第一个需要的处理的URL给我吧。
Spiders:给你第一个URL是XXXXXXX.com
引擎:Hi!调度器,我这有request你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request给我,
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照下载中间件的设置帮我下载一下这个request
下载器:好的!给你,这是下载好的东西。(如果失败:不好意思,这个request下载失败,然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载。)
引擎:Hi!Spiders,这是下载好的东西,并且已经按照Spider中间件处理过了,你处理一下(注意!这儿responses默认是交给def parse这个函数处理的)
Spiders:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,这是我需要跟进的URL,将它的responses交给函数 def xxxx(self, responses)处理。还有这是我获取到的Item。
引擎:Hi !Item Pipeline 我这儿有个item你帮我处理一下!调度器!这是我需要的URL你帮我处理下。然后从第四步开始循环,直到获取到你需要的信息
链接:https://cuiqingcai.com/3472.html
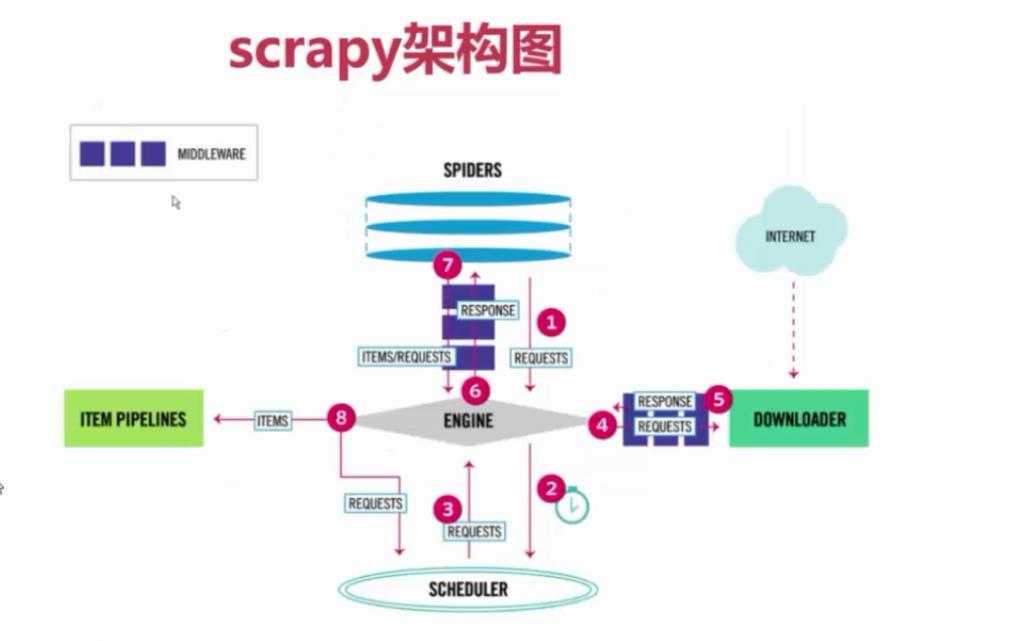
Scrapy中的数据流由执行引擎控制,如下所示:
- Engine获得从爬行器中爬行的初始请求。
- Engine在调度程序中调度请求,并请求下一次抓取请求。
- 调度程序将下一个请求返回到引擎。
- 引擎将请求发送到下载器,通过下载器中间件(请参阅process_request())。
- 页面下载完成后,下载器生成一个响应(带有该页面)并将其发送给引擎,通过下载器中间件(请参阅process_response())。
- 引擎从下载加载程序接收响应,并将其发送给Spider进行处理,并通过Spider中间件(请参阅process_spider_input())。
- Spider处理响应,并向引擎返回报废的项和新请求(要跟踪的),通过Spider中间件(请参阅process_spider_output())。
- 引擎将已处理的项目发送到项目管道,然后将已处理的请求发送到调度程序,并请求可能的下一个请求进行抓取。
- 这个过程重复(从第1步),直到调度程序不再发出请求。
链接:http://www.imooc.com/article/254496
7-3 Requests和Response介绍
可在官方文档查看参数和详细用法:https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/request-response.html
一个 request 对象代表一个HTTP请求,一般来讲, HTTP请求是由Spider产生并被Downloader处理进而生成一个 response
class scrapy.http.Request(url[, callback, method=‘GET‘, headers, body, cookies, meta, encoding=‘utf-8‘, priority=0, dont_filter=False, errback]
参数:
url(string) - 此请求的网址
callback(callable) - 将使用此请求的响应(一旦下载)作为其第一个参数调用的函数。有关更多信息,请参阅下面的将附加数据传递给回调函数。如果请求没有指定回调,parse()将使用spider的 方法。请注意,如果在处理期间引发异常,则会调用errback。
method(string) - 此请求的HTTP方法。默认为’GET’。
meta(dict) - 属性的初始值Request.meta。如果给定,在此参数中传递的dict将被浅复制。
body(str或unicode) - 请求体。如果unicode传递了a,那么它被编码为 str使用传递的编码(默认为utf-8)。如果 body没有给出,则存储一个空字符串。不管这个参数的类型,存储的最终值将是一个str(不会是unicode或None)。
headers(dict) - 这个请求的头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)。如果 None作为值传递,则不会发送HTTP头。
cookie(dict或list) - 请求cookie。这些可以以两种形式发送。
使用dict:
request_with_cookies = Request(url="http://www.example.com",
cookies={‘currency‘: ‘USD‘, ‘country‘: ‘UY‘})
使用列表:
request_with_cookies = Request(url="http://www.example.com",
cookies=[{‘name‘: ‘currency‘,
‘value‘: ‘USD‘,
‘domain‘: ‘example.com‘,
‘path‘: ‘/currency‘}])
后一种形式允许定制 cookie的属性domain和path属性。这只有在保存Cookie用于以后的请求时才有用。
当某些网站返回Cookie(在响应中)时,这些Cookie会存储在该域的Cookie中,并在将来的请求中再次发送。这是任何常规网络浏览器的典型行为。但是,如果由于某种原因,您想要避免与现有Cookie合并,您可以通过将dont_merge_cookies关键字设置为True 来指示Scrapy如此操作 Request.meta。
不合并Cookie的请求示例:
request_with_cookies = Request(url="http://www.example.com",
cookies={‘currency‘: ‘USD‘, ‘country‘: ‘UY‘},
meta={‘dont_merge_cookies‘: True})
encoding(string) - 此请求的编码(默认为’utf-8’)。此编码将用于对URL进行百分比编码,并将正文转换为str(如果给定unicode)。
priority(int) - 此请求的优先级(默认为0)。调度器使用优先级来定义用于处理请求的顺序。具有较高优先级值的请求将较早执行。允许负值以指示相对低优先级。
dont_filter(boolean) - 表示此请求不应由调度程序过滤。当您想要多次执行相同的请求时忽略重复过滤器时使用。小心使用它,或者你会进入爬行循环。默认为False。
errback(callable) - 如果在处理请求时引发任何异常,将调用的函数。这包括失败的404 HTTP错误等页面。它接收一个Twisted Failure实例作为第一个参数。有关更多信息,请参阅使用errbacks在请求处理中捕获异常。
class scrapy.http.Response(url[, status=200, headers=None, body=b‘‘, flags=None, request=None])
一个Response对象表示的HTTP响应,这通常是下载(由下载),并供给到爬虫进行处理。
参数:
url(string) - 此响应的URL
status(integer) - 响应的HTTP状态。默认为200。
headers(dict) - 这个响应的头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)。
body(str) - 响应体。它必须是str,而不是unicode,除非你使用一个编码感知响应子类,如 TextResponse。
flags(list) - 是一个包含属性初始值的 Response.flags列表。如果给定,列表将被浅复制。
request(Requestobject) - 属性的初始值Response.request。这代表Request生成此响应。
url
包含响应的URL的字符串。
此属性为只读。更改响应使用的URL replace()。
status
表示响应的HTTP状态的整数。示例:200, 404。
headers
包含响应标题的类字典对象。可以使用get()返回具有指定名称的第一个标头值或getlist()返回具有指定名称的所有标头值来访问值。例如,此调用会为您提供标题中的所有Cookie:
response.headers.getlist(‘Set-Cookie‘)
1
body
本回复的正文。记住Response.body总是一个字节对象。如果你想unicode版本使用 TextResponse.text(只在TextResponse 和子类中可用)。
此属性为只读。更改响应使用的主体 replace()。
request
Request生成此响应的对象。在响应和请求通过所有下载中间件后,此属性在Scrapy引擎中分配。特别地,这意味着:
HTTP重定向将导致将原始请求(重定向之前的URL)分配给重定向响应(重定向后具有最终URL)。
Response.request.url并不总是等于Response.url
此属性仅在爬虫程序代码和 Spider Middleware中可用,但不能在Downloader Middleware中使用(尽管您有通过其他方式可用的请求)和处理程序response_downloaded。
meta
的快捷方式Request.meta的属性 Response.request对象(即self.request.meta)。
与Response.request属性不同,Response.meta 属性沿重定向和重试传播,因此您将获得Request.meta从您的爬虫发送的原始属性。
7-4 通过downloadmiddleware随机更换user-agent
1 #middlewares.py文件 2 from fake_useragent import UserAgent #这是一个随机UserAgent的包,里面有很多UserAgent 3 class RandomUserAgentMiddleware(object): 4 def __init__(self, crawler): 5 super(RandomUserAgentMiddleware, self).__init__() 6 7 self.ua = UserAgent() 8 self.ua_type = crawler.settings.get(‘RANDOM_UA_TYPE‘, ‘random‘) #从setting文件中读取RANDOM_UA_TYPE值 9 10 @classmethod 11 def from_crawler(cls, crawler): 12 return cls(crawler) 13 14 def process_request(self, request, spider): 15 def get_ua(): 16 ‘‘‘Gets random UA based on the type setting (random, firefox…)‘‘‘ 17 return getattr(self.ua, self.ua_type) 18 19 # 用来进行测试的 user_agent_random=get_ua() 20 request.headers.setdefault(‘User-Agent‘, user_agent_random) #这样就是实现了User-Agent的随即变换
#settings.py文件 DOWNLOADER_MIDDLEWARES = { ‘ArticleSpider.middlewares.RandomUserAgentMiddleware‘: 543, ‘scrapy.downloadermiddlewares.useragent.UserAgentMiddleware‘:None#这里要设置原来的scrapy的useragent为None,否者会被覆盖掉 } RANDOM_UA_TYPE=‘random‘
7-5 scrapy实现ip代理池
百度输入:本机ip地址,就可以知道自己的ip地址
ip代理:会让我们的输入
代理服务器的设置:西刺免费代理ip(不稳定)
设置ip代理池(要多个代理ip,这样才不怕被封)
先设置一个表 保存数据
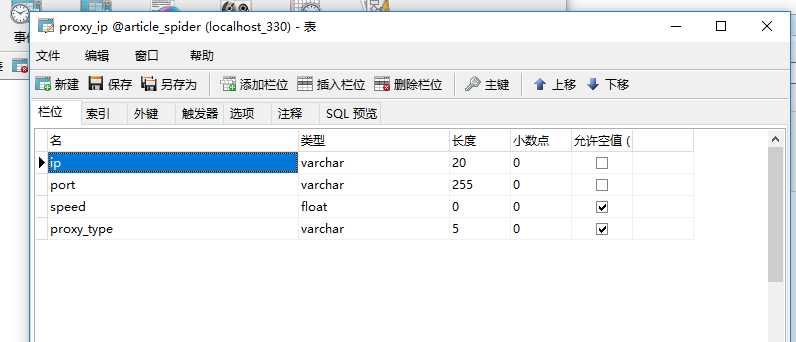
在ArticleSpider下新建一个python package tools ,
然后在里面新建一个crawl_xici_ip.py ,这样子我们就可以选取到可用的代理ip和端口
# -*- coding: utf-8 -*- __author__ = ‘bobby‘ import requests from scrapy.selector import Selector import mysqldb conn = MySQLdb.connect( host = "127.0.0.1", port = 3306, user = "root", passwd = "123456", db = "article_spider", charset = "utf8" ) cursor = conn.cursor() def craw_ips(): #获取西刺的免费ip代理 headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36" } for i in range(1568): re = requests.get("https://www.xicidaili.com/nn/{0}".format(i),headers=headers) selector = Selector(text=re.text) all_trs = selector.css("#ip_list tr") ip_list =[] for tr in all_trs[1:]: #因为第一个是表头 speed_str = tr.css(".bar::attr(title)").extract()[0] if speed_str: speed = float(speed_str.split("秒")[0]) all_texts = tr.css("td::text").extract() ip = all_texts[0] port = all_texts[1] proxy_type = all_texts[5] ip_list.append((ip,port,proxy_type,speed)) for ip_info in ip_list: cursor.execute( """ insert proxy_ip(ip,port,speed,proxy_type)VALUES (‘{0}‘,‘{1}‘,‘{2}‘,‘HTTP‘) """.format(ip_info[0],ip_info[1],ip_info[3]) ) conn.commit() class GetIP(object): #从数据库中删除无效的ip def delete_ip(self,ip): delete_sql = """ delete from proxy_ip where ip=‘{0}‘ """.format(ip) cursor.execute(delete_sql) conn.commit() return True def judge_ip(self,ip,port): #判断ip是否可用 http_url = "http://www.baidu.com" proxy_url = "http://{0}:{1}".format(ip,port) try: proxy_dict ={ "http":proxy_url } response = requests.get(http_url,proxies=proxy_dict) except Exception as e: print("invalid ip and port") self.delete_ip(ip) return False else: code = response.status_code if code>=200 and code<300: print("effective ip") return True else: print("invalid ip and port") self.delete_ip(ip) return False def get_random_ip(self): #随机获取 random_sql = """ SELECT ip,port FROM proxy_ip ORDER BY RAND() LIMIT 1 """ result = cursor.execute(random_sql) for ip_info in cursor.fetchall(): ip = ip_info[0] port = ip_info[1] judge_re = self.judge_ip(ip,port) if judge_re: return "http://{0}:{1}".format(ip,port) else: return self.get_random_ip() #print(craw_ips()) if __name__ == "__main__": get_ip = GetIP() get_ip.get_random_ip()
在middlewares中
from tools.crawl_xici_ip import GetIP
class RandomProxyMiddleware(object): #更换user-agent def process_request(self,request,spider): get_ip = GetIP() request.meta["proxy"] = get_ip.get_random_ip()
7-6 云打码实现验证码识别
验证码识别方法
1.编码实现(tesseract-orc)(识别率比较低)
2.在线打码(识别率90%以上)
3.人工打码
在线打码:云打码
用户注册,开发者账号注册
7-7 cookie禁用、自动限速、自定义spider的settings
settings
COOKIES_ENABLED = FALSE 这样子就是禁用
自动限速
可以在zhihu.py,lagou.py,jobbole.py中添加
custom_settings
={
COOKIES_ENABLED = TRUE /FALSE 表明是否禁用cookies,TRUE表示不禁用
}
DOWNLOAD_DELAY
更友好的对待网站,而不使用默认的下载延迟0。
自动调整scrapy来优化下载速度,使得用户不用调节下载延迟及并发请求数来找到优化的值。 用户只需指定允许的最大并发请求数,剩下的都交给扩展来完成。
AUTOTHROTTLE_ENABLED
默认: False
启用AutoThrottle扩展。
AUTOTHROTTLE_START_DELAY
默认: 5.0
初始下载延迟(单位:秒)。
AUTOTHROTTLE_MAX_DELAY
默认: 60.0
在高延迟情况下最大的下载延迟(单位秒)。
AUTOTHROTTLE_DEBUG
默认: False
以上是关于Scrapy突破反爬虫的限制的主要内容,如果未能解决你的问题,请参考以下文章