模拟ssh黏包hashlib模块
Posted xihuanniya
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模拟ssh黏包hashlib模块相关的知识,希望对你有一定的参考价值。
一、模拟ssh
1、subprocess模块
subprocess模块是python从2.4版本开始引入的模块。主要用来取代 一些旧的模块方法,如os.system、os.spawn*、os.popen*、commands.*等。subprocess模块可用于产生进程,并连接到进程的输入/输出/错误输出管道,并获取进程的返回值。
import subprocess
res = subprocess.Popen("dir",
shell=True,
stderr=subprocess.PIPE,
stdout=subprocess.PIPE)
# PIPE表示的是管道
# stdin,stdout,stderr:分别表示程序的标准输入、标准输出、标准错误。
print(res.stdout.read().decode("gbk"))
# 结果的编码是以当前所在的系统为准的,如果是windows,
# 那么res.stdout.read()读出的就是GBK编码的,在接收端需要用GBK解码
2、写一个模拟ssh的简单程序,即实现客户端向服务端发送一条终端命令,服务端执行这条命令后将执行结果返回给客户端,如下示例:


import socket import subprocess server = socket.socket() server.bind((‘127.0.0.1‘,8008)) server.listen(5) conn,addr = server.accept() while 1: data = conn.recv(1024).decode(‘utf8‘) res = subprocess.Popen(data, shell = True, stderr=subprocess.PIPE, stdout=subprocess.PIPE ) out_result = res.stdout.read() # 发生错误后结果 err_result = res.stderr.read() # 命令正确的结果 if out_result: conn.send(out_result) print(‘已发送给客户端‘,‘字节数是‘,len(out_result)) elif err_result: conn.send(err_result) print(‘发生错误‘,‘字节数是‘,len(err_result))
import socket client = socket.socket() client.connect((‘127.0.0.1‘,8008)) while 1: comm = input(‘请输入命令>>>‘).encode(‘utf8‘) client.send(comm) data = client.recv(1024) print(data.decode(‘gbk‘))
分析:试运行上面示例,分析有没有问题?
二、黏包
1、黏包现象:同时执行多条命令之后,得到的结果很可能只有一部分,在执行其他命令的时候又接收到之前执行的另外一部分结果,这种现象就是黏包。上述模拟ssh示例中最后一个服务器端代码就可能会出现黏包现象,因为服务端代码中连续写了两个send(一个send长度,一个send数据内容),send不会发生阻塞,所以造成两个send会形成一个包发送过去,接收方无法分辨哪些数据是哪个send发送的,也就无法获取到长度和内容。那么怎么解决黏包现象?
2、黏包成因
a、TCP协议中的数据传递
tcp协议的拆包机制:当发送端缓冲区的长度大于网卡的MTU时,tcp会将这次发送的数据拆成几个数据包发送出去。MTU(Maximum Transmission Unit)的意思是网络上传送的最大数据包。MTU的单位是字节。大部分网络设备的MTU都是1500,如果本机的MTU比网关的MTU大,大的数据包就会被拆开来传送,这样会产生很多数据包碎片,增加丢包率,降低网络速度。
面向流的通信特点和Nagle算法:TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端就难于分辨出来了,必须提供科学的拆包机制。即面向流的通信是无消息保护边界的。对于空消息:tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,即便是你输入空内容(直接回车),也可以被发送,udp协议会帮你封装上消息头发送过去。可靠黏包的tcp协议:tcp的协议数据不会丢,没有收完包,下次接收时,会继续上次继续接收,一端总是在收到ack时才会清楚缓冲区内容。数据是可靠的,但是会黏包。
基于tcp协议特点的黏包现象成因:
:
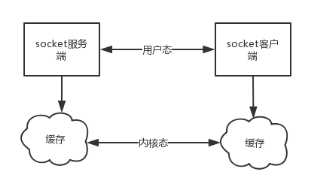
发送端可以是一K一K地发送数据,而接收端的应用程序可以两K两K地提走数据,当然也有可能一次提走3K或6K数据,或者一次只提走几个字节的数据。
也就是说,应用程序所看到的数据是一个整体,或说是一个流(stream),一条消息有多少字节对应用程序是不可见的,因此TCP协议是面向流的协议,这也是容易出现粘包问题的原因。
而UDP是面向消息的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,这一点和TCP是很不同的。
怎样定义消息呢?可以认为对方一次性write/send的数据为一个消息,需要明白的是当对方send一条信息的时候,无论底层怎样分段分片,TCP协议层会把构成整条消息的数据段排序完成后才呈现在内核缓冲区。
例如基于tcp的套接字客户端往服务端上传文件,发送时文件内容是按照一段一段的字节流发送的,在接收方看来,根本不知道该文件的字节流从何处开始,在何处结束;
此外,发送方引起的黏包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了黏包数据。
b、udp不会发生黏包
UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
对于空消息:tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,即便是你输入的是空内容(直接回车),也可以被发送,udp协议会帮你封装上消息头发送过去。
不可靠不黏包的udp协议:udp的recvfrom是阻塞的,一个recvfrom(x)必须对唯一一个sendinto(y),收完了x个字节的数据就算完成,若是y;x数据就丢失,这意味着udp根本不会粘包,但是会丢数据,不可靠。
总结:黏包现象只发生在tcp协议中:
1) 从表面上看,黏包问题主要是因为发送方和接收方的缓存机制、tcp协议面向流通信的特点;
2) 实际上,主要还是因接收方不知道消息之间的界限,不知道一次性提取多少字节的数据造成的;
3、struct模块
这个模块可以把要发送的数据长度转换成固定长度的bytes(字节),如下示例:
import struct
res1 = struct.pack("i",23767)
print(res1) # b‘xd7\\x00x00‘
print(len(res1)) # 4 固定长度是4个字节
obj1 = struct.unpack("i",res1)
print(obj1 , obj1[0]) # (23767,) 23767
4、黏包的解决方案
我们可以借助struct模块,这个模块可以把要发送的数据长度转换成固定长度的字节。这样客户端每次接收消息之前只要先接受这个固定长度字节的内容看一看接下来要接收的信息大小,那么最终接受的数据只要达到这个值就停止,就能刚好不多不少的接收完整的数据了。
|
发送时 |
接收时 |
|
先发送struct转换好的数据长度4字节 |
先接受4个字节使用struct转换成数字来获取要接收的数据长度 |
|
再发送数据 |
再按照长度接收数据
|
所以上述模拟ssh示例最终可以改为如下代码:
服务端
import socket
import subprocess
import struct
server = socket.socket()
server.bind((‘127.0.0.1‘,8008))
server.listen(5)
conn,addr = server.accept()
while 1:
data = conn.recv(1024).decode(‘utf8‘)
res = subprocess.Popen(data,
shell = True,
stderr=subprocess.PIPE,
stdout=subprocess.PIPE
)
out_result = res.stdout.read()
err_result = res.stderr.read()
if out_result:
conn.send(struct.pack(‘i‘,len(out_result))) # 构建报头
conn.send(out_result) # 发送报文
print(‘已发送给客户端‘,‘字节数是‘,len(out_result))
elif err_result:
conn.send(struct.pack(‘i‘,len(err_result))) # 构建报头
conn.send(err_result) # 发送报文
print(‘发生错误‘,‘字节数是‘,len(err_result))
客户端
import socket
import struct
client = socket.socket()
client.connect((‘127.0.0.1‘,8008))
while 1:
comm = input(‘请输入命令>>>‘).encode(‘utf8‘)
client.send(comm)
data_len = struct.unpack(‘i‘,client.recv(4))[0]
data_all = b‘‘
while len(data_all) < data_len:
data = client.recv(1024)
data_all += data
print(data_all.decode(‘gbk‘))
三、hashlib模块
1、算法介绍
python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过只要函数f1()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算(data)很容易,但通过digest反推data却非常困难,而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
我们之前学过一个简单用MD5加密的示例,如下:
import hashlib
md5 = hashlib.md5()
md5.update(b‘how to use md5 in python hashlib?‘)
print(md5.hexdigest()) # d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分多次调用update(),最后计算的结果是一样的,如下示例:
import hashlib
md5 = hashlib.md5()
md5.update(b‘how to use md5 in ‘)
md5.update(b‘python hashlib?‘)
print(md5.hexdigest()) # d26a53750bc40b38b65a520292f69306
MD5是最常见的摘要算法,速度很快,生成结果是固定的128bit字节,通常用一个32位的16进制字符串表示。另一种常见的只要算法是SHA1,调用SHA1和调用MD5完全类似,如下示例:
import hashlib
sha1 = hashlib.sha1()
sha1.update(b‘how to use sha1 in ‘)
sha1.update(b‘python hashlib?‘)
print(sha1.hexdigest()) # 2c76b57293ce30acef38d98f6046927161b46a44
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
2、算法应用
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
name | password
--------+----------
michael | 123456
bob | abc999
alice | alice2008
如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5:
username | password
---------+---------------------------------
michael | e10adc3949ba59abbe56e057f20f883e
bob | 878ef96e86145580c38c87f0410ad153
alice | 99b1c2188db85afee403b1536010c2c9
考虑这么个情况,很多用户喜欢用123456,888888,password这些简单的口令,于是,黑客可以事先计算出这些常用口令的MD5值,得到一个反推表:
‘e10adc3949ba59abbe56e057f20f883e‘: ‘123456‘
‘21218cca77804d2ba1922c33e0151105‘: ‘888888‘
‘5f4dcc3b5aa765d61d8327deb882cf99‘: ‘password‘
这样,无需破解,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对于用户来讲,当然不要使用过于简单的口令。但是,我们能否在程序设计上对简单口令加强保护呢?
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
hashlib.md5("salt".encode("utf-8"))
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的MD5。
摘要算法在很多地方都有广泛的应用。要注意摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文),只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。
四、补充知识
data = conn.recv(1024) # 阻塞
监听的套接字对象conn断开连接:
针对windows:异常报错。
针对linux:接收一个空的data。
以上是关于模拟ssh黏包hashlib模块的主要内容,如果未能解决你的问题,请参考以下文章