转自:https://www.cnblogs.com/sheeva/p/6406285.html
引子
作为一个偏爱windows的程序员,以前做文本处理的时候总是喜欢在windows下用notepad++等图形化工具处理,比如有时需要把linux服务器上一个文件进行一次全局字符串替换这样简单的操作,还得把文件down到本地编辑好再传回去。这两天买了本《鸟哥的Linux私房菜》,终于静下心系统的学习了一下linux下的文本处理,感觉其实没有想象的难,如果早点学会节约下来的大量时间肯定远超过学习所花的时间。
概览
先说一下本文要介绍的内容:
- 简单回顾一下正则表达式,如果熟悉正则,至少知道正则分为基本正则和扩展正则可以跳过该部分。
- 本文主体:介绍4个linux文本处理命令:grep、sed、printf、awk。
下面正式开始。
正则表达式回顾
这部分是给会正则表达式的读者简单回顾一下正则表达式,如果没学过正则表达式的读者建议先找相关资料学习正则表达式再来看本文。
正则表达式分为基本正则表达式和扩展正则表达式,内容如下:
基本正则表达式
| 正则表达式字符 | 含义 |
| ^word | 查找以word开头的文本 |
| word$ | 查找以word结尾的文本 |
| . | 代表一个任意字符 |
| \\ | 转义符 |
| * | 0到多个字符 |
| [abc] | 代表一个字符,这个字符是a或b或c |
| [a-z];[0-9] | 代表a到z中的一个字符;0到9中的一个数字 |
| [^abc] | 代表一个非a、b、c的字符 |
| {m,n} | m到n个字符 |
扩展正则表达式
| 正则表达式字符 | 含义 |
| + | 一个或多个字符 |
| ? | 零个或一个字符 |
| | | 或者 |
| () | 分组 |
文本处理命令
grep
grep的作用是按行查找字符,输出包含字符的行。
grep用法:
grep一般有两种用法,一种是从文件查找,一种是从管道的输入查找,
- grep ‘word‘ file.txt
- cat file.txt|grep ‘word‘
grep的常用参数:
| 参数 | 含义及示例 |
| -n | 输出结果加行号 |
| --color=auto | 匹配的关键字高亮显示 |
| -A3 | 输出匹配行的后三行 |
| -B2 | 输出匹配行的前两行 |
| -v | 反向查找,即输出不包含关键字的行 |
| -i | 关键字匹配时忽略关键字大小写 |
grep使用小技巧:
多数情况我们都想要高亮关键词(使用--color=auto参数),因此可以在~/.bashrc文件中添加上:
alias grep=‘grep --color=auto‘
,再用
source ~/.bashrc
让配置生效。这样当我们使用grep的时候,就自动带了--color=auto参数。
grep使用示例:
grep的查找主要就是基于基本正则表达式的匹配,下面只是简单的给一些常用例子供参考。
grep ‘t[ae]st‘ //查找tast或test
grep ‘[0-9]‘ //查找数字
grep ‘[^a-z]oo‘ //查找Xoo,其中X是一个非a到z的字符
grep ‘^the‘ //查找以the开头的字符,这里注意区分^出现在[]里时代表“非某字符”,如上个例子,出现在[]外时代表"以某字符开头",如这个例子。
grep ‘^$‘ //查找空行
grep ‘o\\{2\\}‘ //查找两个o,这里需要注意,{}在shell里有特殊意义,因此需要转义,这里与一般的正则使用不同,需要注意。
egrep:
我们知道正则表达式分为基本正则表达式和扩展正则表达式,但是grep只支持基本正则表达式,如果要是用扩展正则表达式,需要使用egrep命令。
几个例子:
egrep ‘gd|good‘ //查找gd或good
egrep ‘g(la|oo)d‘ //查找glad或good
egrep ‘A(xyz)+C‘ //查找AXC,其中X是一个或一个以上的‘xyz‘字符串。
sed
sed是一个很强大的命令,可以用来做行删除、行新增、行选取、行替换和字符串的替换这5种操作。
sed是一个管道命令,可以处理管道输入。
1.行删除
nl /etc/passwd | sed ‘2d‘ //删除第2行
下面将省略输入管道
sed ‘2,5d‘ //删除第2~5行
sed ‘3,$d‘ //删除第3到最后一行,$代表最后一行
sed ‘/^$/d‘ //删除空行
2.行新增
sed ‘2a drink tea‘ //在第二行下面追加一行"drink tea",a代表append
sed ‘2i drink tea‘ //在第二行上面插入一行"drink tea",i代表insert
sed ‘2a a\\
b\\
c‘ //在第二行下面追加三行 "a"、"b"、"c",只需要每行结尾加"\\"即可。
3.行选取
sed -n ‘5,7p‘ //选取第5到7行输出,必须加-n参数,不然效果就是所有行都被输出,而5到7行输出两次。
4.行替换
sed ‘2,5c No 2~5 lines‘ //将第2到5行替换为一行字符串"No 2~5 lines"
5.字符串替换
sed ‘s/要被替换的字符串/新的字符串/g‘ //固定的格式,开头是s结尾是g,中间三个/分隔开要被替换的字符串和新的字符串,注意这里要被替换的字符串可以是正则表达式。
将操作结果直接写入文件
默认用sed对文件做修改之后,只是输出修改后的文件,可以用>写入到新的文件。但是如果想修改原始文件,千万不能>到原始文件,这样执行的结果就是原文件直接被清空了。想要修改原始文件可以用 -i 参数,如:
sed -i ‘2d‘ file.txt //直接将原文件中的第二行删除。
直接修改原文件是很危险的,一旦修改错误无法还原。可以先不加 -i 参数执行命令把修改结果打印出来,确认无误后再加上 -i 参数。
printf
printf这个命令用语言不太好描述,但是一动手就明白了。
把下面的内容保存为printf.txt:
Name Chinese English Math Average DmTsai 80 60 92 77.33 VBird 75 55 80 70.00 Ken 60 90 70 73.33
先cat看一下,是下面这个效果:
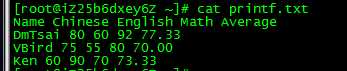
现在用printf指令加一些参数来看一下,执行
printf ‘%10s %10s %10s %10s %10s \\n‘ `cat printf.txt`
输出结果:

是不是比cat输出的结果漂亮多了。
%10s代表这一列的宽度固定为10个字符。更多的格式就不介绍了,这篇文章我们掌握一个%10s就够了。
printf不是管道命令,要想用它处理文件必须像上面的命令那样使用`cat printf.txt`把文件内容给提出来。
printf的使用相当广泛,后面的awk命令中也会应用到printf命令。
awk
awk命令主要是将文件通过分隔符拆成列来处理,还能通过条件判断对不同的行进行不同的处理,甚至还可以进行数值计算~
我们也是通过例子来学习。
我们先用last命令看一下最后登录的5个用户信息:

图中的第一列是用户名,第三列是用户ip,现在我们想摘出这两列,用awk就可以做到:
last -5|awk ‘{print $1 "\\t" $3}‘
输出:

命令看起来挺复杂,不要着急,其实很简单。
首先awk使用时有固定的格式:awk ‘{命令}‘,单引号和大括号就是固定的格式而已。
然后上面的命令就是
print $1 "\\t" $3 //awk默认会用空格和tab将每行分隔为N列,$1代表第一列,$3代表第三列。
这样一看是不是简单多了。
刚刚的last命令产生的数据默认就是用tab分隔的,现在我们看另一个例子,执行 cat /etc/passwd:
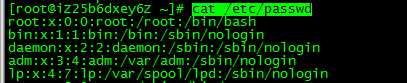
这次产生的数据每行是用 : 分隔的,那么想使用awk输出第一列和第三列就需要执行分隔符:
cat /etc/passwd|awk -F ‘:‘ ‘{print $1 "\\t" $3}‘ // -F ‘:‘ 代表指定使用 : 作为分隔符
执行结果:

除了$1,$3这样的特殊符号,
awk的命令中还可以使用下面的特殊符号:
NF :每一行分隔后的列数
NR :行号
下面用一个综合的例子来说明awk的条件判断和数值计算,有这样一组数据保存为pay.txt:
Name 1st 2nd 3rd VBird 23000 24000 25000 DMTsai 21000 20000 23000 Bird2 43000 42000 41000
现在想加一列"Total",计算每一行的数值总和。
用awk可以完成这个需求:
cat pay.txt |awk ‘NR==1 {printf "%10s %10s %10s %10s %10s \\n",$1,$2,$3,$4,"Total"};NR>1 {printf "%10s %10s %10s %10s %10s \\n",$1,$2,$3,$4,$2+$3+$4}‘
运行结果:

这里有几个要点:
- 加入条件判断后,awk的格式为: awk ‘条件1 {命令1};条件2{命令2}‘
- 条件判断有以下逻辑运算:
- >
- <
- >=
- <=
- == //注意判断相等要用两个等号
- !=
- 可以直接运算行内列的值($1、$2、$3)。
总结
这篇文章首先回顾了正则表达式(基本正则表达式、扩展正则表达式),然后介绍了4个常用命令,最后我们归纳一下四个命令的用途:
| 命令 | 用途 |
| grep/egrep | 关键字查找 |
| sed |
|
| printf | 文件格式化输出 |
| awk |
|