20172305 2018-2019-1 《Java软件结构与数据结构》第五周学习总结
Posted sanjinge
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了20172305 2018-2019-1 《Java软件结构与数据结构》第五周学习总结相关的知识,希望对你有一定的参考价值。
20172305 2018-2019-1 《Java软件结构与数据结构》第五周学习总结
教材学习内容总结
本周内容主要为书第九章内容:
查找是在某个项目组中寻找到某一指定目标元素,或者确定该指定目标并不存在。
高效的查找会使该过程所做的比较操作次数最小化。
静态方法(类方法)可以通过类名调用,不能引用实例变量,可以引用静态变量。Java程序的main方法必须用static修饰符(声明为静态)来修饰,解释器不用实例化含有main的类的对象,就可以调用main方法。
泛型方法创建一个引用泛型的方法,只需在方法头的返回类型前插入一个泛型声明即可。含有返回类型和参数类型的方法,就可以使用泛型参数。泛型声明必须位于返回类型之前,这样泛型才可以作为返回类型的一部分。
线性查找时间复杂度O(n)从列表头开始依次比较每一个值,直至找到该目标,结果是要么找到目标,要么到达列表尾并得出该组中不存在该目标的结论。
二分查找时间复杂度O(logn)从排序列表的中间开始查找,如果中间元素不是目标元素,则继续取半搜索。在每一次比较操作后,将排除剩余待搜索的一半数据。
- 线性查找和二分查找的优劣:
- 线性查找一般比二分查找要简单得多,编程和调试都很容易;
- 二分查找利用查找池已排序的适时进行查找的;
- 对于大型查找池二分查找非常有效率。
- 排序
- 顺序排序(大约进行n方次比较):选择排序、插入排序、冒泡排序
- 对数排序(大约进行nlogn次比较):快速排序、归并排序
选择排序算法通过反复的将某一特定值放到它在列表中的最终已排序位置,从而完成对某一列值的排序。
插入排序算法通过反复地将某一特定值插入到该列表某个已排序的字集中来完成对列表值的排序。
冒泡排序算法通过重复地比较相邻元素且在必要时(彼此不符顺序)将它们互换,从而完成対值的排序。
快速排序通过使用任意选定的分区元素将该列表分区,然后对分区元素的任一边的子列表进行递归排序。
归并排序算法是通过将列表递归式分成两半直至每一子列表都只含有一个元素,然后将这些子列表归并到一个排序顺序中,从而完成对列表的排序。
基数排序是基于队列处理的,通过排序关键字的部份,将要排序的元素分配至某些队列中,通过出队入队以达到排序的作用。
- 各种排序的比较图:
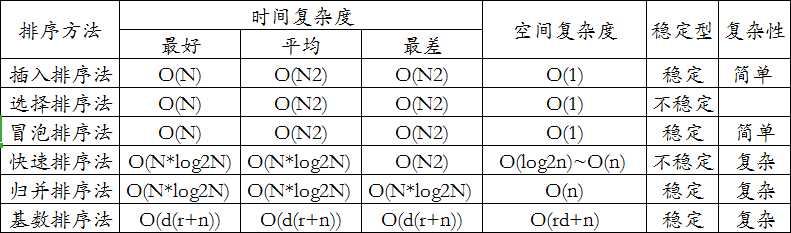
- 基数排序中:r代表关键字的基数,d代表长度,n代表关键字个数
教材学习中的问题和解决过程
- 问题1:<T extends Comparable<? super T>>是什么意思?
- 问题1解决方案:书上的查找方法都用到这一串代码,里面有泛型T、继承标识符extends、Comparable接口、和指向父类的指针,只有?的意思不懂。通过上网查找,“?”可以代表范围内任意类型,整体含义是类型T必须实现Comparable接口,并且这个接口的类型是T或者是T的任一父类。这样声明后,T的实例之间和T的父类的实例之间可以相互比较大小,其中<? super T>是表示泛型的下限。
- 追问(1.) 那么问题又来了,<? super T>是表示泛型的下限,那么泛型的上限又是什么?
追问(2.) 泛型的上下限有什么作用?
- 和泛型的下限表示方法类似,<? extends T>表示的是泛型的上限。super表示包括T在内的任何T的父类,extends表示包括T在内的任何T的子类。 “有界类型”的泛型避免了强制类型转换的同时保留了安全性能,使得转换有了一定的限制。在一定程度上提高了代码的灵活性,随便用相关的类。
追问(3.)
<T extends Comparable<T>>和<T extends Comparable<? super T>>或<T extends Comparable<? extends T>>有什么不同?- 少了?和super,两者的意义会有很大的变化,前者表示的是类型T必须实现Comparable接口,并且这个接口的类型是T。只有实现接口的T的实例才会相互比较,而后者是表示类型T必须实现Comparable接口,并且接口的类型是T或者是T的任一父类或子类。

- 少了?和super,两者的意义会有很大的变化,前者表示的是类型T必须实现Comparable接口,并且这个接口的类型是T。只有实现接口的T的实例才会相互比较,而后者是表示类型T必须实现Comparable接口,并且接口的类型是T或者是T的任一父类或子类。
创建具有继承关系的类,一个是Anima类,另一个是Cat类。但是在Animal中实现了Comparable
接口,通过年龄来比较实例的大小Cat继承了Animal类,分别使用sort1和sort2进行测试。 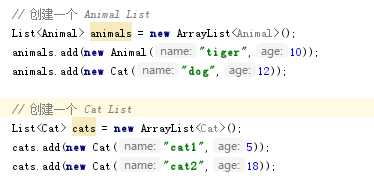
sort1(Animal)结果是正常按照年龄进行排序,sort1(cat)结果会报错。仅因为Animal实现了接口Comparable。但是,如果是List 程序将报错,因为Cat类中没有实现接口Comparable ,它只从Animal继承了一个Comparable 接口。 sort2(Animal)和sort2(Cat)的结果均按照年龄进行排序。(比较的参数类型不同在后者的情况下也可以进行比较,大大的提高了代码的灵活性与自由度。)追问(4.)如果在子类中实现Comparable接口的话是否可以改善sort1比较的差异?
- 如果父类实现了接口,那么子类就继承了相关的接口不能重新实现接口;相反只能重写父类CompareTo的方法来达到进行子类的比较。
- 问题2:泛型方法的各部分意义?与普通方法的区别?
问题2解决方案:泛型方法的定义和普通方法定义不同的地方在于需要在修饰符和返回类型之间加一个泛型类型参数的声明,表明在这个方法作用域中谁才是泛型类型参数,规定了泛型的范围,从这一点可以看出罚你性能高的优势就是提高了代码的灵活性。
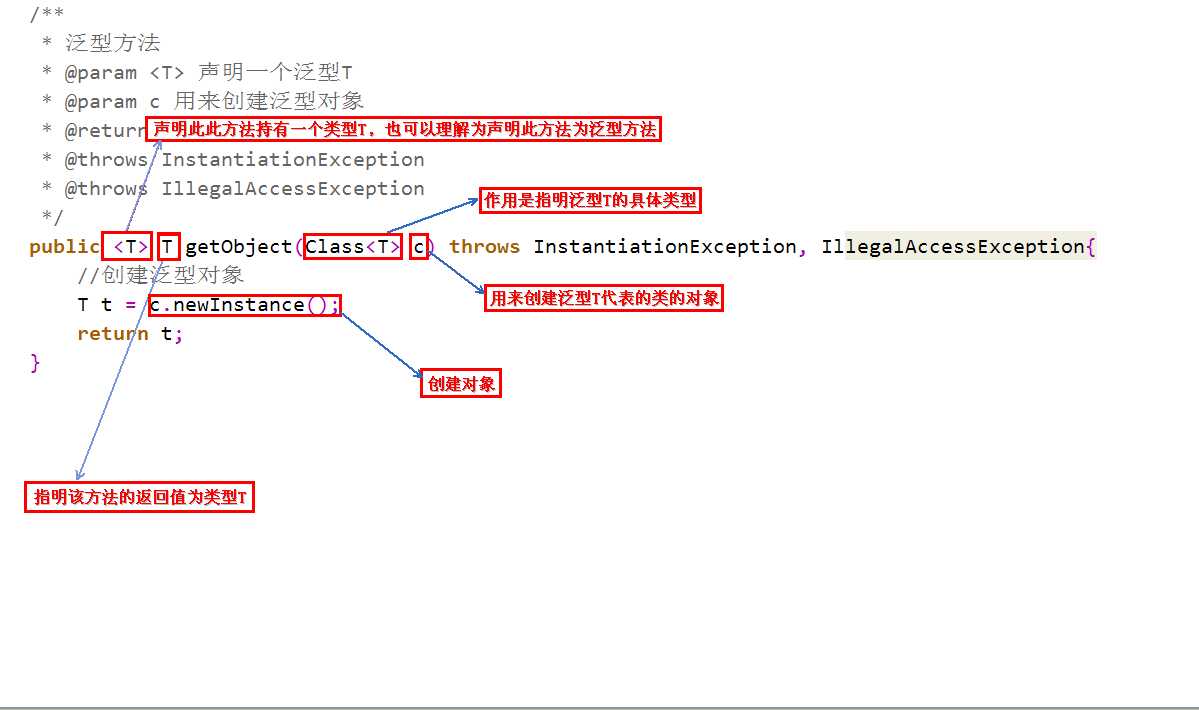
- 泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型。
- 问题3:优化代码的示例(课堂内容)
问题3解决方案:
public static <T>
boolean linearSearch(T[] data, int min, int max, T target)
{
int index = min;
boolean found = false;
while (!found && index <= max)
{
found = data[index].equals(target);
index++;
}
return found;
}针对这串代码我的第一想法就是用二分查找替代这种线性查找,但是不符合老师的要求。整串代码能够优化的部分就是while循环里面的!found、index <= max、found = data[index].equals(target)、index++四部分,我觉得可以把!found和found = data[index].equals(target)进行合并,这样可以i吉安少一条语句的运行,但实质上并没有进行变化同样的判断与测试看似两条语句变一条语句,其程度遍复杂了,要执行一次比较,在进行一次布尔型的判断。而老师给出的答案是设立一个哨兵,也就是数组索引值为0的位置加入目标元素,如果在未遍历到头就结束的话就能判断数组内含有该元素,而且找到该元素;如果到哨兵的位置找到的话,那就说明没有该元素,也就是不用判断index <= max示例答案中并没有判断是否到了尾部的相关代码。(示例代码并没与在复杂度上解决该问题,但是在性能上有所提高。针对这一结果也是醉了)
data[0] = target;
for (index = data.length-1; !data[indax].equals(target);--index){
}
return index == 0? false:true;代码学习中的问题和解决过程
- 问题1:PP9.2间隔排序法的循环条件是什么?
- 问题1的解决方案:根据题目的要求间隔排序法实质涵盖了冒泡排序法,冒泡排序是间隔为1的两个元素,实质就是相邻元素的是否交换。针对间隔排序法实现的代码,是在冒泡排序的基础上实现的,但是冒泡排序的外循环是以达到数组长度减一就停止的。
在第一次改写的时候没有动内外循环,只是把数组交换的索引值改了,结果就报数组越界异常(ArrayIndexOutOfBoundsException)。其实是因为在增加间隔的时候外循环还是在一个个的遍历,导致数组的越界。
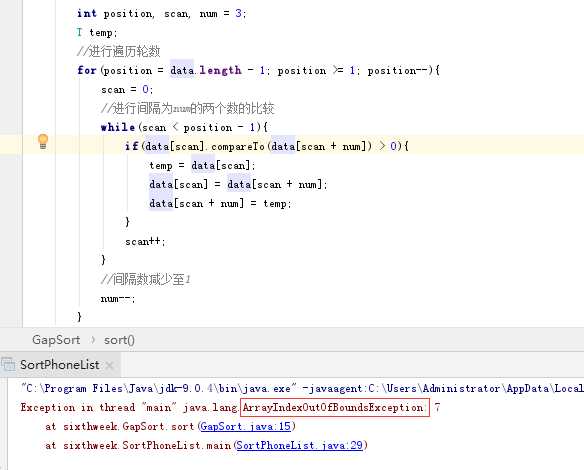
第二次稀里糊涂的改了个内层循环的条件结果是可以进行排序,但是末尾的两个元素或是三个元素(间隔次数不同)始终不排序,考虑到可能是间隔不为1的时候尾部两个元素或是三个元素没有排序,在达到间隔为1的时候有直接跳出没排导致的(感觉自己第二次修改的时候好迷)。
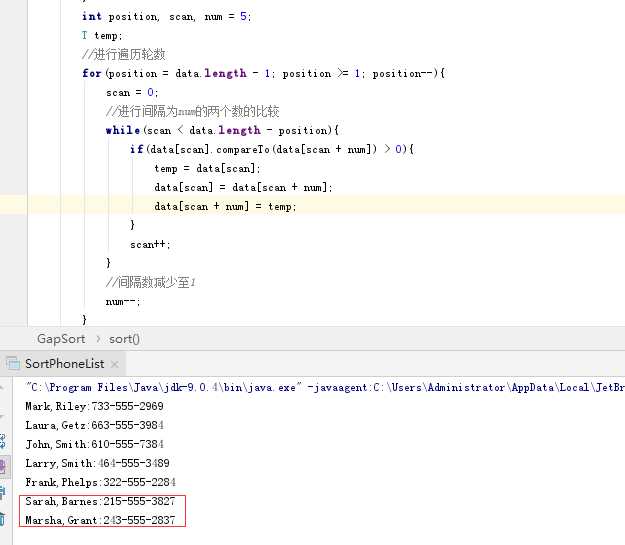
第三次进行了大修改,因为考虑到间隔次数是在递减正好替换以数组长度为外层循环条件。而内层循环在经历过第二次排序后发现在间隔次数未达到1的情况下数组元素始终有小于间隔次数的元素没有进行排列,而此刻的索引值最大就是数组长度减去间隔次数。
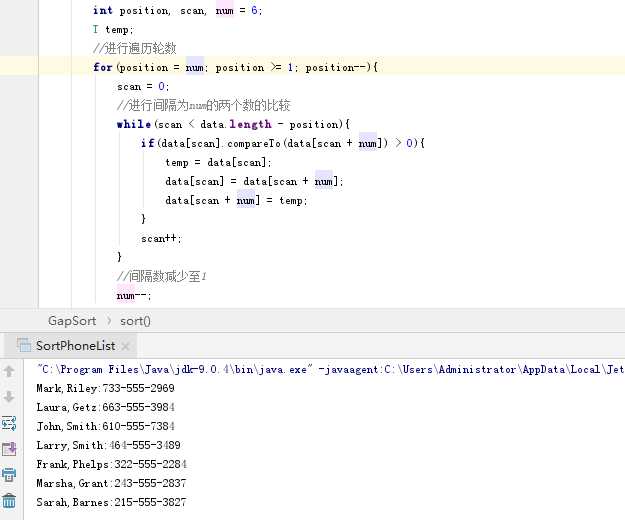
个人觉得在进行间隔数减小的过程中包含了冒泡排序的过程,而仅使用冒泡排序就可以达到排序的目的,觉得这种排序方法除非是进行间隔几个元素的情况下进行排列的类型,其余情况下好像用处并不大。
- 问题2:System.nanoTime()的代码解析
- 问题2解决方案:时间代码在放假的时候就看了一部分,接触的相关类都是像Calendar计算多少天、多少年的类以及SimpleDateFormat进行格式化输出时间的类和LocalDate记录日期的类。而System.nanoTime()在上网查找之后发现是以long形式输出系统计时器的当前值,然后两个值进行相减就可以表示出运行时间。在类的开头可结尾各方一个进行记录在相减就可以了。

[代码托管]
上周考试错题总结
- 错题1:Interfaces allow us to make polymorphic references, in which the method that is invoked is based on the type of the reference variable rather than the particular object being referenced at the time.
- A .true
- B .false
- 错误解析:接口允许我们创建多态引用,其中被调用的方法是基于被引用时的特定对象的。(书后关键概念)
第六章和之前的错误一样,还是没有认真的看好题目就选上了。就是简单的一道书后关键概念就丧失了满分的机会,扎心...下次遇到这种会做的题目一定不要在选错了!!!
结对与互评
点评(王禹涵)
- 博客中值得学习的或问题:
- 博客中对于问题的图片放得很到位,解释的很好。
- 代码中值得学习的或问题:
- 问题及解决方案说得很到位,建议图片可以小点。
- 基于评分标准,我给本博客打分:6分。
- 得分情况如下:
- 正确使用Markdown语法(加1分)
- 模板中的要素齐全(加1分)
- 教材学习中的问题和解决过程, 一个问题加1分
- 代码调试中的问题和解决过程, 一个问题加1分
- 感想,体会不假大空的加1分
- 点评认真,能指出博客和代码中的问题的加1分
点评(方艺雯)
- 博客中值得学习的或问题:
- 图片运用恰当,很清晰的解释了问题和相关内容。
- 基于评分标准,我给本博客打分:9分。
- 得分情况如下:
- 正确使用Markdown语法(加1分)
- 模板中的要素齐全(加1分)
- 教材学习中的问题和解决过程, 二个问题加2分
- 代码调试中的问题和解决过程, 三个问题加3分
- 感想,体会不假大空的加1分
- 点评认真,能指出博客和代码中的问题的加1分
互评对象
本周结对学习情况
20172314方艺雯
20172323王禹涵结对学习内容:查找和排序
感悟
第六章的内容是用数组和链表表示列表的,在一定还曾独上列表和队列、栈都有一定程度上的相似,部分代码完全可以之前编写的,唯一觉得比较恶心的就是在添加的过程中就直接被排序。通过这几章学的内容,对链表和数组有了更多的认识,应用起来也比较顺手。勤能补拙,多联系多尝试总没有错的。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 15/15 | |
| 第二周 | 703/703 | 1/2 | 20/35 | |
| 第三周 | 762/1465 | 1/3 | 20/55 | |
| 第四周 | 2073/3538 | 1/4 | 40/95 | |
| 第五周 | 2073/3538 | 2/6 | 40/135 |
参考资料
以上是关于20172305 2018-2019-1 《Java软件结构与数据结构》第五周学习总结的主要内容,如果未能解决你的问题,请参考以下文章