待修改[HDFS_1] HDFS 的概念和特性
Posted share23
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了待修改[HDFS_1] HDFS 的概念和特性相关的知识,希望对你有一定的参考价值。
0. 参考
1. HDFS 是什么
HDFS :一种分布式文件系统,可提供对应用程序数据的高吞吐量访问,解决海量数据存储问题。
2. HDFS 产生的背景 & 设计前提
随着互联网的发展,数据产生的数量越来越大,速度越来越快。传统的文件系统所依赖的服务器价格昂贵,提高其处理性能成本较高且已达到技术瓶颈,纵向扩展并不符合当今需求。
HDFS 它的设计目标就是把超大的数据集存储到多台普通计算机上(横向扩展),并且可以提供高可靠性和高吞吐量的服务,支持通过添加节点的方式对集群进行扩容。所以 HDFS 有着它自己的设计前提:
对存储大文件支持很好,不适用于存储大量小文件
通过流式访问数据,保证高吞吐量而不是低延时的用户响应
简单一致性,使用场景应为一次写入多次读取,不支持多用户写入,不支持任意修改文件。
冗余备份机制,空间换可靠性(Hadoop3中引入纠删码机制,纠删码需通过计算恢复数据,实为通过时间换空间,有兴趣的可以查看 RAID 的实现)
移动计算优于移动数据,为支持大数据处理主张移动计算优于移动数据,提供相关接口。
3. HDFS 的优缺点
3.1 HDFS 的优点
HDFS 被设计成适合运行在通用和廉价硬件上的分布式文件系统。它和现有的分布式文件系统有很多共同点,但他和其它分布式文件系统的区别也是明显的。HDFS 是基于流式数据模式访问和处理超大文件的需求而开发的,其主要特点如下:
【1. 处理超大文件】
这里的超大文件通常指的是 GB、TB 甚至 PB 大小的文件。通过将超大文件拆分为小的 HDFS,并分配给数以百计、千计甚至万计的的节点,Hadoop 可以很容易地扩展并处理这些超大文件。
【2. 运行于廉价的商用机器集群上】
HDFS 设计对硬件需求比较低,只需运行在低廉的的商用机器集群上,而无须使用昂贵的高可用机器。在设计 HDFS 时要充分考虑数据的可靠性、安全性和高可用性。
【3. 高容错性和高可靠性】
HDFS 设计中就考虑到低廉硬件的不可靠性,一份数据会自动保存多个副本(具体可用设置,通常三个副本),通过增加副本的数量来保证它的容错性。如果某一个副本丢失,HDFS 会自动复制其它机器上的副本。
当然,有可能多个副本都会出现问题,但是 HDFS 保存的时候会自动跨节点和跨机架,因此这种概率非常低,HDFS 同时也提供了各种副本放置策略来满足不同级别的容错需求。
【4. 流式的访问数据】
HDFS 的设计建立在更多低相应 “一次写入,多次读写” 任务的基础上,这意味着一个数据集一旦有数据源生成,就会被复制分发到不同的存储节点中,然后响应各种各种的数据分析任务需求。在多数情况下,分析任务都会涉及数据集的大部分数据,也就是说,对 HDFS 来说,请求读取整个数据集比请求读取单条记录会更加高效。
3.2 HDFS 的缺点
HDFS 的上述种种特点非常适合于大数据量的批处理,但是对于一些特点问题不但没有优势,而且有一定的局限性,主要表现以下几个方面:
【1. 不适合低延迟数据访问】
如果要处理一些用户要求时间比较短的低延迟应用请求(比如毫秒级、秒级的响应时间),则 HDFS 不适合。HDFS 是为了处理大型数据集而设计的,主要是为了达到高的数据吞吐量而设计的,延迟时间通常是在分钟乃至小时级别。
对于那些有低延迟要求的应用程序,HBase 是一个更好的选择,尤其是对于海量数据集进行访问要求毫秒级响应的情况,单 HBase 的设计是对单行或少量数据集的访问,对 HBase 的访问必须提供主键或主键范围。
【2. 无法高效存储大量小文件】
【3. 不支持多用户写入和随机文件修改】
在 HDFS 的一个文件中只有一个写入者,而且写操作只能在文件末尾完成,即只能执行追加操作。
4. HDFS 架构
【HDFS 架构图 】
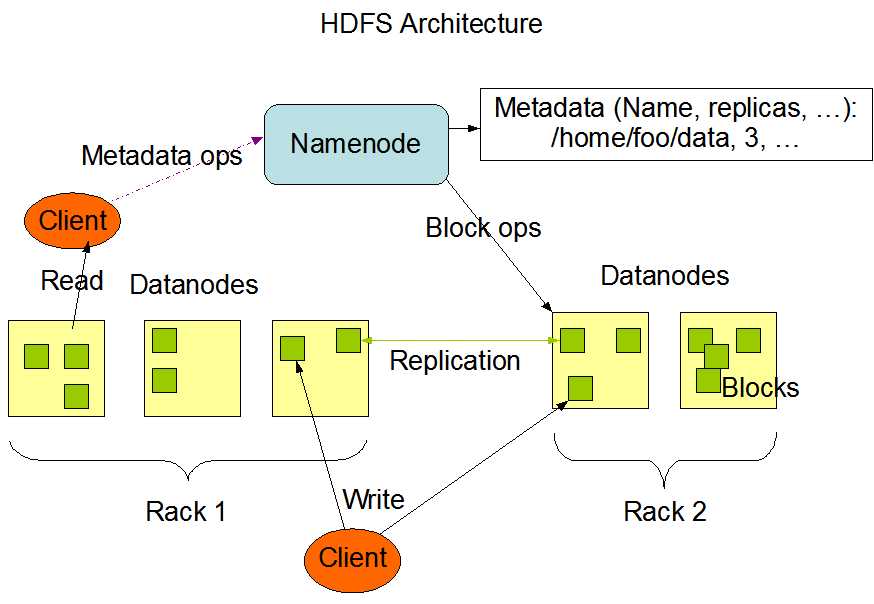
HDFS 负责分布式存储。
HDFS 采用了主从(Master/Slave)的结构模型,一个 HDFS 集群是由一个 NameNode 和若干个 DataNode 组成的。
1. HDFS Client
客户端可以通过一些命令访问 HDFS,通过访问 NameNode 获取文件的元数据信息,与 DataNode 交互读取文件。
客户端同时负责对文件的切分,在文件上传时,客户端将文件切分成Block进行存储。
2. NameNode
NameNode 作为 Master,用于存储文件的元数据信息(文件类型、大小、路径、权限等),它也负责数据块到具体 DataNode 的映射。
NameNode 执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等。
3. DataNode
DataNode 作为 Slave,负责处理文件系统客户端的文件读写请求,并在 NameNode 的统一调度下进行数据块的创建、删除和复制工作。
集群中 DataNode 管理存储的数据。HDFS 允许用户以文件的形式存储数据。从内部来看,文件被分成若干数据块,而且这若干个数据块存放在一组 DataNode 上。
4. Secondary NameNode
Secondary NameNode 作为 NameNode 的辅助节点,在 NameNode 无法正常运行的情况下辅助 NameNode 恢复。
他的主要任务是合并 NameNode 的 edit logs 到 fsimage 文件中。
4. HDFS 文件块(Block)的大小
Hadoop1.x 的 HDFS 默认块大小为 64MB;Hadoop2.x 的默认块大小为 128MB。
如果进行数据块的自定义需要修改 hdfs-site.xml 文件,例如:
待补充。。。
以上是关于待修改[HDFS_1] HDFS 的概念和特性的主要内容,如果未能解决你的问题,请参考以下文章