收集分析线上日志数据实战——ELK
Posted 163yun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了收集分析线上日志数据实战——ELK相关的知识,希望对你有一定的参考价值。
本文来自网易云社区
作者:田躲躲
用户行为统计(User Behavior Statistics, UBS)一直是互联网产品中必不可少的环节,也俗称埋点。对于产品经理,运营人员来说,埋点当然是越多,覆盖范围越广越好。通过用户行为分析系统可洞悉用户基本操作习惯、探析用户心理。通过行为数据的补充,构建出精细、完整的用户画像,对不同特征用户做个性化营销,提升用户体验。让产品设计人员准确评估用户行为路径转化、产品改版优良、某一新功能对产品的影响几何,让运营人员做精准营销并且评估营销结果等。
目前所负责项目前期采用了前后端约定字段,埋点统计用户操作行为。数据存放在DDB中。如果用户行为日志非常大的话,这种方式肯定是不可行的。故采用了目前比较成熟的ELK代替之前的统计流程。本篇文章主要介绍ELK集群搭建,基本API封装,以及遇到的一些坑。
Elasticsearch是一个基于Lucene构建的开源、分布式、RESTful风格的搜索引擎。它被设计用于云计算中,具有实时搜索负载、稳定、快速、安装使用方便等优点。(之前用过SolrCloud,ES对用户的侵入性简直可以忽略)
集群安装:
每台机器先配置elasticsearch.yml,主要配置信息如下:
# # ---------------------------------- Cluster ----------------------------------- # # Use a descriptive name for your cluster: # cluster.name: es-commenta-event #其他机器集群名称应该保持一致 # # ------------------------------------ Node ------------------------------------ # # Use a descriptive name for the node: # node.name: es-node-c1 # # Add custom attributes to the node: # #node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # # Path to directory where to store the data (separate multiple locations by comma): # path.data: /opt/elk/elasticsearch-5.1.1/data # # Path to log files: # path.logs: /opt/elk/elasticsearch-5.1.1/logs # # ----------------------------------- Memory ----------------------------------- # # Lock the memory on startup: # #bootstrap.memory_lock: true # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- Network ----------------------------------- # # Set the bind address to a specific IP (IPv4 or IPv6): # network.host: 192.168.140.133 #本机器host # # Set a custom port for HTTP: # #http.port: 9200 # # For more information, see the documentation at: # <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-network.html> # # --------------------------------- Discovery ---------------------------------- # # Pass an initial list of hosts to perform discovery when new node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # discovery.zen.ping.unicast.hosts: ["192.168.140.133", "192.168.140.134", "192.168.140.135"] #集群host列表 # Prevent the "split brain" by configuring the majority of nodes (total number of nodes / 2 + 1): # discovery.zen.minimum_master_nodes: 2
集群启动:
Q1:can not run elasticsearch as root
因为是本地虚拟机root安装的,启动的时候会报这个错。解决方案是:
group esgroup useradd esuser -g esgroup -p espassword chown -R esuser:esgroup /etc/ chown -R esuser:esgroup /opt/
切换到esuser用户即可执行启动命令。
Q2:Unsupported major.minor version 52.0
目前安装的ES版本为5.1.1,需要Jdk1.8的版本,故安装下Jdk1.8,配置下环境变量,即可执行启动命令。
Q3:max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
ES启动占用更大的内存。修改如下:
sysctl -w vm.max_map_count=262144
每个ES服务设置好后,就可以真正启动了。依次启动机器的时候,可以看下机器日志是否有node加入到集群。如:
curl ‘192.168.140.133:9200‘{ "name": "es-node-c1",
"cluster_name": "es-commenta-event",
"cluster_uuid": "wi_1VOWoRqecjIht3Ra3mg",
"version": { "number": "5.1.1",
"build_hash": "5395e21",
"build_date": "2016-12-06T12:36:15.409Z",
"build_snapshot": false,
"lucene_version": "6.3.0"
},
"tagline": "You Know, for Search"}目前有3台虚拟机,默认ES有5个节点,可以通过命令创建3个节点的index,每个主节点有一个复制节点。
curl -XPUT ‘http://192.168.140.133:9200/commenta‘ -d ‘{"settings" : {"number_of_shards" : 3,"number_of_replicas" : 1}}‘集群状态:
curl ‘http://192.168.140.133:9200/_cluster/health?pretty‘{ "cluster_name" : "es-commenta-event", "status" : "green", "timed_out" : false, "number_of_nodes" : 3, "number_of_data_nodes" : 3, "active_primary_shards" : 3, "active_shards" : 6, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 50.0}安装插件:
通过类SQL转化成DSL bin/elasticsearch-plugin install install https://github.com/NLPchina/elasticsearch-sql/releases/download/5.1.1.0/elasticsearch-sql-5.1.1.0.zip
X-Pack集成了权限、监控等功能,是一款非常有用的插件。但是商用的,收费。 bin/elasticsearch-plugin install x-pack
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置。
安装:
到官网下载logstash5.1.1版本即可。
启动:
1、无配置文件启动
bin/logstash -e ‘input{ stdin{} } output{ stdout{} }‘Sending Logstash‘s logs to /home/webedit/logstash/logstash-5.1.1/logs which is now configured via log4j2.properties
The stdin plugin is now waiting for input:
[2017-04-27T15:47:38,023][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>4, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>500}
[2017-04-27T15:47:38,039][INFO ][logstash.pipeline ] Pipeline main started
[2017-04-27T15:47:38,115][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
hello elastic
2017-04-27T07:49:00.966Z localhost.localdomain hello elasticlogstash会采集命令行输入的命令
2、配置文件启动
假设我们需要采集的日志记录是这种格式的:
INFO [17.04.27 16:12:12][com.netease.mail.vip.commenta.filter.EventLogFilter]: |44171|1|1|1|1493280732227|0.0|123.58.160.131|133001|COMMENTA-B54C43F5-4FCB-4D10-B9EC-67862FBF0055|1493280732440|huiping_mp|0.7.0|null|1|
如何采集这种格式的日志呢?这里采用正则表达式去匹配,具体配置文件如下:
input {
file {
type => "commenta"
path => ["/home/logs/commenta/stdout.log"]
start_position => "beginning"
codec => plain { charset => "Windows-1252" }
}
}
filter {if [type] == "commenta" {
grok {
match => { "message" => "%{DATA:className}|%{BASE16FLOAT:id}|%{DATA:eventType:int}|%{DATA:page:int}|%{DATA:eventFrom:int}|%{DATA:eventTime}|%{BASE16FLOAT:eventWeight}|%{DATA:ip}|%{BASE16FLOAT:userId}|%{DATA:uniqueCode}|%{DATA:createTime}|%{DATA:clientFrom}|%{DATA:appVersion}|%{DATA:data}|%{DATA:eventStep:int}|"}
remove_field => ["message"]
}
}if ‘_grokparsefailure‘ in [tags] { #过滤掉不匹配的事件
drop{}
}
mutate { #数据类型转换
convert => [ "eventWeight", "float"]
convert => [ "id", "float"]
convert => [ "userId", "float"]
}
}
output{
stdout { codec => rubydebug } #打印出行为日志记录在控制台
elasticsearch{
hosts => ["192.168.140.133:9200","192.168.140.134:9200","192.168.140.135:9200"]
index => "commenta"
}
}下面我们可以启动logstash看下效果:
./bin/logstash -f ./config/logstash.conf{ "appVersion" => "0.7.0", "data" => "null", "ip" => "XXXXXXXXX", "className" => "INFO [17.04.27 16:12:12][com.netease.mail.vip.commenta.filter.EventLogFilter]: ", "eventType" => 1, "type" => "commenta", "eventWeight" => 0.0, "userId" => 133001.0, "tags" => [], "path" => "/home/logs/commenta/stdout.log", "@timestamp" => 2017-04-27T08:18:58.245Z, "uniqueCode" => "COMMENTA-B54C43F5-4FCB-4D10-B9EC-67862FBF0055", "createTime" => "1493280732440", "@version" => "1", "host" => "testfb-m126-161", "eventTime" => "1493280732227", "eventStep" => 1, "clientFrom" => "huiping_mp", "id" => 44171.0, "page" => 1, "eventFrom" => 1}通过打印在控制台的日志可以看到我们已经通过logstash收集到了行为日志记录(部分数据已脱敏)。当然我们也可以通过Kibana看到这些数据,下部分将会讲到。
3、启动问题
Q1:Unsupported major.minor version 52.0
使用的是Logstash版本为5.1.1,需要Jdk1.8的环境,故安装下Jdk1.8,配置下环境变量,即可执行启动命令。
Q2:unknown setting host for elasticsearch
配置Logstash的启动文件时,注意版本的问题,如host-->hosts
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等kibana能够很轻易地展示高级数据分析与可视化。
安装:
到官网下载Kibana5.1.1版本即可。
启动:
主要配置如下:
# Kibana is served by a back end server. This setting specifies the port to use. #server.port: 5601 # Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values. # The default is ‘localhost‘, which usually means remote machines will not be able to connect. # To allow connections from remote users, set this parameter to a non-loopback address. server.host: "192.168.140.133" # Enables you to specify a path to mount Kibana at if you are running behind a proxy. This only affects # the URLs generated by Kibana, your proxy is expected to remove the basePath value before forwarding requests # to Kibana. This setting cannot end in a slash. #server.basePath: "" # The maximum payload size in bytes for incoming server requests. #server.maxPayloadBytes: 1048576 # The Kibana server‘s name. This is used for display purposes. #server.name: "your-hostname" # The URL of the Elasticsearch instance to use for all your queries. elasticsearch.url: "http://192.168.140.133:9200" .......
启动成功后,我们可以监控commenta*的索引(安装ES的时候,创建了)
bin/kibana
这时候就可以看到Logstash收集到的数据日志了
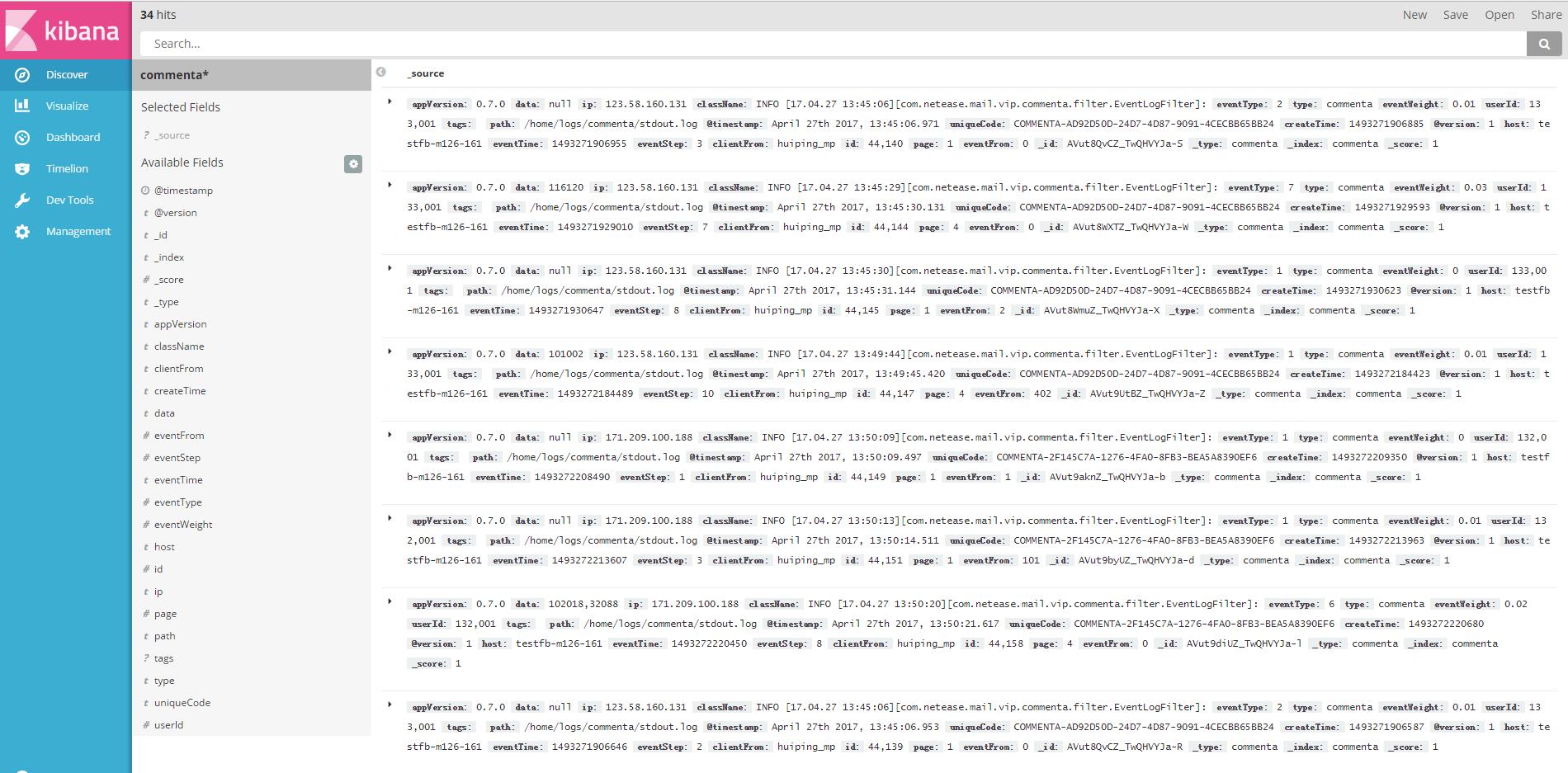
当然我们也可以配置一些统计:
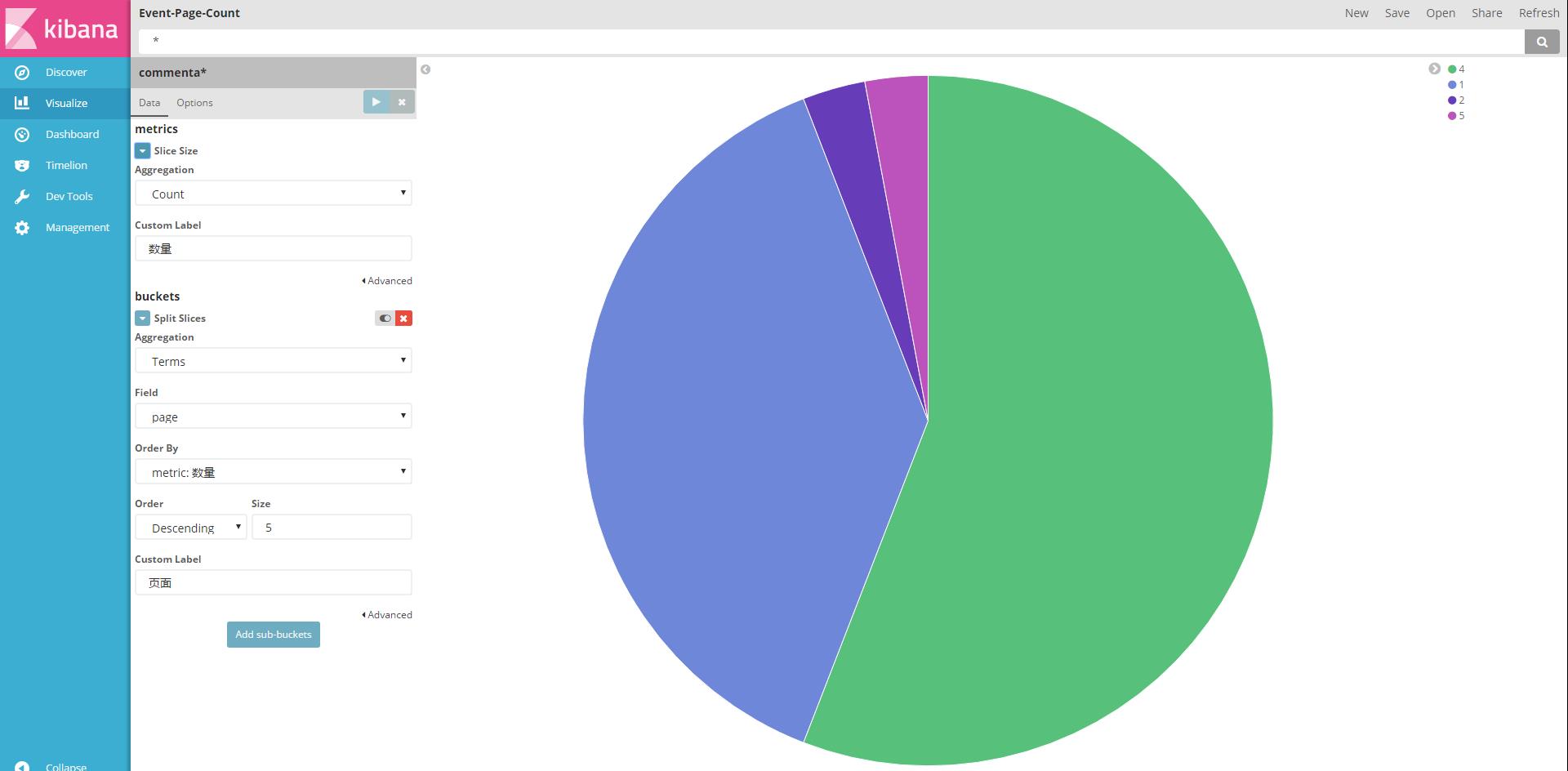
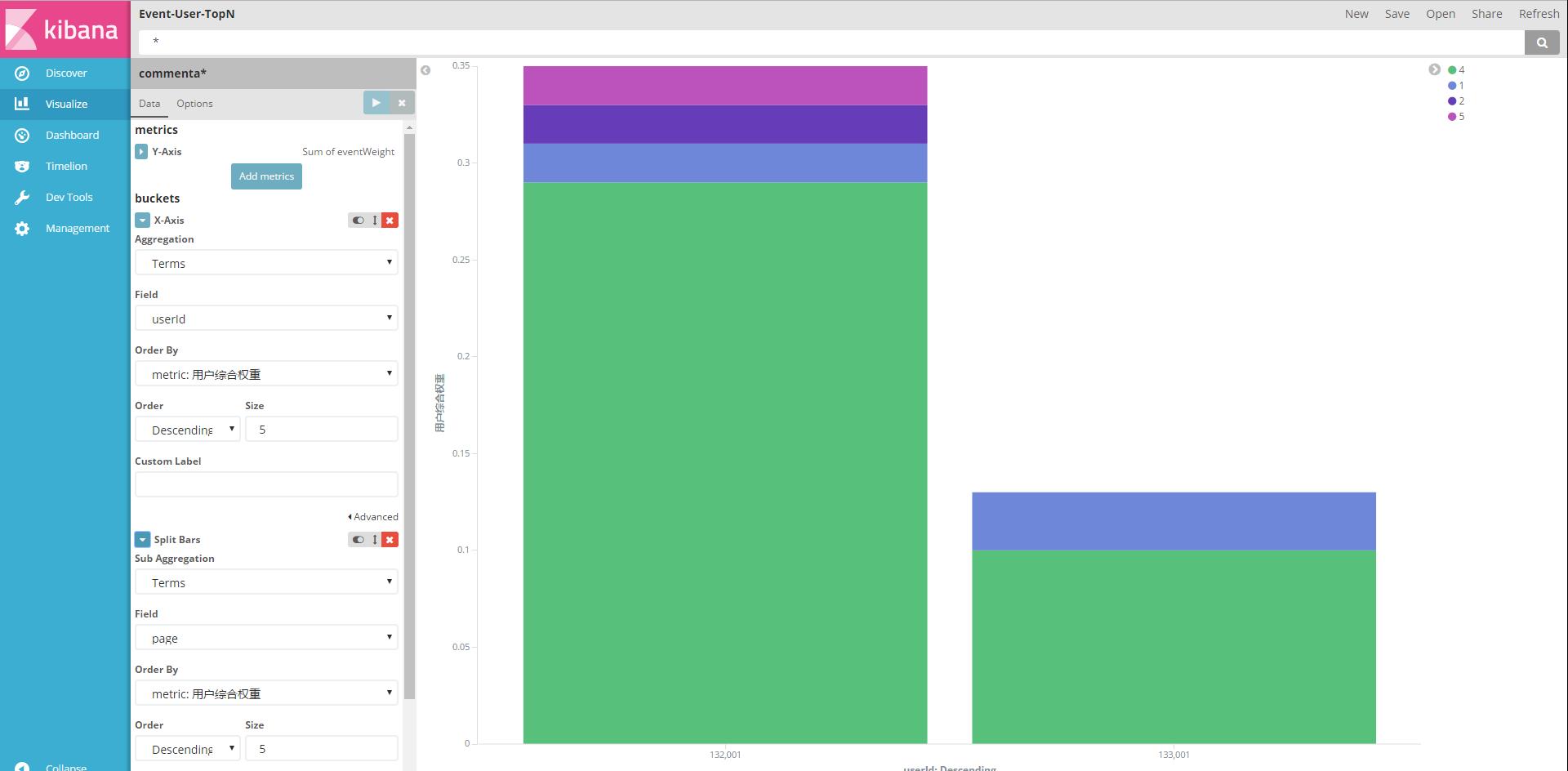
为了更直观的展示,我们可以把统计“拖拽”到Dashboard中。
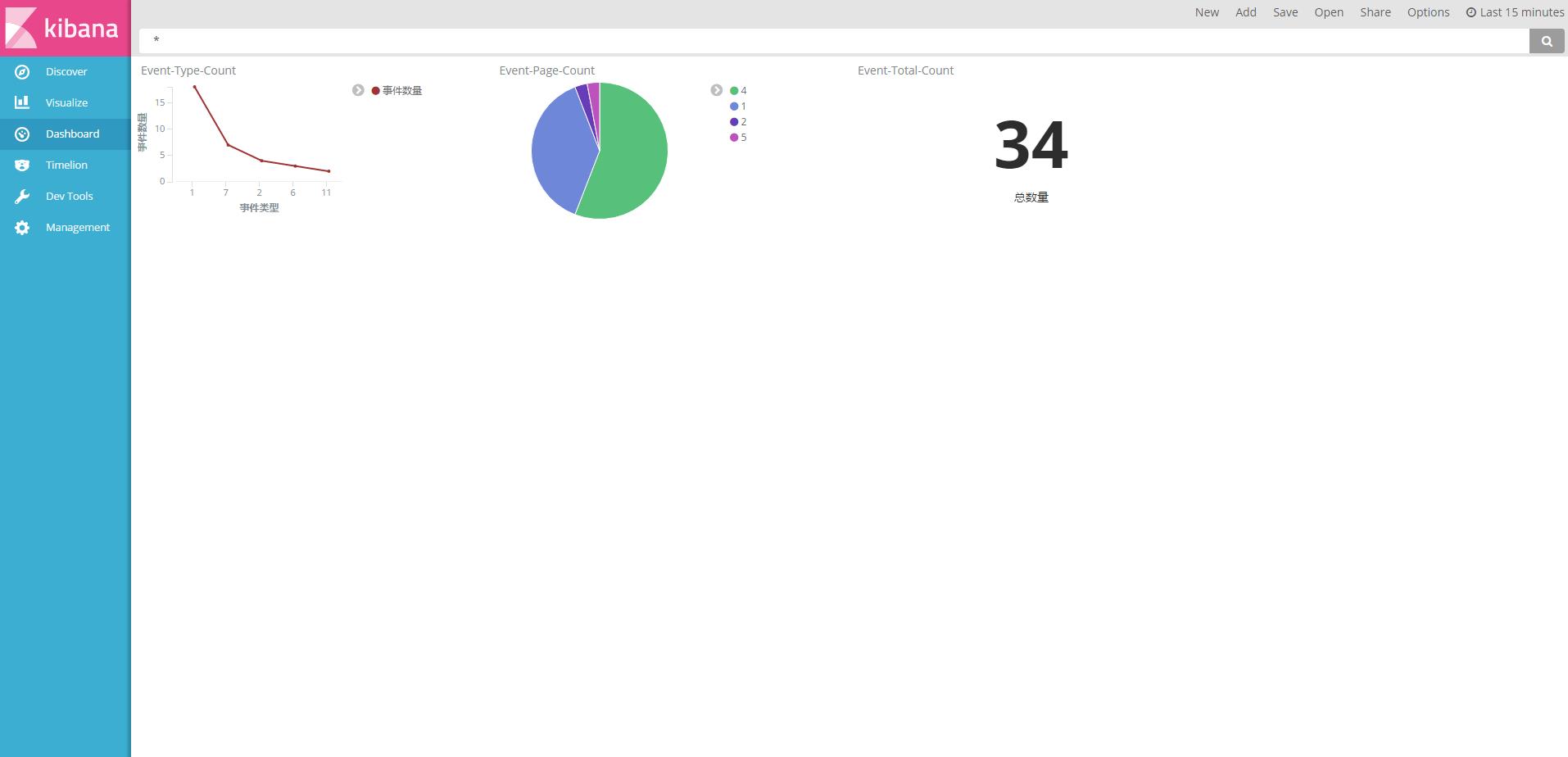
至此,ELK已经搭建完成,并提供一些简单的功能。 但是有一些统计Kibana是做不了的。这时候我们程序需要处理一下。
Java API
HandleEsClientServer
/* ES服务器列表 */
private String serverList; /* 设置client.transport.sniff为true来使客户端去嗅探整个集群的状态,把集群中其它机器的ip地址加到客户端中,它会自动帮你添加,并且自动发现新加入集群的机器 */
private Boolean sniff = false; /* 集群名称 */
private String clusterName; /* 连接客户端 */
private Client client; /* 搜索基本工具类 */
private SearchDao searchDao; public HandleEsClientServer() {
} public HandleEsClientServer(String serverList, Boolean sniff, String clusterName) { this.serverList = serverList; this.sniff = sniff; this.clusterName = clusterName;
} @Override
public void afterPropertiesSet() throws Exception {
logger.info("es server start at time={}, serverList={}, clusterName={}, sniff={}", DateUtil.toStr(new Date(),DateUtil.YYYY_MM_DD_HH_MM_SS),
serverList, clusterName, sniff); if (this.getServerList() == null || this.getServerList().length() == 0) {
logger.error("es serverList is null..."); return;
}
List clusterList = Splitter.on(",").trimResults().omitEmptyStrings().splitToList(this.getServerList());
List transportAddresses = new ArrayList<>(); for (String cluster : clusterList) {
List host = Splitter.on(":").trimResults().omitEmptyStrings().splitToList(cluster);
String ip = host.get(0);
Integer port = Integer.valueOf(host.get(1)); try {
transportAddresses.add(new InetSocketTransportAddress(InetAddress.getByAddress(getIpByte(ip)), port == null ? 9300 : port));
} catch (UnknownHostException e) {
logger.error("init es client error={} at time={} ", e, DateUtil.toStr(new Date(),DateUtil.YYYY_MM_DD_HH_MM_SS)); return;
}
} //配置启动参数
Settings settings = Settings.builder()
.put("cluster.name", clusterName)
.put("client.transport.sniff", sniff)
.build(); //初始化Client
this.client = new PreBuiltTransportClient(settings)
.addTransportAddresses(transportAddresses.toArray(new TransportAddress[transportAddresses.size()])); this.searchDao = new SearchDao(this.client);
logger.info("es server start success at time={}", DateUtil.toStr(new Date(),DateUtil.YYYY_MM_DD_HH_MM_SS));
}HandleEsData
/**
* 根据elasticsearch-sql插件的sql语句查询结果。
* @param query
* @return
* @throws SqlParseException
* @throws SQLFeatureNotSupportedException
*/
public SqlResponse selectBySQL(String query) throws SqlParseException, SQLFeatureNotSupportedException {
logger.info("selectBySQL, query={}",query); try{
SqlElasticSearchRequestBuilder select = (SqlElasticSearchRequestBuilder) searchDao.explain(query).explain(); return new SqlResponse((SearchResponse)select.get());
}catch (Exception e){
logger.error(e.getMessage(),e);
} return null;
}/**
* 批量插入数据,使用Obj的id字段。
* @param _index
* @param _type
* @param data
* @param generate_id
* @param
* @return
*/
public BulkResponse batchObjIndex(String _index, String _type, List data, boolean generate_id){
logger.info("batchObjIndex, index={}, type={}, data={}, generate_id={}", _index, _type, data, generate_id);
Assert.notEmpty(data, "data is not allowed empty");
BulkRequestBuilder bulkRequest = client.prepareBulk(); for (T tObj : data) {
Class clazz = tObj.getClass();
String json = JSONObject.toJSONString(tObj, SerializerFeature.WriteMapNullValue); if(generate_id){
bulkRequest.add(client.prepareIndex(_index.toLowerCase(), _type.toLowerCase()).setSource(json));
} else { try {
Object value = clazz.getDeclaredMethod("getId").invoke(tObj);
String _id = String.valueOf(value);
bulkRequest.add(client.prepareIndex(_index.toLowerCase(), _type.toLowerCase(), _id).setSource(json));
} catch (Exception e) {
logger.error(e.getMessage(),e);
}
}
} return bulkRequest.execute().actionGet();
}参考资料:
http://www.learnes.net/
http://udn.yyuap.com/doc/logstash-best-practice-cn/
https://www.gitbook.com/book/chenryn/elk-stack-guide-cn/details
https://www.elastic.co/guide/en/elasticsearch/reference/5.1/getting-started.html
https://www.elastic.co/guide/en/logstash/5.1/getting-started-with-logstash.html
https://www.elastic.co/guide/en/kibana/5.1/getting-started.html
http://elasticsearch.cn/
网易云免费体验馆,0成本体验20+款云产品!
更多网易研发、产品、运营经验分享请访问网易云社区。
相关文章:
【推荐】 从互联网+角度看云计算的现状与未来
以上是关于收集分析线上日志数据实战——ELK的主要内容,如果未能解决你的问题,请参考以下文章