OCR项目实战:手写汉语拼音识别(Pytorch版)
Posted GoAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OCR项目实战:手写汉语拼音识别(Pytorch版)相关的知识,希望对你有一定的参考价值。
👨💻作者简介: 大数据专业硕士在读,CSDN人工智能领域博客专家,阿里云专家博主,专注大数据与人工智能知识分享。
🎉专栏推荐: 目前在写一个CV方向专栏,后期会更新不限于目标检测、OCR、图像分类、图像分割等方向,目前活动仅19.9,虽然付费但会长期更新且价格便宜,感兴趣的小伙伴可以关注下,有擅长CV的大佬可以联系我合作一起写。➡️专栏地址
🎉学习者福利: 强烈推荐一个优秀AI学习网站,包括机器学习、深度学习等理论与实战教程,非常适合AI学习者。➡️网站链接。
🎉公众号: GoAI的学习小屋,免费分享书籍、简历、导图等资料,更有学习交流群分享AI和大数据资料,方式见文末或主页左侧扫码或私信皆可。
📝OCR专栏导读: 本系列主要介绍计算机视觉领域OCR文字识别领域技术发展方向,每章将分别从OCR技术发展、概念、算法、论文、数据集、现有平台及未来发展方向等各种角度展开详细介绍,综合基础与实战知识。以下是本系列目录,内容目前包括不限于文字检测、识别、表格分析等方向,未来会结合更新NLP方向知识,主要面向深度学习及CV的同学学习,如有错误请大家在评论区指正,如有侵权联系删除。 [ 欢迎添加评论区交流群,群内将分享更多大数据与人工智能方向资料。]
📝OCR入门教程系列目录:
1️⃣OCR系列第一章 【OCR技术导论】:OCR文字识别技术总结(一) [试读]
2️⃣OCR系列第二章 【OCR基础介绍】:OCR文字识别技术总结(二)
3️⃣OCR系列第三章 【文字检测技术】:OCR文字识别技术总结(三)
4️⃣OCR系列第四章 【文字识别技术】:OCR文字识别技术总结(四)
5️⃣OCR系列第五章 【实战代码解析】:OCR文字识别技术总结(五)
6️⃣OCR系列文章【OCR数据集与评价指标详解】(待更新)
7️⃣OCR系列文章【OCR后处理:文本纠错】(待更新)
8️⃣OCR系列文章 【OCR后处理:版面分析】(待更新)
9️⃣OCR系列文章 【表格识别】(待更新)
🔟OCR系列文章 【关键信息抽取】(待更新)
🆙OCR系列文章 【OCR资料总结】(待更新)
注:以上系列将继续更新及完善,非最终版本!后续更新内容包括不限于文字检测、文件识别、表格识别、版面分析、纠错及结构化、部署及实战等方面内容,欢迎大家订阅该专栏!
📝OCR领域经典论文汇总:
1️⃣OCR文字识别经典论文详解 [试读]
2️⃣OCR文字识别方法综述
3️⃣场景识别文字识别综述(待更新)
4️⃣文字检测方法综述(待更新)
📝OCR领域论文详解系列:
1️⃣CRNN:CRNN文字识别 [试读]
2️⃣ASTER:ASTER文本识别详解
🆙目前在整理阶段,后续会更新其他文字检测与识别方向论文解读。
📝OCR项目实战系列:
1️⃣Pyotch、TensoFlow
2️⃣PaddleOCR
- 基于CRNN的文本字符交易验证码识别
- 车牌检测与识别
- 体检报告识别
- 中文场景文字识别
- 手写汉语拼音识别(已更新)
- 手写英文识别(待更新)
- 票据识别(待更新)
- 公式识别(待更新)
- 表格识别(待更新)
…
注:更多实战项目敬请期待,详细介绍可以参考本系列其他文章,每个系列对应部分会陆续更新,欢迎大家交流订阅!!
OCR项目实战(一):手写汉语拼音识别
引言:汉语拼音识别存在人工识别慢,效率低下而且容易识别出错在批阅小学生试卷时带来很大困难。此外汉语拼音是中国小学生启蒙教育的重要一环,因此手写汉语拼音的识别具有很高的研究价值。人工识别手写汉语拼音已经难以满足社会需求,所以需要加快手写汉语拼音识别的数字化和信息化,通过科技手段来推动手写汉语拼音识别工作。
一、项目介绍:
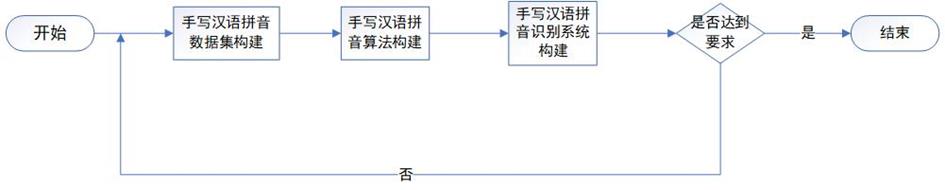
本项目基于深度学习的手写汉语拼音识别方法研究与实现。项目采用Pytorch框架,整体采用主流深度学习文字识别算法CRNN+CTC方法,项目流程主要分为数据集采集及标注,算法构建、模型训练、预测与评估等。
后续会补充PaddleOCR版本的手写汉语拼音识别,将引入更多模型测试,并结合数据增强手段提升模型泛化性。
1.项目链接:
https://github.com/GoAlers/Pinyin_recognize 正在整理,后续会补充!
2.项目大致流程:
1.首先将制作好的图片放入data目录下,图片名按具体写的拼音命名,格式jpg。
2.执行pic_to_txt.py文件,生成all_pic.txt,内容需要包含图片路径名+拼音,空格分割。
3.运行split.py数据集脚本将图片总数量按9:1比例 (将all_pic.txt分别生成train.txt 和test.txt)
4.将txt格式转为lmdb格式数据集执行create_lmdb,得到train和testd lmdb文件夹,将两个路径替换main.py里的训练及测试路径。
5.运行train.py训练,跑一定时间将模型保存运行demo进行测试。
二、数据集构建:
本项目采用手写汉语拼音数据集,通过随机生成500个不同的汉语拼音,并将汉语拼音分配给尽量多的人在A4纸上进行书写,以此来保证手写汉语拼音的字迹的多样化。对500个手写汉语拼音进行图像采集,使用人工对拼音进行对应标注。数据集也可以通过Python脚本生成,考虑到脚本自动生成如果没有经过一定规则过滤,可能存在语法错误,因此,本文最终采取人工拍照的方式进行数据集构建,由于时间限制,本项目仅制作500张手写拼音图片,后续可以增加更多数据集增加模型泛化能力。

三、数据集标注:
首先将收集的手写汉语拼音图片进行重命名,进行标签式标注,完成数据集的初步构建,用于进行后续的模型测练。对数据集按9:1比例进行划分。共制作500张手写拼音图片,随机选取 50个图片作为测试集,以此来测试所构建的算法对手写汉语拼音识别的准确率。另外450个图片则作为训练集,为算法构建后的神经网络进行训练,最终数据集预览如图所示。

数据集格式:
路径 标注信息 (注:以 ‘\\t’ 分割,路径按自己实际情况写)
D:\\Python\\PycharmProjects\\CRNN\\ATT_PY\\data\\bàocháng.png bàocháng
D:\\Python\\PycharmProjects\\CRNN\\ATT_PY\\data\\diànnǎo.png diànnǎo
D:\\Python\\PycharmProjects\\CRNN\\ATT_PY\\data\\guòyǐn.png guòyǐn
D:\\Python\\PycharmProjects\\CRNN\\ATT_PY\\data\\húshōuzhàn.png húshōuzhàn
D:\\Python\\PycharmProjects\\CRNN\\ATT_PY\\data\\kǒngpà.png kǒngpà
D:\\Python\\PycharmProjects\\CRNN\\ATT_PY\\data\\péiyǎng.png péiyǎng
D:\\Python\\PycharmProjects\\CRNN\\ATT_PY\\data\\qǔdāo.png qǔdāo
D:\\Python\\PycharmProjects\\CRNN\\ATT_PY\\data\\tiānnèi.png tiānnèi
四、技术介绍
本项目构建手写汉语拼音识别算法:本文手写汉语拼音识别算法采用序列到序列的识别方法CRNN+Attenton,CRNN主要用来对端到端的不定长文本序列加以识别,采用的汉语拼音识别算法分为编码网络和解码网络两个部分。首先,编码网络的主体框架采用卷积神经网络,骨干网络使用Resnet,语言模型使用BiLSTM。其次,解码网络的核心部分由LSTM结合注意力机制实现,其过程根据LSTM每个时刻输入项进行注意力分值计算并加权求和。最后,将上述得分通过Softmax进行多分类处理,得到最终汉语拼音分类结果。通过仿真实验,调整网络结构以及配置参数,最终手写汉语拼音识别精度可以达到92%以上。
五、算法介绍及构建
1.1CRNN算法
官方论文:An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition
参考代码:https://github.com/meijieru/crnn.pytorch
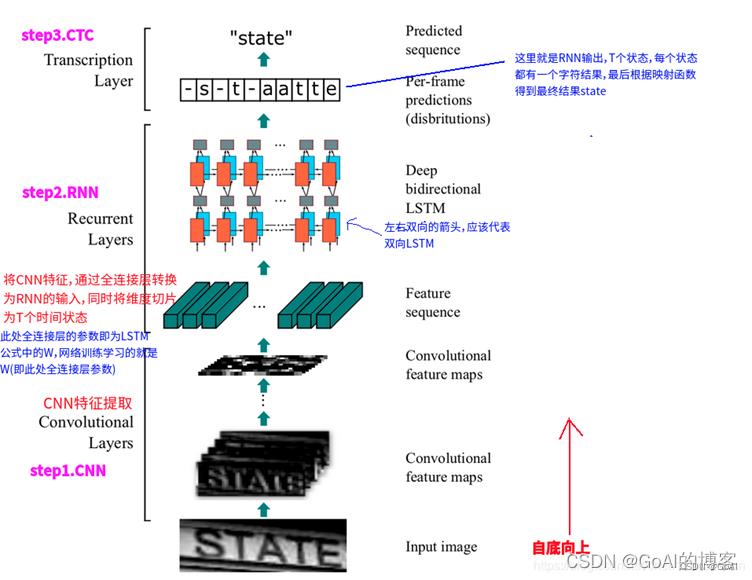
CRNN的全名为Convolutional Recurrent Neural Network,主要是被设计用来对端到端的长宽度不确定的长文本序列加以识别。它就可以实现不用先去对其他任何一类单个的图像文字序列识别进行切割,而是借助将单个的图形文字序列的辨识学习步骤依次转变为一类由时间序列的依赖图形文本序列的辨识的学习过程的问题,进行更高效地基适应于用单一的图像文字序列实现的所有图像文本序列的标识。
CRNN借鉴采用了语音识别建模理论框架中最为常用的一种LSTM+CTC网络的声音建模分析技术方法,输入接收到的从LSTM所提取得到的声音特征,不再意味着完全可以是当前语音领域所常用到的各种声学特征,而是一种由CNN网络中所无法提取到声音的图像特征。CRNN网络实现结合CNN和RNN网络结构,其结构如图3.5所示:
1.1.1.CRNN+CTC
算法网络结构
六、代码实战

train.py
# encoding: utf-8
from __future__ import print_function
from __future__ import division
import argparse
import random
import torch
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
from torch.autograd import Variable
import numpy as np
#from warpctc_pytorch import CTCLoss
import os
import utils as utils1
import dataset
import hypy_alphabet
import models.crnn as crnn
parser = argparse.ArgumentParser()
parser.add_argument('--trainRoot', default = r'../ATT_PY/train502', help='path to dataset')
parser.add_argument('--valRoot', default = r'../ATT_PY/test502', help='path to dataset')
parser.add_argument('--workers', type=int, help='number of demo_data loading workers', default=0)
parser.add_argument('--batchSize', type=int, default=4, help='input batch size')
parser.add_argument('--imgH', type=int, default=32, help='the height of the input image to network')
parser.add_argument('--imgW', type=int, default=300, help='the width of the input image to network')
parser.add_argument('--nh', type=int, default=256, help='size of the lstm hidden state')
parser.add_argument('--nepoch', type=int, default=200, help='number of epochs to sxmv for') #迭代次数
# TODO(meijieru): epoch -> iter
parser.add_argument('--cuda',default=True, action='store_true', help='enables cuda') #有GPU时--cuda,另加了default=True
parser.add_argument('--ngpu', type=int, default=1, help='number of GPUs to use')
# parser.add_argument('--pretrained', default='', help="path to pretrained model (to continue training)") #预训练模型,可以设置断
#parser.add_argument('--pretrained', default=r'./exprpy/netCRNN_188_73.pth', help="path to pretrained model (to continue training)")
# parser.add_argument('--alphabet', type=str, default='-1234abcdefghijklmnopqrstuvwxyz')
parser.add_argument('--alphabet', type=str, default='abcdefghijklmnopqrstuvwxyzāáǎàōóǒòēéěèīíǐìūúǔùǖǘǚǜ')
parser.add_argument('--expr_dir', default='exprpy', help='Where to store samples and models') #输出模型路径
parser.add_argument('--displayInterval', type=int, default=10, help='Interval to be displayed')
parser.add_argument('--n_test_disp', type=int, default=10, help='Number of samples to display when test')
parser.add_argument('--valInterval', type=int, default=119, help='Interval to be displayed') #一轮保留一次模型
parser.add_argument('--saveInterval', type=int, default=119, help='Interval to be displayed') #设置多少次迭代保存一次模型
parser.add_argument('--lr', type=float, default=0.0001, help='learning rate for Critic, not used by adadealta')
parser.add_argument('--beta1', type=float, default=0.5, help='beta1 for adam. default=0.5')
# 以下为两个优化器 ,可以选 ,其中下一行设置default=True,等于默认执行文件时加 --adam
parser.add_argument('--adam', default=True, help='Whether to use adam (default is rmsprop)')
parser.add_argument('--adadelta', action='store_true', help='Whether to use adadelta (default is rmsprop)')
parser.add_argument('--keep_ratio', action='store_true', help='whether to keep ratio for image resize')
parser.add_argument('--manualSeed', type=int, default=1234, help='reproduce experiemnt')
parser.add_argument('--random_sample', action='store_true', default=True, help='whether to sample the dataset with random sampler')
#以上参数可以通过opt.名字访问
opt = parser.parse_args()
#输出各参数内容
print(opt)
# opt.alphabet = hypy_alphabet.alphabet()
# print(opt.alphabet)
if not os.path.exists(opt.expr_dir):
os.makedirs(opt.expr_dir)
random.seed(opt.manualSeed)
np.random.seed(opt.manualSeed)
torch.manual_seed(opt.manualSeed)
cudnn.benchmark = True
if torch.cuda.is_available() and not opt.cuda:
print("WARNING: You have a CUDA device, so you should probably run with --cuda")
train_dataset = dataset.lmdbDataset(root=opt.trainRoot)
assert train_dataset
#设置随机采样
if not opt.random_sample:
sampler = dataset.randomSequentialSampler(train_dataset, opt.batchSize)
else:
sampler = None
#加载训练及测试集
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=opt.batchSize,
shuffle=True, sampler=sampler,
num_workers=int(opt.workers),
collate_fn=dataset.alignCollate(imgH=opt.imgH, imgW=opt.imgW, keep_ratio=opt.keep_ratio))
test_dataset = dataset.lmdbDataset(
root=opt.valRoot, transform=dataset.resizeNormalize((opt.imgW, 32)))
#分类含空格+Mathorcuo_final
nclass = len(opt.alphabet) + 1
nc = 1
converter = utils1.strLabelConverter(opt.alphabet)
criterion = torch.nn.CTCLoss()
# custom weights initialization called on crnn
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
crnn = crnn.CRNN(opt.imgH, nc, nclass, opt.nh)
crnn.apply(weights_init)
#加载预训练
if opt.pretrained != '':
print('loading pretrained model from %s' % opt.pretrained)
# crnn.load_state_dict(torch.load(opt.pretrained)) #预训练模型出现参数报错,将本行改为下列代码执行成功
crnn.load_state_dict(k.replace('module.', ''): v for k, v in torch.load(opt.pretrained).items())
# print(crnn)
image = torch.FloatTensor(opt.batchSize, 3, opt.imgH, opt.imgH)
text = torch.IntTensor(opt.batchSize * 5)
length = torch.IntTensor(opt.batchSize)
if opt.cuda:
crnn.cuda()
# 迭代次数或者epoch足够大的时候,我们通常会使用nn.DataParallel函数来用多个GPU来加速训练
crnn = torch.nn.DataParallel(crnn, device_ids=range(opt.ngpu))
image = image.cuda()
criterion = criterion.cuda()
image = Variable(image)
# print(image)
text = Variable(text)
# print(text)
length = Variable(length)
# print(length)
# loss averager
loss_avg = utils1.averager()
# 两种优化器参数设置setup optimizer
if opt.adam:
optimizer = optim.Adam(crnn.parameters(), lr=opt.lr,
betas=(opt.beta1, 0.999))
elif opt.adadelta:
optimizer = optim.Adadelta(crnn.parameters())
else:
optimizer = optim.RMSprop(crnn.parameters(), lr=opt.lr)
def val(net, dataset, criterion, max_iter=100):
print('Start val')
for p in crnn.parameters():
p.requires_grad = False
net.eval()
data_loader = torch.utils.data.DataLoader(
dataset, shuffle=True, batch_size=opt.batchSize, num_workers=int(opt.workers))
val_iter = iter(data_loader)
i = 0
n_correct = 0
loss_avg = utils1.averager()
max_iter = min(max_iter, len(data_loader))
for i in range(max_iter):
data = val_iter.next()
i += 1
cpu_images, cpu_texts = data
batch_size = cpu_images.size(0)
utils1.loadData(image, cpu_images)
t,l = converter.encode(cpu_texts)
utils1.loadData(text, t)
utils1.loadData(length, l)
preds = crnn(image)
preds_size = Variable(torch.IntTensor([preds.size(0)] * batch_size))
cost = criterion(preds, text, preds_size, length) / batch_size
loss_avg.add(cost)
_, preds = preds.max(2)
# print(preds.size())
# preds = preds.squeeze(2)
preds = preds.transpose(1, 0).contiguous().view(-1)
sim_preds = converter.decode(preds.data, preds_size.data, raw=False)
for pred, target in zip(sim_preds, cpu_texts):
if pred == target.lower():
n_correct += 1
raw_preds = converter.decode(preds.data, preds_size.data, raw=True)[:opt.n_test_disp]
for raw_pred, pred, gt in zip(raw_preds, sim_preds, cpu_texts):
print('%-20s => %-20s, gt: %-20s' % (raw_pred, pred, gt))
accuracy = n_correct / float(max_iter * opt.batchSize)
print('Test loss: %f, accuray: %f' % (loss_avg.val(), accuracy))
def trainBatch(net, criterion, optimizer):
data = train_iter.next()
cpu_images, cpu_texts = data
batch_size = cpu_images.size(0)
utils1.loadData(image, cpu_images)
t, l = converter.encode(cpu_texts)
utils1.loadData(text, t)
utils1.loadData(length, l)
preds = crnn(image)
preds_size = Variable(torch.IntTensor([preds.size(0)] * batch_size))
# print(preds.shape)
# print(text.shape)
# print(text.demo_data, length.demo_data)
cost = criterion(preds, text, preds_size, length) / batch_size
crnn.zero_grad()
cost.backward()
optimizer.step()
return cost
for epoch in range(opt.nepoch):
train_iter = iter(train_loader)
i = 0
while i < len(train_loader):
for p in crnn.parameters():
p.requires_grad = True
crnn.train()
cost = trainBatch(crnn, criterion, optimizer)
loss_avg.add(cost)
i += 1
#设置保留模型频率,可以设置每次保留最优模型。
if i % opt.displayInterval == 0:
print('[%d/%d][%d/%d] Loss: %f' %
(epoch, opt.nepoch, i, len(train_loader), loss_avg.val()))
loss_avg.reset()
if i % opt.valInterval == 0:
val(crnn, test_dataset, criterion)
# do checkpointing
if i % opt.saveInterval == 0:
torch.save(
crnn.state_dict