中文文本分类大概的步骤
Posted sss-justddoit
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文文本分类大概的步骤相关的知识,希望对你有一定的参考价值。
文本分类问题:给定文档p(可能含有标题t),将文档分类为n个类别中的一个或多个
文本分类应用:常见的有垃圾邮件识别,情感分析
文本分类方向:主要有二分类,多分类,多标签分类
文本分类方法:传统机器学习方法(贝叶斯,svm等),深度学习方法(fastText,TextCNN等)
文本分类的处理大致分为文本预处理、文本特征提取、分类模型构建等。和英文文本处理分类相比,中文文本的预处理是关键技术。
一、中文分词:针对中文文本分类时,很关键的一个技术就是中文分词。特征粒度为词粒度远远好于字粒度,其大部分分类算法不考虑词序信息,基于字粒度的损失了过多的n-gram信息。下面简单总结一下中文分词技术:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。具体可参考:中文分词原理及分词工具介绍https://blog.csdn.net/flysky1991/article/details/73948971/
1,基于字符串匹配的分词方法:
过程:这是一种基于词典的中文分词,核心是首先建立统一的词典表,当需要对一个句子进行分词时,首先将句子拆分成多个部分,将每一个部分与字典一一对应,如果该词语在词典中,分词成功,否则继续拆分匹配直到成功。
核心: 字典,切分规则和匹配顺序是核心。
分析:优点是速度快,时间复杂度可以保持在O(n),实现简单,效果尚可;但对歧义和未登录词处理效果不佳。
2,基于理解的分词方法:
基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
3,基于统计的分词方法:
过程:统计学认为分词是一个概率最大化问题,即拆分句子,基于语料库,统计相邻的字组成的词语出现的概率,相邻的词出现的次数多,就出现的概率大,按照概率值进行分词,所以一个完整的语料库很重要。
主要的统计模型有: N元文法模型(N-gram),隐马尔可夫模型(Hidden Markov Model ,HMM),最大熵模型(ME),条件随机场模型(Conditional Random Fields,CRF)等。
二、文本预处理:
1,分词:中文任务分词必不可少,一般使用jieba分词,工业界的翘楚。
2,去停用词:建立停用词字典,目前停用词字典有2000个左右,停用词主要包括一些副词、形容词及其一些连接词。通过维护一个停用词表,实际上是一个特征提取的过程,本质 上是特征选择的一部分。
3,词性标注:在分词后判断词性(动词、名词、形容词、副词…),在使用jieba分词的时候设置参数就能获取。
三、文本特征工程:文本分类的核心都是如何从文本中抽取出能够体现文本特点的关键特征,抓取特征到类别之间的映射。所以特征工程很重要,可以由四部分组成:
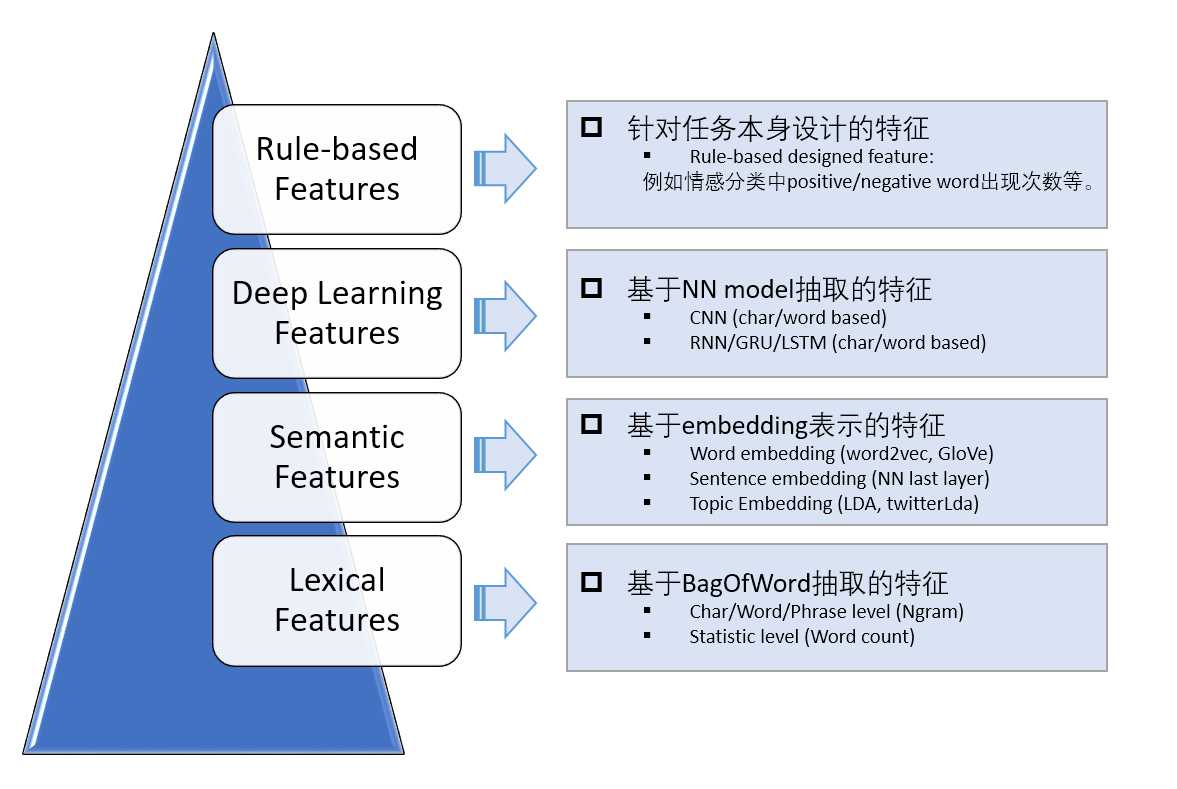
1,基于词袋模型的特征表示:以词为单位(Unigram)构建的词袋可能就达到几万维,如果考虑二元词组(Bigram)、三元词组(Trigram)的话词袋大小可能会有几十万之多,因此基于词袋模型的特征表示通常是极其稀疏的。
(1)词袋特征的方法有三种:
Naive版本:不考虑词出现的频率,只要出现过就在相应的位置标1,否则为0;
考虑词频(即term frequency):,认为一段文本中出现越多的词越重要,因此权重也越大;
考虑词的重要性:以TF-IDF表征一个词的重要程度。TF-IDF反映了一种折中的思想:即在一篇文档中,TF认为一个词出现的次数越大可能越重要,但也可能并不是(比如停用词:“的”“是”之类的);IDF认为一个词出现在的文档数越少越重要,但也可能不是(比如一些无意义的生僻词)。
(2)优缺点:
优点:词袋模型比较简单直观,它通常能学习出一些关键词和类别之间的映射关系
缺点:丢失了文本中词出现的先后顺序信息;仅将词语符号化,没有考虑词之间的语义联系(比如,“麦克风”和“话筒”是不同的词,但是语义是相同的);
2,基于embedding的特征表示:通过词向量计算文本的特征。(主要针对短文本)
取平均:取短文本的各个词向量之和(或者取平均)作为文本的向量表示;
网络特征:用一个pre-train好的NN model得到文本作为输入的最后一层向量表示;
3,基于NN Model抽取的特征: NN的好处在于能end2end实现模型的训练和测试,利用模型的非线性和众多参数来学习特征,而不需要手工提取特征。CNN善于捕捉文本中关键的局部信息,而RNN则善于捕捉文本的上下文信息(考虑语序信息),并且有一定的记忆能力。
4,基于任务本身抽取的特征:主要是针对具体任务而设计的,通过我们对数据的观察和感知,也许能够发现一些可能有用的特征。有时候,这些手工特征对最后的分类效果提升很大。举个例子,比如对于正负面评论分类任务,对于负面评论,包含负面词的数量就是一维很强的特征。
5,特征融合:对于特征维数较高、数据模式复杂的情况,建议用非线性模型(如比较流行的GDBT, XGBoost);对于特征维数较低、数据模式简单的情况,建议用简单的线性模型即可(如LR)。
6,主题特征:
LDA(文档的话题):可以假设文档集有T个话题,一篇文档可能属于一个或多个话题,通过LDA模型可以计算出文档属于某个话题的概率,这样可以计算出一个DxT的矩阵。LDA特征在文档打标签等任务上表现很好。
LSI(文档的潜在语义):通过分解文档-词频矩阵来计算文档的潜在语义,和LDA有一点相似,都是文档的潜在特征。
四、文本分类,传统机器学习方法:这部分不是重点,传统机器学习算法中能用来分类的模型都可以用,常见的有:NB模型,随机森林模型(RF),SVM分类模型,KNN分类模型,神经网络分类模型。
这里重点提一下贝叶斯模型,因为工业用这个模型用来识别垃圾邮件,具体参考:用朴素贝叶斯进行文本分类https://blog.csdn.net/longxinchen_ml/article/details/50597149
五、深度学习文本分类模型:
1,fastText模型:fastText 是word2vec 作者 Mikolov 转战 Facebook 后16年7月刚发表的一篇论文: Bag of Tricks for Efficient Text Classification。
模型:
原理:句子中所有的词向量进行平均(某种意义上可以理解为只有一个avg pooling特殊CNN),然后直接接 softmax 层。
2,TextCNN:利用CNN来提取句子中类似 n-gram 的关键信息。
模型:
改进: fastText 中的网络结果是完全没有考虑词序信息的,而TextCNN提取句子中类似 n-gram 的关键信息。
3,TextRNN:
模型: Bi-directional RNN(实际使用的是双向LSTM)从某种意义上可以理解为可以捕获变长且双向的的 “n-gram” 信息。
改进: CNN有个最大问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节也很繁琐。
4,TextRNN + Attention:
模型:
改进:注意力(Attention)机制是自然语言处理领域一个常用的建模长时间记忆机制,能够很直观的给出每个词对结果的贡献,基本成了Seq2Seq模型的标配了。实际上文本分类从某种意义上也可以理解为一种特殊的Seq2Seq,所以考虑把Attention机制引入近来。
5,TextRCNN(TextRNN + CNN):
模型:
论文: Recurrent Convolutional Neural Networks for Text Classification
6,深度学习经验:
模型显然并不是最重要的:好的模型设计对拿到好结果的至关重要,也更是学术关注热点。但实际使用中,模型的工作量占的时间其实相对比较少。虽然再第二部分介绍了5种CNN/RNN及其变体的模型,实际中文本分类任务单纯用CNN已经足以取得很不错的结果了,我们的实验测试RCNN对准确率提升大约1%,并不是十分的显著。最佳实践是先用TextCNN模型把整体任务效果调试到最好,再尝试改进模型。
理解你的数据:虽然应用深度学习有一个很大的优势是不再需要繁琐低效的人工特征工程,然而如果你只是把他当做一个黑盒,难免会经常怀疑人生。一定要理解你的数据,记住无论传统方法还是深度学习方法,数据 sense 始终非常重要。要重视 badcase 分析,明白你的数据是否适合,为什么对为什么错。
超参调节:可以参考深度学习网络调参技巧 - 知乎专栏https://zhuanlan.zhihu.com/p/24720954?utm_source=zhihu&utm_medium=social
一定要用 dropout:有两种情况可以不用:数据量特别小,或者你用了更好的正则方法,比如bn。实际中我们尝试了不同参数的dropout,最好的还是0.5,所以如果你的计算资源很有限,默认0.5是一个很好的选择。
未必一定要 softmax loss: 这取决与你的数据,如果你的任务是多个类别间非互斥,可以试试着训练多个二分类器,也就是把问题定义为multi lable 而非 multi class,我们调整后准确率还是增加了>1%。
类目不均衡问题:基本是一个在很多场景都验证过的结论:如果你的loss被一部分类别dominate,对总体而言大多是负向的。建议可以尝试类似 booststrap 方法调整 loss 中样本权重方式解决。
避免训练震荡:默认一定要增加随机采样因素尽可能使得数据分布iid,默认shuffle机制能使得训练结果更稳定。如果训练模型仍然很震荡,可以考虑调整学习率或 mini_batch_size。
---------------------
原文:https://blog.csdn.net/u014248127/article/details/80774668?utm_source=copy
以上是关于中文文本分类大概的步骤的主要内容,如果未能解决你的问题,请参考以下文章
BERT-多标签文本分类实战之三——多标签文本分类的方向与常用数据集介绍
BERT-多标签文本分类实战之三——多标签文本分类的方向与常用数据集介绍