flask
Posted yanxiatingyu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flask相关的知识,希望对你有一定的参考价值。
Flask
- 一个短小精悍、可扩展的一个Web框架
很多可用的第三方组件:http://flask.pocoo.org/extensions/
blogs:https://www.cnblogs.com/wupeiqi/articles/7552008.html
- 依赖于wsgi[Werkzurg] (django 也依赖 Tornado 貌似不依赖)
[什么是wsgi?]
百度百科:https://baike.baidu.com/item/wsgi/3381529?fr=aladdin
WSGI接口:https://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001386832689740b04430a98f614b6da89da2157ea3efe2000
安装: pip install flask
from flask import Flask
app=Flask(__name__)#给对象起个名字
print(__name__)
app.secret_key="用session之前需要加盐,这里的session其实就是存放在cookies 中的"
[ 关于__name__
1、__name__这个系统变量显示了当前模块执行过程中的名称,如果当前程序运行在这个模块中,__name__的名称就是__main__如果不是,则为这个模块的名称。
2、__main__一般作为函数的入口,类似于C语言,尤其在大型工程中,常常有if __name__ == "__main__":来表明整个工程开始运行的入口。 本文来自 IAMoldpan 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/iamoldpan/article/details/78077983?utm_source=copy ]
@app.route(‘/home‘,methods=["GET","POST"])#默认开启get,post 没有开启
def home():
return ‘你妹‘
if __name__ == ‘__main__‘:
app.run()
class Flask:
def __init__(
self,
import_name,
static_url_path=None, #静态文件夹前缀 别名 <img src="/static/mr.jpg">
修改static_url_path=‘ccc‘ <img src="/cccc/.jpg" > static_folder=‘static‘不变
static_folder=‘static‘, #静态文件默认地址
static_host=None,
host_matching=False,
subdomain_matching=False,
template_folder=‘templates‘,#模板文件 默认存放地址
instance_path=None,
instance_relative_config=False,
root_path=None
):
配置文件:
路由系统:
视 图:
请求相关:
响 应:
模板渲染:
session:
闪 现:
中 间件:
蓝 图:(blueprint)目录结构划分
特殊的装饰器:类似于django的中间件
app.secret_key="用session之前需要加盐,这里的session其实就是存放在cookies 中的"
dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;
带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。
如果参数不包含__dir__(),该方法将最大限度地收集参数信息。
getattr() 函数用于返回一个对象属性值。
import importlib
path="settings.Foo"
p,c = path.rsplit(‘.‘,maxsplit=1)
m = importlib.import_module(p)
cls = getattr(m,c)
#如何找到这个类?
for key in dir(cls):
if key.isupper():
print(key,getattr(cls,key))
from datetime import timedelta
app.config
{‘APPLICATION_ROOT‘: ‘/‘,
‘DEBUG‘: False,
‘ENV‘: ‘production‘,
‘EXPLAIN_TEMPLATE_LOADING‘: False,
‘JSONIFY_MIMETYPE‘: ‘application/json‘,
‘JSONIFY_PRETTYPRINT_REGULAR‘: False,
‘JSON_AS_ASCII‘: True,
‘JSON_SORT_KEYS‘: True,
‘MAX_CONTENT_LENGTH‘: None,
‘MAX_COOKIE_SIZE‘: 4093,
‘PERMANENT_SESSION_LIFETIME‘: datetime.timedelta(31), #session 最大的保留时间 print(datetime.timedelta(31))>>31 days, 0:00:00
‘PREFERRED_URL_SCHEME‘: ‘http‘,
‘PRESERVE_CONTEXT_ON_EXCEPTION‘: None,
‘PROPAGATE_EXCEPTIONS‘: None,
‘SECRET_KEY‘: None,
‘SEND_FILE_MAX_AGE_DEFAULT‘: datetime.timedelta(0, 43200),
‘SERVER_NAME‘: None,
‘SESSION_COOKIE_DOMAIN‘: None, #域名
‘SESSION_COOKIE_HTTPONLY‘: True,
‘SESSION_COOKIE_NAME‘: ‘session‘, #session cookies中session的名称
‘SESSION_COOKIE_PATH‘: None, #路径
‘SESSION_COOKIE_SAMESITE‘: None, #
‘SESSION_COOKIE_SECURE‘: False, #安全性
‘SESSION_REFRESH_EACH_REQUEST‘: True, #最后一次访问 模式
‘TEMPLATES_AUTO_RELOAD‘: None,
‘TESTING‘: False,
‘TRAP_BAD_REQUEST_ERRORS‘: None,
‘TRAP_HTTP_EXCEPTIONS‘: False,
‘USE_X_SENDFILE‘: False}
settings.py
class Config(object):
DEBUG = False
TESTING = False
DATABASE_URI = ‘sqlite://memory:‘ ????????????
class ProductionConfig(Config):
DEBUG = True
class TestingConfig(Config):
TESTING =True
方式一
app.config.from_object("settings.ProductionConfig")#正式版 每个类配置各有不同, 这样可以来回切换
app.config.from_object("settings.DevelopmentConfig")#开发版
app.config.from_object("settings.TestingConfig")#测试版
通过在类里面定义属性的方式
方式二
app.config[‘DEBUG‘]=True
app.config.from_object(‘settings.class_name‘)
"""Updates the values from the given object. An object can be of one
of the following two types:
- a string: in this case the object with that name will be imported
- an actual object reference: that object is used directly
Objects are usually either modules or classes. :meth:`from_object`
loads only the uppercase attributes of the module/class. A ``dict``
object will not work with :meth:`from_object` because the keys of a
``dict`` are not attributes of the ``dict`` class.
Example of module-based configuration::
app.config.from_object(‘yourapplication.default_config‘)
from yourapplication import default_config
app.config.from_object(default_config)
You should not use this function to load the actual configuration but
rather configuration defaults. The actual config should be loaded
with :meth:`from_pyfile` and ideally from a location not within the
package because the package might be installed system wide.
See :ref:`config-dev-prod` for an example of class-based configuration
using :meth:`from_object`.
:param obj: an import name or object
"""
def from_object(self, obj):
if isinstance(obj, string_types):
obj = import_string(obj)
for key in dir(obj):
if key.isupper():
self[key] = getattr(obj, key)
[
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
]
路由系统
-endpoint,反向生成url,默认函数名[类似与django里面的name,根据名字反向解析]
-url_for(‘endpoint‘) 可以直接在另一个视图函数中直接url_for(endpoint_name) 进行反向解析
from flask import url_for
@app.route(‘/index‘,methods=[‘GET‘,‘POST‘],endpoint=‘n1‘)
def index():
print(url_for(‘n1‘))
return ‘index‘
动态路由
@app.route(‘/index/<int:nid>‘,methods=[‘GET‘,‘POST‘])
def index(nid):
url_for
return ‘那你妹‘
- @app.route(‘/user/<username>‘)
- @app.route(‘/post/<int:post_id>‘)
- @app.route(‘/post/<float:post_id>‘)
- @app.route(‘/post/<path:path>‘)
- @app.route(‘/login‘, methods=[‘GET‘, ‘POST‘])
常用路由系统有以上五种,所有的路由系统都是基于一下对应关系来处理:
7种转换器
DEFAULT_CONVERTERS = { ‘default‘: UnicodeConverter, ‘string‘: UnicodeConverter, ‘any‘: AnyConverter, ‘path‘: PathConverter, ‘int‘: IntegerConverter, ‘float‘: FloatConverter, ‘uuid‘: UUIDConverter,}
定义endpoint=name 直接url_for(name)
不定义 默认endpoint=函数名 直接url_for(function_name)
视图:
FBV
CBV
请求相关数据:
# 请求相关信息
# request.method #当前请求方式
# request.args #GET
# request.form #POST
# request.values
# request.cookies
# request.headers
# request.path #当前访问路径 ???
# request.full_path
# request.script_root
# request.url
# request.base_url
# request.url_root
# request.host_url
# request.host
# request.files #ImmutableMultiDict([(‘upload_file‘, <FileStorage: ‘QQ图片20180911115431.png‘ (‘image/png‘)>)])
# obj = request.files[‘the_file_name‘] #<FileStorage: ‘QQ图片20180911115431.png‘ (‘image/png‘)>
# obj.save(‘/var/www/uploads/‘ + secure_filename(f.filename))
//判断 请求 类型
if request.method == ‘GET‘:
print(‘GET‘)
else:
print(‘POST‘)
响应相关
form flask import jsonify #内部帮你序列化(类似与django里面的jsonResponse)
import json
返回值:
返回的都是响应体:
return "你妹"
return json.dumps(dic)
return render_template(‘index.html‘)
return redirect(‘‘)
如何 在定制响应头呢?
设置cookies
from flask import make_response
obj= make_response(jsonify({"test":‘消息‘}))
obj.headers[‘响应头内容‘]=‘哈哈哈‘
obj.set_cookie(‘key‘,‘value‘)
reurn obj


class BaseRequest(object): """Very basic request object. This does not implement advanced stuff like entity tag parsing or cache controls. The request object is created with the WSGI environment as first argument and will add itself to the WSGI environment as ``‘werkzeug.request‘`` unless it‘s created with `populate_request` set to False. There are a couple of mixins available that add additional functionality to the request object, there is also a class called `Request` which subclasses `BaseRequest` and all the important mixins. It‘s a good idea to create a custom subclass of the :class:`BaseRequest` and add missing functionality either via mixins or direct implementation. Here an example for such subclasses:: from werkzeug.wrappers import BaseRequest, ETagRequestMixin class Request(BaseRequest, ETagRequestMixin): pass Request objects are **read only**. As of 0.5 modifications are not allowed in any place. Unlike the lower level parsing functions the request object will use immutable objects everywhere possible. Per default the request object will assume all the text data is `utf-8` encoded. Please refer to `the unicode chapter <unicode.txt>`_ for more details about customizing the behavior. Per default the request object will be added to the WSGI environment as `werkzeug.request` to support the debugging system. If you don‘t want that, set `populate_request` to `False`. If `shallow` is `True` the environment is initialized as shallow object around the environ. Every operation that would modify the environ in any way (such as consuming form data) raises an exception unless the `shallow` attribute is explicitly set to `False`. This is useful for middlewares where you don‘t want to consume the form data by accident. A shallow request is not populated to the WSGI environment. .. versionchanged:: 0.5 read-only mode was enforced by using immutables classes for all data. """ #: the charset for the request, defaults to utf-8 charset = ‘utf-8‘ #: the error handling procedure for errors, defaults to ‘replace‘ encoding_errors = ‘replace‘ #: the maximum content length. This is forwarded to the form data #: parsing function (:func:`parse_form_data`). When set and the #: :attr:`form` or :attr:`files` attribute is accessed and the #: parsing fails because more than the specified value is transmitted #: a :exc:`~werkzeug.exceptions.RequestEntityTooLarge` exception is raised. #: #: Have a look at :ref:`dealing-with-request-data` for more details. #: #: .. versionadded:: 0.5 max_content_length = None #: the maximum form field size. This is forwarded to the form data #: parsing function (:func:`parse_form_data`). When set and the #: :attr:`form` or :attr:`files` attribute is accessed and the #: data in memory for post data is longer than the specified value a #: :exc:`~werkzeug.exceptions.RequestEntityTooLarge` exception is raised. #: #: Have a look at :ref:`dealing-with-request-data` for more details. #: #: .. versionadded:: 0.5 max_form_memory_size = None #: the class to use for `args` and `form`. The default is an #: :class:`~werkzeug.datastructures.ImmutableMultiDict` which supports #: multiple values per key. alternatively it makes sense to use an #: :class:`~werkzeug.datastructures.ImmutableOrderedMultiDict` which #: preserves order or a :class:`~werkzeug.datastructures.ImmutableDict` #: which is the fastest but only remembers the last key. It is also #: possible to use mutable structures, but this is not recommended. #: #: .. versionadded:: 0.6 parameter_storage_class = ImmutableMultiDict #: the type to be used for list values from the incoming WSGI environment. #: By default an :class:`~werkzeug.datastructures.ImmutableList` is used #: (for example for :attr:`access_list`). #: #: .. versionadded:: 0.6 list_storage_class = ImmutableList #: the type to be used for dict values from the incoming WSGI environment. #: By default an #: :class:`~werkzeug.datastructures.ImmutableTypeConversionDict` is used #: (for example for :attr:`cookies`). #: #: .. versionadded:: 0.6 dict_storage_class = ImmutableTypeConversionDict #: The form data parser that shoud be used. Can be replaced to customize #: the form date parsing. form_data_parser_class = FormDataParser #: Optionally a list of hosts that is trusted by this request. By default #: all hosts are trusted which means that whatever the client sends the #: host is will be accepted. #: #: This is the recommended setup as a webserver should manually be set up #: to only route correct hosts to the application, and remove the #: `X-Forwarded-Host` header if it is not being used (see #: :func:`werkzeug.wsgi.get_host`). #: #: .. versionadded:: 0.9 trusted_hosts = None #: Indicates whether the data descriptor should be allowed to read and #: buffer up the input stream. By default it‘s enabled. #: #: .. versionadded:: 0.9 disable_data_descriptor = False def __init__(self, environ, populate_request=True, shallow=False): self.environ = environ if populate_request and not shallow: self.environ[‘werkzeug.request‘] = self self.shallow = shallow def __repr__(self): # make sure the __repr__ even works if the request was created # from an invalid WSGI environment. If we display the request # in a debug session we don‘t want the repr to blow up. args = [] try: args.append("‘%s‘" % to_native(self.url, self.url_charset)) args.append(‘[%s]‘ % self.method) except Exception: args.append(‘(invalid WSGI environ)‘) return ‘<%s %s>‘ % ( self.__class__.__name__, ‘ ‘.join(args) ) @property def url_charset(self): """The charset that is assumed for URLs. Defaults to the value of :attr:`charset`. .. versionadded:: 0.6 """ return self.charset @classmethod def from_values(cls, *args, **kwargs): """Create a new request object based on the values provided. If environ is given missing values are filled from there. This method is useful for small scripts when you need to simulate a request from an URL. Do not use this method for unittesting, there is a full featured client object (:class:`Client`) that allows to create multipart requests, support for cookies etc. This accepts the same options as the :class:`~werkzeug.test.EnvironBuilder`. .. versionchanged:: 0.5 This method now accepts the same arguments as :class:`~werkzeug.test.EnvironBuilder`. Because of this the `environ` parameter is now called `environ_overrides`. :return: request object """ from werkzeug.test import EnvironBuilder charset = kwargs.pop(‘charset‘, cls.charset) kwargs[‘charset‘] = charset builder = EnvironBuilder(*args, **kwargs) try: return builder.get_request(cls) finally: builder.close() @classmethod def application(cls, f): """Decorate a function as responder that accepts the request as first argument. This works like the :func:`responder` decorator but the function is passed the request object as first argument and the request object will be closed automatically:: @Request.application def my_wsgi_app(request): return Response(‘Hello World!‘) As of Werkzeug 0.14 HTTP exceptions are automatically caught and converted to responses instead of failing. :param f: the WSGI callable to decorate :return: a new WSGI callable """ #: return a callable that wraps the -2nd argument with the request #: and calls the function with all the arguments up to that one and #: the request. The return value is then called with the latest #: two arguments. This makes it possible to use this decorator for #: both methods and standalone WSGI functions. from werkzeug.exceptions import HTTPException def application(*args): request = cls(args[-2]) with request: try: resp = f(*args[:-2] + (request,)) except HTTPException as e: resp = e.get_response(args[-2]) return resp(*args[-2:]) return update_wrapper(application, f) def _get_file_stream(self, total_content_length, content_type, filename=None, content_length=None): """Called to get a stream for the file upload. This must provide a file-like class with `read()`, `readline()` and `seek()` methods that is both writeable and readable. The default implementation returns a temporary file if the total content length is higher than 500KB. Because many browsers do not provide a content length for the files only the total content length matters. :param total_content_length: the total content length of all the data in the request combined. This value is guaranteed to be there. :param content_type: the mimetype of the uploaded file. :param filename: the filename of the uploaded file. May be `None`. :param content_length: the length of this file. This value is usually not provided because webbrowsers do not provide this value. """ return default_stream_factory( total_content_length=total_content_length, content_type=content_type, filename=filename, content_length=content_length) @property def want_form_data_parsed(self): """Returns True if the request method carries content. As of Werkzeug 0.9 this will be the case if a content type is transmitted. .. versionadded:: 0.8 """ return bool(self.environ.get(‘CONTENT_TYPE‘)) def make_form_data_parser(self): """Creates the form data parser. Instantiates the :attr:`form_data_parser_class` with some parameters. .. versionadded:: 0.8 """ return self.form_data_parser_class(self._get_file_stream, self.charset, self.encoding_errors, self.max_form_memory_size, self.max_content_length, self.parameter_storage_class) def _load_form_data(self): """Method used internally to retrieve submitted data. After calling this sets `form` and `files` on the request object to multi dicts filled with the incoming form data. As a matter of fact the input stream will be empty afterwards. You can also call this method to force the parsing of the form data. .. versionadded:: 0.8 """ # abort early if we have already consumed the stream if ‘form‘ in self.__dict__: return _assert_not_shallow(self) if self.want_form_data_parsed: content_type = self.environ.get(‘CONTENT_TYPE‘, ‘‘) content_length = get_content_length(self.environ) mimetype, options = parse_options_header(content_type) parser = self.make_form_data_parser() data = parser.parse(self._get_stream_for_parsing(), mimetype, content_length, options) else: data = (self.stream, self.parameter_storage_class(), self.parameter_storage_class()) # inject the values into the instance dict so that we bypass # our cached_property non-data descriptor. d = self.__dict__ d[‘stream‘], d[‘form‘], d[‘files‘] = data def _get_stream_for_parsing(self): """This is the same as accessing :attr:`stream` with the difference that if it finds cached data from calling :meth:`get_data` first it will create a new stream out of the cached data. .. versionadded:: 0.9.3 """ cached_data = getattr(self, ‘_cached_data‘, None) if cached_data is not None: return BytesIO(cached_data) return self.stream def close(self): """Closes associated resources of this request object. This closes all file handles explicitly. You can also use the request object in a with statement which will automatically close it. .. versionadded:: 0.9 """ files = self.__dict__.get(‘files‘) for key, value in iter_multi_items(files or ()): value.close() def __enter__(self): return self def __exit__(self, exc_type, exc_value, tb): self.close() @cached_property def stream(self): """ If the incoming form data was not encoded with a known mimetype the data is stored unmodified in this stream for consumption. Most of the time it is a better idea to use :attr:`data` which will give you that data as a string. The stream only returns the data once. Unlike :attr:`input_stream` this stream is properly guarded that you can‘t accidentally read past the length of the input. Werkzeug will internally always refer to this stream to read data which makes it possible to wrap this object with a stream that does filtering. .. versionchanged:: 0.9 This stream is now always available but might be consumed by the form parser later on. Previously the stream was only set if no parsing happened. """ _assert_not_shallow(self) return get_input_stream(self.environ) input_stream = environ_property(‘wsgi.input‘, """ The WSGI input stream. In general it‘s a bad idea to use this one because you can easily read past the boundary. Use the :attr:`stream` instead. """) @cached_property def args(self): """The parsed URL parameters (the part in the URL after the question mark). By default an :class:`~werkzeug.datastructures.ImmutableMultiDict` is returned from this function. This can be changed by setting :attr:`parameter_storage_class` to a different type. This might be necessary if the order of the form data is important. """ return url_decode(wsgi_get_bytes(self.environ.get(‘QUERY_STRING‘, ‘‘)), self.url_charset, errors=self.encoding_errors, cls=self.parameter_storage_class) @cached_property def data(self): """ Contains the incoming request data as string in case it came with a mimetype Werkzeug does not handle. """ if self.disable_data_descriptor: raise AttributeError(‘data descriptor is disabled‘) # XXX: this should eventually be deprecated. # We trigger form data parsing first which means that the descriptor # will not cache the data that would otherwise be .form or .files # data. This restores the behavior that was there in Werkzeug # before 0.9. New code should use :meth:`get_data` explicitly as # this will make behavior explicit. return self.get_data(parse_form_data=True) def get_data(self, cache=True, as_text=False, parse_form_data=False): """This reads the buffered incoming data from the client into one bytestring. By default this is cached but that behavior can be changed by setting `cache` to `False`. Usually it‘s a bad idea to call this method without checking the content length first as a client could send dozens of megabytes or more to cause memory problems on the server. Note that if the form data was already parsed this method will not return anything as form data parsing does not cache the data like this method does. To implicitly invoke form data parsing function set `parse_form_data` to `True`. When this is done the return value of this method will be an empty string if the form parser handles the data. This generally is not necessary as if the whole data is cached (which is the default) the form parser will used the cached data to parse the form data. Please be generally aware of checking the content length first in any case before calling this method to avoid exhausting server memory. If `as_text` is set to `True` the return value will be a decoded unicode string. .. versionadded:: 0.9 """ rv = getattr(self, ‘_cached_data‘, None) if rv is None: if parse_form_data: self._load_form_data() rv = self.stream.read() if cache: self._cached_data = rv if as_text: rv = rv.decode(self.charset, self.encoding_errors) return rv @cached_property def form(self): """The form parameters. By default an :class:`~werkzeug.datastructures.ImmutableMultiDict` is returned from this function. This can be changed by setting :attr:`parameter_storage_class` to a different type. This might be necessary if the order of the form data is important. Please keep in mind that file uploads will not end up here, but instead in the :attr:`files` attribute. .. versionchanged:: 0.9 Previous to Werkzeug 0.9 this would only contain form data for POST and PUT requests. """ self._load_form_data() return self.form @cached_property def values(self): """A :class:`werkzeug.datastructures.CombinedMultiDict` that combines :attr:`args` and :attr:`form`.""" args = [] for d in self.args, self.form: if not isinstance(d, MultiDict): d = MultiDict(d) args.append(d) return CombinedMultiDict(args) @cached_property def files(self): """:class:`~werkzeug.datastructures.MultiDict` object containing all uploaded files. Each key in :attr:`files` is the name from the ``<input type="file" name="">``. Each value in :attr:`files` is a Werkzeug :class:`~werkzeug.datastructures.FileStorage` object. It basically behaves like a standard file object you know from Python, with the difference that it also has a :meth:`~werkzeug.datastructures.FileStorage.save` function that can store the file on the filesystem. Note that :attr:`files` will only contain data if the request method was POST, PUT or PATCH and the ``<form>`` that posted to the request had ``enctype="multipart/form-data"``. It will be empty otherwise. See the :class:`~werkzeug.datastructures.MultiDict` / :class:`~werkzeug.datastructures.FileStorage` documentation for more details about the used data structure. """ self._load_form_data() return self.files @cached_property def cookies(self): """A :class:`dict` with the contents of all cookies transmitted with the request.""" return parse_cookie(self.environ, self.charset, self.encoding_errors, cls=self.dict_storage_class) @cached_property def headers(self): """The headers from the WSGI environ as immutable :class:`~werkzeug.datastructures.EnvironHeaders`. """ return EnvironHeaders(self.environ) @cached_property def path(self): """Requested path as unicode. This works a bit like the regular path info in the WSGI environment but will always include a leading slash, even if the URL root is accessed. """ raw_path = wsgi_decoding_dance(self.environ.get(‘PATH_INFO‘) or ‘‘, self.charset, self.encoding_errors) return ‘/‘ + raw_path.lstrip(‘/‘) @cached_property def full_path(self): """Requested path as unicode, including the query string.""" return self.path + u‘?‘ + to_unicode(self.query_string, self.url_charset) @cached_property def script_root(self): """The root path of the script without the trailing slash.""" raw_path = wsgi_decoding_dance(self.environ.get(‘SCRIPT_NAME‘) or ‘‘, self.charset, self.encoding_errors) return raw_path.rstrip(‘/‘) @cached_property def url(self): """The reconstructed current URL as IRI. See also: :attr:`trusted_hosts`. """ return get_current_url(self.environ, trusted_hosts=self.trusted_hosts) @cached_property def base_url(self): """Like :attr:`url` but without the querystring See also: :attr:`trusted_hosts`. """ return get_current_url(self.environ, strip_querystring=True, trusted_hosts=self.trusted_hosts) @cached_property def url_root(self): """The full URL root (with hostname), this is the application root as IRI. See also: :attr:`trusted_hosts`. """ return get_current_url(self.environ, True, trusted_hosts=self.trusted_hosts) @cached_property def host_url(self): """Just the host with scheme as IRI. See also: :attr:`trusted_hosts`. """ return get_current_url(self.environ, host_only=True, trusted_hosts=self.trusted_hosts) @cached_property def host(self): """Just the host including the port if available. See also: :attr:`trusted_hosts`. """ return get_host(self.environ, trusted_hosts=self.trusted_hosts) query_string = environ_property( ‘QUERY_STRING‘, ‘‘, read_only=True, load_func=wsgi_get_bytes, doc=‘The URL parameters as raw bytestring.‘) method = environ_property( ‘REQUEST_METHOD‘, ‘GET‘, read_only=True, load_func=lambda x: x.upper(), doc="The request method. (For example ``‘GET‘`` or ``‘POST‘``).") @cached_property def access_route(self): """If a forwarded header exists this is a list of all ip addresses from the client ip to the last proxy server. """ if ‘HTTP_X_FORWARDED_FOR‘ in self.environ: addr = self.environ[‘HTTP_X_FORWARDED_FOR‘].split(‘,‘) return self.list_storage_class([x.strip() for x in addr]) elif ‘REMOTE_ADDR‘ in self.environ: return self.list_storage_class([self.environ[‘REMOTE_ADDR‘]]) return self.list_storage_class() @property def remote_addr(self): """The remote address of the client.""" return self.environ.get(‘REMOTE_ADDR‘) remote_user = environ_property(‘REMOTE_USER‘, doc=‘‘‘ If the server supports user authentication, and the script is protected, this attribute contains the username the user has authenticated as.‘‘‘) scheme = environ_property(‘wsgi.url_scheme‘, doc=‘‘‘ URL scheme (http or https). .. versionadded:: 0.7‘‘‘) @property def is_xhr(self): """True if the request was triggered via a javascript XMLHttpRequest. This only works with libraries that support the ``X-Requested-With`` header and set it to "XMLHttpRequest". Libraries that do that are prototype, jQuery and Mochikit and probably some more. .. deprecated:: 0.13 ``X-Requested-With`` is not standard and is unreliable. """ warn(DeprecationWarning( ‘Request.is_xhr is deprecated. Given that the X-Requested-With ‘ ‘header is not a part of any spec, it is not reliable‘ ), stacklevel=2) return self.environ.get( ‘HTTP_X_REQUESTED_WITH‘, ‘‘ ).lower() == ‘xmlhttprequest‘ is_secure = property(lambda x: x.environ[‘wsgi.url_scheme‘] == ‘https‘, doc=‘`True` if the request is secure.‘) is_multithread = environ_property(‘wsgi.multithread‘, doc=‘‘‘ boolean that is `True` if the application is served by a multithreaded WSGI server.‘‘‘) is_multiprocess = environ_property(‘wsgi.multiprocess‘, doc=‘‘‘ boolean that is `True` if the application is served by a WSGI server that spawns multiple processes.‘‘‘) is_run_once = environ_property(‘wsgi.run_once‘, doc=‘‘‘ boolean that is `True` if the application will be executed only once in a process lifetime. This is the case for CGI for example, but it‘s not guaranteed that the execution only happens one time.‘‘‘)
class FieldFile(File): def __init__(self, instance, field, name): super().__init__(None, name) self.instance = instance self.field = field self.storage = field.storage self._committed = True def __eq__(self, other): # Older code may be expecting FileField values to be simple strings. # By overriding the == operator, it can remain backwards compatibility. if hasattr(other, ‘name‘): return self.name == other.name return self.name == other def __hash__(self): return hash(self.name) # The standard File contains most of the necessary properties, but # FieldFiles can be instantiated without a name, so that needs to # be checked for here. def _require_file(self): if not self: raise ValueError("The ‘%s‘ attribute has no file associated with it." % self.field.name) def _get_file(self): self._require_file() if not hasattr(self, ‘_file‘) or self._file is None: self._file = self.storage.open(self.name, ‘rb‘) return self._file def _set_file(self, file): self._file = file def _del_file(self): del self._file file = property(_get_file, _set_file, _del_file) @property def path(self): self._require_file() return self.storage.path(self.name) @property def url(self): self._require_file() return self.storage.url(self.name) @property def size(self): self._require_file() if not self._committed: return self.file.size return self.storage.size(self.name) def open(self, mode=‘rb‘): self._require_file() if hasattr(self, ‘_file‘) and self._file is not None: self.file.open(mode) else: self.file = self.storage.open(self.name, mode) return self # open() doesn‘t alter the file‘s contents, but it does reset the pointer open.alters_data = True # In addition to the standard File API, FieldFiles have extra methods # to further manipulate the underlying file, as well as update the # associated model instance. def save(self, name, content, save=True): name = self.field.generate_filename(self.instance, name) self.name = self.storage.save(name, content, max_length=self.field.max_length) setattr(self.instance, self.field.name, self.name) self._committed = True # Save the object because it has changed, unless save is False if save: self.instance.save() save.alters_data = True def delete(self, save=True): if not self: return # Only close the file if it‘s already open, which we know by the # presence of self._file if hasattr(self, ‘_file‘): self.close() del self.file self.storage.delete(self.name) self.name = None setattr(self.instance, self.field.name, self.name) self._committed = False if save: self.instance.save() delete.alters_data = True @property def closed(self): file = getattr(self, ‘_file‘, None) return file is None or file.closed def close(self): file = getattr(self, ‘_file‘, None) if file is not None: file.close() def __getstate__(self): # FieldFile needs access to its associated model field and an instance # it‘s attached to in order to work properly, but the only necessary # data to be pickled is the file‘s name itself. Everything else will # be restored later, by FileDescriptor below. return {‘name‘: self.name, ‘closed‘: False, ‘_committed‘: True, ‘_file‘: None}
class File(FileProxyMixin): DEFAULT_CHUNK_SIZE = 64 * 2 ** 10 def __init__(self, file, name=None): self.file = file if name is None: name = getattr(file, ‘name‘, None) self.name = name if hasattr(file, ‘mode‘): self.mode = file.mode def __str__(self): return self.name or ‘‘ def __repr__(self): return "<%s: %s>" % (self.__class__.__name__, self or "None") def __bool__(self): return bool(self.name) def __len__(self): return self.size def _get_size_from_underlying_file(self): if hasattr(self.file, ‘size‘): return self.file.size if hasattr(self.file, ‘name‘): try: return os.path.getsize(self.file.name) except (OSError, TypeError): pass if hasattr(self.file, ‘tell‘) and hasattr(self.file, ‘seek‘): pos = self.file.tell() self.file.seek(0, os.SEEK_END) size = self.file.tell() self.file.seek(pos) return size raise AttributeError("Unable to determine the file‘s size.") def _get_size(self): if hasattr(self, ‘_size‘): return self._size self._size = self._get_size_from_underlying_file() return self._size def _set_size(self, size): self._size = size size = property(_get_size, _set_size) def chunks(self, chunk_size=None): """ Read the file and yield chunks of ``chunk_size`` bytes (defaults to ``UploadedFile.DEFAULT_CHUNK_SIZE``). """ if not chunk_size: chunk_size = self.DEFAULT_CHUNK_SIZE try: self.seek(0) except (AttributeError, UnsupportedOperation): pass while True: data = self.read(chunk_size) if not data: break yield data def multiple_chunks(self, chunk_size=None): """ Return ``True`` if you can expect multiple chunks. NB: If a particular file representation is in memory, subclasses should always return ``False`` -- there‘s no good reason to read from memory in chunks. """ if not chunk_size: chunk_size = self.DEFAULT_CHUNK_SIZE return self.size > chunk_size def __iter__(self): # Iterate over this file-like object by newlines buffer_ = None for chunk in self.chunks(): for line in chunk.splitlines(True): if buffer_: if endswith_cr(buffer_) and not equals_lf(line): # Line split after a newline; yield buffer_. yield buffer_ # Continue with line. else: # Line either split without a newline (line # continues after buffer_) or with # newline (line == b‘ ‘). line = buffer_ + line # buffer_ handled, clear it. buffer_ = None # If this is the end of a or line, yield. if endswith_lf(line): yield line else: buffer_ = line if buffer_ is not None: yield buffer_ def __enter__(self): return self def __exit__(self, exc_type, exc_value, tb): self.close() def open(self, mode=None): if not self.closed: self.seek(0) elif self.name and os.path.exists(self.name): self.file = open(self.name, mode or self.mode) else: raise ValueError("The file cannot be reopened.") return self def close(self): self.file.close()
1 # coding:utf-8 2 3 from flask import Flask,render_template,request,redirect,url_for 4 from werkzeug.utils import secure_filename 5 import os 6 7 app = Flask(__name__) 8 9 @app.route(‘/upload‘, methods=[‘POST‘, ‘GET‘]) 10 def upload(): 11 if request.method == ‘POST‘: 12 f = request.files[‘file‘] 13 basepath = os.path.dirname(__file__) # 当前文件所在路径 14 upload_path = os.path.join(basepath, ‘staticuploads‘,secure_filename(f.filename)) #注意:没有的文件夹一定要先创建,不然会提示没有该路径 15 f.save(upload_path) 16 return redirect(url_for(‘upload‘)) 17 return render_template(‘upload.html‘) 18 19 if __name__ == ‘__main__‘: 20 app.run(debug=True) 1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>Title</title> 6 </head> 7 <body> 8 <h1>文件上传示例</h1> 9 <form action="" enctype=‘multipart/form-data‘ method=‘POST‘> 10 <input type="file" name="file"> 11 <input type="submit" value="上传"> 12 </form> 13 </body> 14 </html>
@app.route(‘/delete/<int:nid>‘)
def delete(nid):
return redirect(url_for(‘index‘))
1
from funtools improt wraps
装饰器
def auth(func):
@functools.wraps(func) /@wraps(func) #装饰器修复技术,修复的是文档信息: 不加上这个 原函数内原信息就不会被复制
def inner(*args,**kwargs):
if not session.get(‘user‘):
return redirect(url_for(‘login‘))
return func(*args,kwargs)
return inner
2
endpoint 默认是函数名,目的是反向生成url
3 装饰器先后顺序
@app.route(‘login‘,method=["GET","POST"])
@auth
def login():
if request.method == "":
pass
return render_template(‘login.html‘,error="错误信息")
4 before_request
@app.before_request#特殊的装饰器
def name():
print(‘每个请求过来都需要先经过它,‘)#适合给大量 视图函数 添加规则等
if request.path == ‘/login‘:#当前路径
return None;
if session.get(‘user‘):
return None
return redirect(‘/login‘)
from flask import Markup
方式一
input=Markup(‘<input type="text" />‘)
方式二
{{ input|safe }}
特殊的装饰器
@app.template_global()#注册为全局作用
def glo(a,b):
return a+b
@app.template_filter()
def fil(a,b,c):
return a+b+c
{{ 1|fil(2,3) }}
{% extend ‘.html‘ %} 继承
{% block content-name %}
{% endblock %}
[
宏的使用
{% macro hong_name(name,type=‘text‘,value=‘‘) %}
<h1>宏</h1>
<input type="{{ type }}" name="{{ name }} value="{{ value }}">
<input type=‘submit‘ value="submit">
{% endmacro %}
宏的调用
{{ hong_name(‘n1‘) }}
]
模板渲染
-基本数据类型,可以使用python语法
-传入函数:
- django:自动执行
- flask:不自动执行
-全局定义函数
@app.template_global()
def name(a,b):
return a+b
@app.template_filter()
def name(a,b,c):
return a+b+c
{{ a|name(b,c) }}
session
当请求刚到来,flask 读取cookie中session对应的值,将取出来的值解密并反序列化成字典,
当请求结束时,flask 会读取内存中字典的值,进行序列化+加密,写入到用户的cookies中
闪现
from flask import get_flashed_messages
flask 和 特殊装饰器
flask(‘临时存储数据‘) #存入临时保存的值
print(get_flashed_messages())#取出上面的值,貌似源码 就是pop了一下
flask(‘临时存储数据‘,‘error‘)
flask(‘sdfsdsdfsd‘,‘info‘)
#根据分类来取值,
get_flashed_messages(category_filter=[‘error‘])# 取出error type的信息 info就不取了
闪现:在session中存储一个数据,读取时通过pop将数据移除。
from flask import get_flashed_messages
中间件
-- call 方法什么时候触发?
用户发起请求是,才执行
-- 任务:在执行call方法之前,做一个操作,call 方法执行之后做一个操作
class Middleware(object):
def __init__(self,old):
self.old=old
def __call__(self,*args,**kwargs):
ret = self.old(*args,**kwargs)
return ret
#django 和 flask 的中间件 是有的不同的 有什么不同?
# 什么是flask 的中间件? 作用是什么 ?
if __name__== "__main__":
app.wsgi_app = Middleware(app.wsgi_app)
==
app.__call__ = Middleware(app.__call__)
app.run()
特殊的装饰器
before_request
after_request
template_global
template_filter
before_first_request
errorhandler
@app.errorhandler(404)
def not_found(arg):
print(arg)
return ‘没找到‘
@app.before_request
def x1():
print(‘before‘)
@app.after_request
def x2(response):
print(‘after‘)
return reponse
before :没有参数、没有返回值
after :有参数,有返回值
执行顺序 before ---> view_function ----> after
before 先定义 先执行
after 先reverse 了 一下,你懂得,所以后定义先执行
@app.before_first_request
def one():
print(‘我只执行一次!‘)
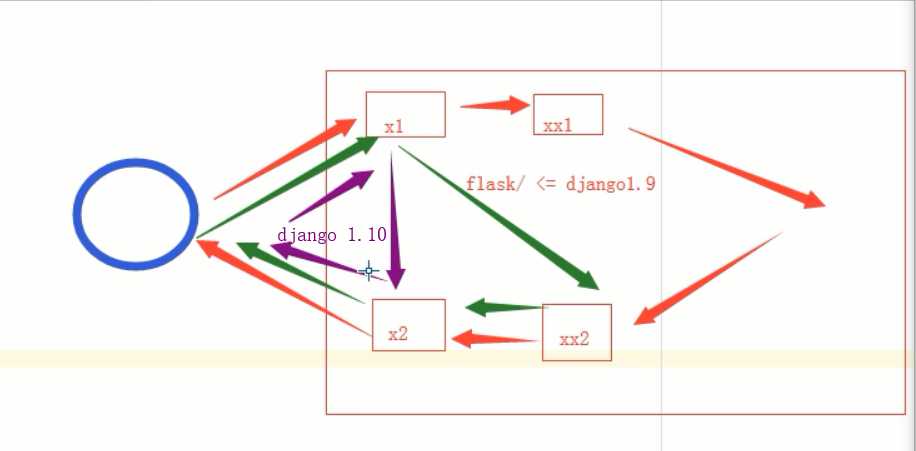
第二天
1 路由+视图
2 session 实现原理
3 蓝图 (flask 目录结构的划分)
4 threading.local [上下文管理]
5 上下文管理(第一次)
django 和 flask 的区别 ?
相同点:都依赖于wsgi
不同点: django请求相关数据是通过参数一个一个 传递参数传递过来的
flask: 先放在某个地方以后在去值
什么是wsgi?
web服务网管接口,就是一个协议,实现该协议的模块:
- wsgiref
- werkzeug
实现其协议的模块本质上就是socket服务端 用于接收用户请求,并处理。
一般web框架基于wsgi实现,这样实现关注点分离
from wsgiref.simple_server import make_server
def run_server(environ,start_response):
start_response(‘200 OK‘,[(‘Content-Type‘,‘text/html‘)])
return [bytes(‘<h1>hello,web!</h1>‘,encoding=‘utf-8‘),]
if __name__=="__main__":
httpd = make_server(‘‘,8000,RunServer)
print("Serving HTTP on port 8000 。。。")
httpd.serve_forever()
02 python fullstack s9day116 内容回顾.mp4
from werkzeug.wrappers import Response
from werkzeug.serving import run_simple
class Flask(object):
def __call__(self,environ,start_response):
response = Response(‘hello‘)
return response(environ,start_response)
def run(self):
run_simple(‘127.0.0.1‘,8000,self)
app = Flask()
if __name__ == ‘__main__‘:
app.run()
"""A decorator that is used to register a view function for a
given URL rule. This does the same thing as :meth:`add_url_rule`
but is intended for decorator usage::
@app.route(‘/‘)
def index():
return ‘Hello World‘
For more information refer to :ref:`url-route-registrations`.
:param rule: the URL rule as string
:param endpoint: the endpoint for the registered URL rule. Flask
itself assumes the name of the view function as
endpoint
:param options: the options to be forwarded to the underlying
:class:`~werkzeug.routing.Rule` object. A change
to Werkzeug is handling of method options. methods
is a list of methods this rule should be limited
to (``GET``, ``POST`` etc.). By default a rule
just listens for ``GET`` (and implicitly ``HEAD``).
Starting with Flask 0.6, ``OPTIONS`` is implicitly
added and handled by the standard request handling.
"""
def route(self, rule, **options):
def decorator(f):
endpoint = options.pop(‘endpoint‘, None)
self.add_url_rule(rule, endpoint, f, **options)
return f
return decorator
def tiankong():
print(‘tiankong !‘)
def priName(arg):
print("priName({})".format(arg.__name__))
print("print:{}".format(arg.__name__))
priName(tiankong)
路由设置的两种方式:
@app.route(‘/index‘)#‘/index‘ 这里是url 和下面的函数名是两个概念
def index():
return "index"
def index():
return "index"
app.add_url_rule("/index",None, index)
url endpoint view_function_name
子域名
from flask import Flask,Views,url_for
app =Flask(import_name = __name__ )
app.config[‘SERVER_NAME‘] = ‘wupeiqi.com:5000‘#一定要把这里配置加上
#当用户访问admin.wupeiqi.com 的时候以下视图函数被触发 相当于二级域名
@app.route(‘/‘,subdomain="admin")
def static_index():
pass
#只要是以http://xxx.wupeiqi.com:5000/ 就能被这里访问
@app.route(‘/dynamic‘,subdomain="<username>")
def username_index(username):
return username+‘.your~domain.tld‘
from flask import Flask,views
app = Flask(__name__)
@app.route(‘/index‘,redirect_to=‘/new‘)
def index():#老系统
pass
CBV
from flask import views,
from funtools import wrapper#装饰器修复技术
class UserView(views.MethodView):
methods = [‘GET‘] # 这里设置 GET / POST 是否允许访问限制
decorators = [wrapper,] #自动执行里面的装饰器
def get(self,*args,**kwargs):
return "GET"
deg post(self,*args,**kwargs):
return ‘POST‘
app.add_url_rule(‘/user‘,None,UserView.as_view(‘‘))
自定义正则
from flask import Flask
app = Flask(__name__)
from werkzeug.routing import BaseConverter
class RegexConverter(BaseConverter):
‘‘‘‘
自定义url 匹配正则表达式
‘‘‘
def __init__(self,map,regex):
super(RegexConverter,slef).__init__(map)
self.regex = regex
.....
pass
app.url_map.converters[‘reg‘]=RegexConverter
#是注册 还是 添加呢?
day30 month9 am10
from flask import Flask
app = Flask(__name__)
#先执行 decorator= app.route(‘/index‘)[route 返回一个函数 decorator(view_function)]
# @decorator
@app.route(‘/index‘)
def index():
return "index"
[ 源码
def route(self,rule,**options):
def decorator(f):
endpoint = options.pop(‘endpoint‘,None)
self.add_url_rule(rule,endpoint,f,**options)
# rule path
# endpoint 别名 用于逆向解析
# f function——view
# options
# self app= Flask(__name__)
return f
return decorator
]
# 路由系统的本质就是self.add_url_rule(rule,endpoint,f,**options)
#
#注册路由还可以这样写
def index():
return ‘注册路由还可以这样写‘
app.add_url_rule(‘/index‘,None,index)
#django 和 flask
def index():
return ‘其实就是for循环‘
routes = [
(‘/xxx‘,index,),
(‘/...‘,...,),
....
]
for route in routes:#不一定对
if len(route)==2:
app.add_url_rule(route[0],None,route[1])
app.app_url_rule(**route)
[ 源码
@setupmethod
def add_url_urle(self,rule,endpoint=None,view_func=None,provide_automatic_options=None,**options):
if endpoint is None:
endpoint = _endpoint_from_func(view_func)
options[‘endpoint‘] = endpoint
methods = options.pop(‘method‘,None)
if methods is None:
methods = getattr(view_func,‘methods‘,None) or (‘GET‘,)
if isinstance(methods,string_types):
raise TypeError(‘这个错误有点长‘)
methods = set(item.upper() for item in methods )
required_methods = set(getattr(view_func,‘required_methods‘,()))
...
底下还有很长
def _endpoint_from_view_func(view_func):
assert view_func is not None,‘expected view func if endpoint is not provided.‘
return view_func.__name__#获取函数名,view_func传进来的是function-view
]
route 参数
from flask import Flask
app = Flask(__name__)
@app.route(rule=‘/index‘,endpoint=‘‘,methods=[‘GET‘,‘POST‘],default={‘k‘:‘v‘},)
def index(k):
return ‘sample‘
add_url_urle(self,rule,endpoint=None,view_func=None,provide_automatic_options=None,**options):
endpoint=None, 名称,用于反向生成url,即url_for(‘名称‘) methods=None, 允许请求方式,如:[‘GET‘,‘POST‘] 默认只开启GET,所以POST 需要手动设置 rule, URL规则 view_func, 视图函数名称 defaults=None, 默认值,当URL中无参数,函数需要参数时,使用defaults={‘k‘:‘value‘}为函数提供参数
strict_slashes=None, 对URL最后的 / 符号是否严格要求,
如:www.baidu.com/yanyi 和 www.baidu.com/yanyi/
@app.route(‘/index‘,strict_slashes=True)
仅能访问 www.baidu.com/index
redirect_to=None 重定向指定地址
如:@app.route(‘/index/<int:nid>‘,redirect_to=‘/home/<nid>‘)
或
def func(adapter,nid):
return ‘/home/8989‘
@app.route(‘/index/<int:nid>‘,redirct_to=func)
subdomain=None 子域名访问
from flask import Flask,views,url_for
app =Flask(__name__)
#必须先要配置SERVER_NAME
app.config[‘SERVER_NAME‘] = ‘xiarenwang.com:8888‘
#本机
#app.config[‘SERVER_NAME‘]=‘localhost:8080‘
@app.route(‘/‘,subdomain=‘home‘)
def index():
return ‘home.xiarenwang.com‘
#浏览器输入:http://index.localhost:8080/
@app.route(‘/dynamic‘,subdomain="<username>")
def username_index(username):
return username+‘your-domain.xx‘
ip 与 域名的对应关系 修改
windows 下:
path:C:WindowsSystem32driversetchosts
找到host 文件,并且添加以下映射关系
127.0.0.1 xiarenwang.com
127.0.0.1 index.xiarenwang.com
127.0.0.1 admin.xiarenwang.com
#配置好了后发现无法访问二级域名?
* Serving Flask app "a" (lazy loading)
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
CBV
class UserView(views.MethodView):
methods = [‘GET‘,‘POST‘] #开放GET 和 POST 请求
decorators = [wrapper,]#批量加上装饰器
def get(self,*args,**kwargs):
return "GET"
def post(self,*args,**kwargs):
return "POST"
app.add_url_rule(‘/user‘,None,UserView.as_view(‘xxxx‘))
[
@classmethod
def as_view(cls,name,*class_args,**class_kwargs):
def view(*args,**kwargs):
self = view.view_class(*class_args,**class_kwargs)
return self.dispatch_request(*args,**kwargs)
if cls.decorators:
view.__name__ = name
.....
....
return view
]
自定义正则
from flask import Flask
from werkzeug.routing import BaseConverter
app = Flask(__name__)
# 定制自定义转换器类
class RegexConverter(BaseConverter):
"""
自定义URL 匹配正则表达式
"""
def __init__(self,map,regex):#map 是自动传值的
super(RegexConverter,self).__init__(map)
self.regex = regex
#在flask 源码里面会自动读取(加载妥当还是读取妥当?)self.regex,会根据你写的正则,来进行匹配
def to_python(self,value):
"""
路由匹配时,匹配成功后传递给视图函数中参数的值
"""
return int(value)
def to_url(self,vlaue):#反向生成url 触发
"""
使用url_for 反向生成URL时,传递的参数经过该方法出来,返回的值用于生成URL中的参数
"""
app.url_map.converters[‘reg‘] = RegexConverter
#这里给RegexConverter 进行注册
#在原有转换器的基础上添加 reg
[#添加到DEFAUTL_CONVERTERS字典中
#:the deafult converter mapping for the map.
DEFAULT_CONVERTERS = {
‘‘:‘‘
...
‘reg‘:RegexConverter
}
]
@app.route(‘/index/<reg("d+"):nid>‘)
def index(nid):
return "index"
#reg 代指的就是RegexConverter这个类。RegexConverter() 实例化
#
#流程
1. 用户发送请求
2. falsk 内部进行正则匹配
3.调用to_python(正则匹配的结果)方法
4.to_python方法的返回值会交给视图函数的参数
@app.route(‘/index/<reg("d+"):nid>‘)
def index(nid):
print(nid,type(nid))
return "index"
from flask import url_for
@app.route(‘/index/<reg("d+"):nid>‘)
def index(nid):
print(url_for(‘index‘,nid=8888))
#假如nid是8888,进行反向解析的时候,会先将nid传给to_url,
#to_url(value) 这个value 就是nid ,return 的val 就是反向解析的结果
return "index"
if __name__ == "__main__":
app.run()
ImmutableDict() ?????
app.url_map.converters[‘xx‘]= XxConverter
converters = default_converters.copy()
default_converters = ImmutableDict(DEFAULT_CONVERTERS)
DEFAUTL_CONVERS= {
#内置转换器
}
Session 实现原理(源码)
from flask import Flask
#实例化对象
app = Flask(__name__)
#设置路由
app.route(‘/index‘)
def index():
return "index"
if __name__ == "__main__":
app.run()#本质就是启动socket服务端
app.__call__ #用户请求到达,会执行__call__
app.wsgi_app
app.request_class
app.session_interface
#设置路由本质:
app.url_map()
url_map() = Map()#是个Map对象
#保存所有路由关系对象
app.url_map=
[
(‘/index‘,index)
]
#environ 是请求相关的所有数据[由wsgi做了初步的封装]
#start_response 用于设置响应相关数据
[
def __call__(self,environ,start_response):
return self.wsgi_app(environ,start_response)
]
__call__ 什么时候触发?为什么触发?(貌似对象执行了()会触发)
[
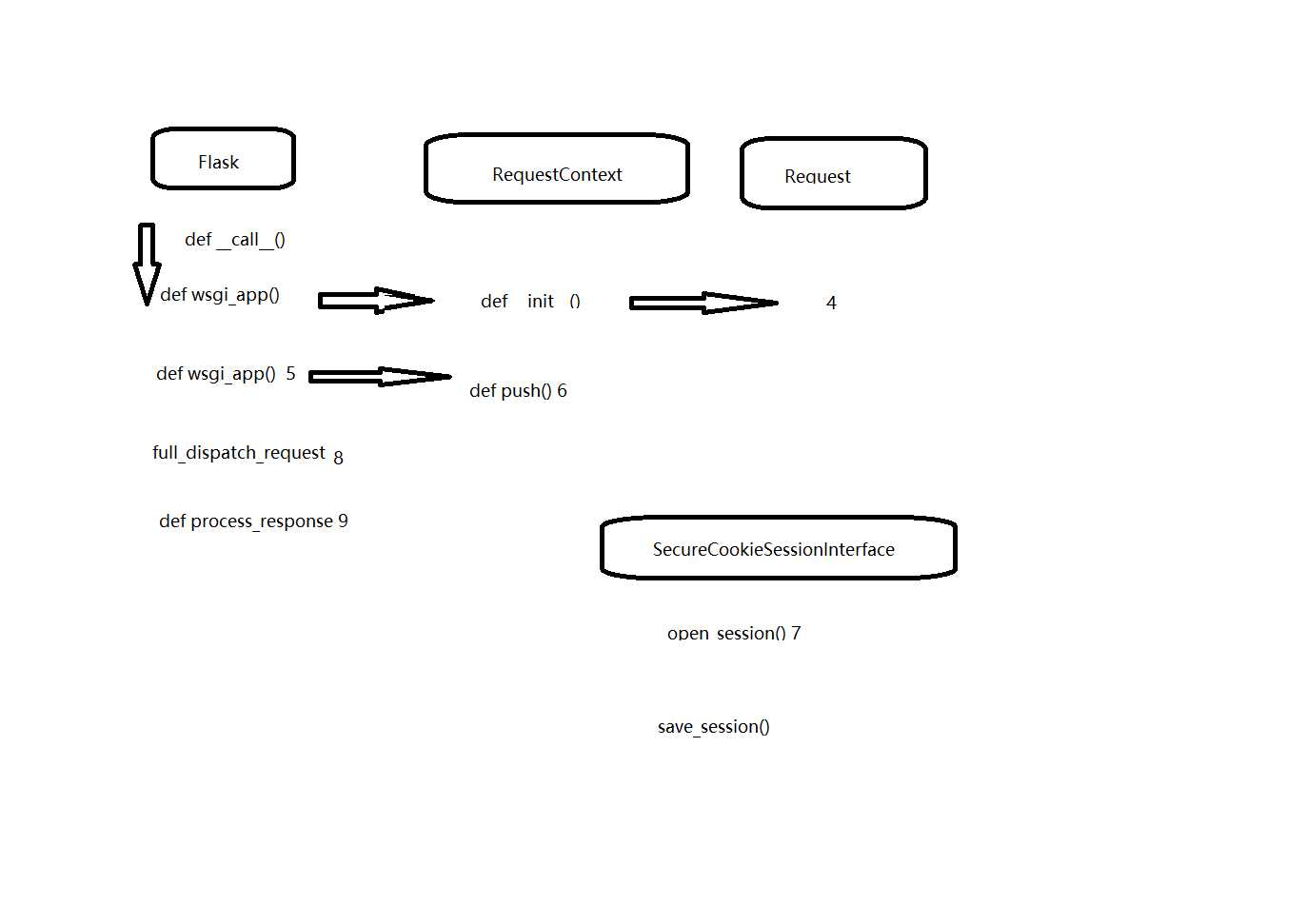
def wsgi_app(self,environ,start_response):
ctx = self.request_context(environ)
#1.获取environ后,再次将environ 进行封装
#2.从environ中获取名称为session的cookie,解密,反序列化
#3.在
error = None
try:
try:
ctx.push()
# 4. 执行视图函数
response = self.full_dispatch_request()
except Exception as e:
error = e
response = self.handle_exception(e)
except:
error = sys.exc_info()[1]
raise
return response(environ,start_response)
finally:
if self.should_ignore_error(error):
error = None
"""
5. 获取session,加密,序列化 写入cookie
6. 清空数据
"""
ctx.auto_pop(error)
]
sys.exc_info() ????????
[
def request_context(self, environ):
return RequestContext(self, environ)
class RequestContext(object):
def __init__(self, app, environ, request=None):
self.app = app
if request is None:
request = app.request_class(environ)
self.request = request
self.url_adapter = app.create_url_adapter(self.request)
self.flashes = None
self.session = None
.....
if self.session is None:
session_interface = self.app.session_interface
self.session = session_interface.open_session( self.app, self.request )
if self.session is None:
self.session = session_interface.make_null_session(self.app)
#code more
from .wrapper import Request
class Flask(_PackageBoundObject):
request_class = Request
....
session_interface = SecureCookieSessionInterface()
# code more
class SecureCookieSessionInterface(SessionInterface):
pass
def open_session(self, app, request):
s = self.get_signing_serializer(app)
if s is None:
return None
val = request.cookies.get(app.session_cookie_name)
if not val:
return self.session_class()
max_age = total_seconds(app.permanent_session_lifetime)
try:
data = s.loads(val, max_age=max_age)
return self.session_class(data)
except BadSignature:
return self.session_class()
class SessionInterface(object):
pass
]
作业 流程图????
class SessionInterface(object): """The basic interface you have to implement in order to replace the default session interface which uses werkzeug‘s securecookie implementation. The only methods you have to implement are :meth:`open_session` and :meth:`save_session`, the others have useful defaults which you don‘t need to change. The session object returned by the :meth:`open_session` method has to provide a dictionary like interface plus the properties and methods from the :class:`SessionMixin`. We recommend just subclassing a dict and adding that mixin:: class Session(dict, SessionMixin): pass If :meth:`open_session` returns ``None`` Flask will call into :meth:`make_null_session` to create a session that acts as replacement if the session support cannot work because some requirement is not fulfilled. The default :class:`NullSession` class that is created will complain that the secret key was not set. To replace the session interface on an application all you have to do is to assign :attr:`flask.Flask.session_interface`:: app = Flask(__name__) app.session_interface = MySessionInterface() .. versionadded:: 0.8 """ #: :meth:`make_null_session` will look here for the class that should #: be created when a null session is requested. Likewise the #: :meth:`is_null_session` method will perform a typecheck against #: this type. null_session_class = NullSession #: A flag that indicates if the session interface is pickle based. #: This can be used by Flask extensions to make a decision in regards #: to how to deal with the session object. #: #: .. versionadded:: 0.10 pickle_based = False def make_null_session(self, app): """Creates a null session which acts as a replacement object if the real session support could not be loaded due to a configuration error. This mainly aids the user experience because the job of the null session is to still support lookup without complaining but modifications are answered with a helpful error message of what failed. This creates an instance of :attr:`null_session_class` by default. """ return self.null_session_class() def is_null_session(self, obj): """Checks if a given object is a null session. Null sessions are not asked to be saved. This checks if the object is an instance of :attr:`null_session_class` by default. """ return isinstance(obj, self.null_session_class) def get_cookie_domain(self, app): """Returns the domain that should be set for the session cookie. Uses ``SESSION_COOKIE_DOMAIN`` if it is configured, otherwise falls back to detecting the domain based on ``SERVER_NAME``. Once detected (or if not set at all), ``SESSION_COOKIE_DOMAIN`` is updated to avoid re-running the logic. """ rv = app.config[‘SESSION_COOKIE_DOMAIN‘] # set explicitly, or cached from SERVER_NAME detection # if False, return None if rv is not None: return rv if rv else None rv = app.config[‘SERVER_NAME‘] # server name not set, cache False to return none next time if not rv: app.config[‘SESSION_COOKIE_DOMAIN‘] = False return None # chop off the port which is usually not supported by browsers # remove any leading ‘.‘ since we‘ll add that later rv = rv.rsplit(‘:‘, 1)[0].lstrip(‘.‘) if ‘.‘ not in rv: # Chrome doesn‘t allow names without a ‘.‘ # this should only come up with localhost # hack around this by not setting the name, and show a warning warnings.warn( ‘"{rv}" is not a valid cookie domain, it must contain a ".".‘ ‘ Add an entry to your hosts file, for example‘ ‘ "{rv}.localdomain", and use that instead.‘.format(rv=rv) ) app.config[‘SESSION_COOKIE_DOMAIN‘] = False return None ip = is_ip(rv) if ip: warnings.warn( ‘The session cookie domain is an IP address. This may not work‘ ‘ as intended in some browsers. Add an entry to your hosts‘ ‘ file, for example "localhost.localdomain", and use that‘ ‘ instead.‘ ) # if this is not an ip and app is mounted at the root, allow subdomain # matching by adding a ‘.‘ prefix if self.get_cookie_path(app) == ‘/‘ and not ip: rv = ‘.‘ + rv app.config[‘SESSION_COOKIE_DOMAIN‘] = rv return rv def get_cookie_path(self, app): """Returns the path for which the cookie should be valid. The default implementation uses the value from the ``SESSION_COOKIE_PATH`` config var if it‘s set, and falls back to ``APPLICATION_ROOT`` or uses ``/`` if it‘s ``None``. """ return app.config[‘SESSION_COOKIE_PATH‘] or app.config[‘APPLICATION_ROOT‘] def get_cookie_httponly(self, app): """Returns True if the session cookie should be httponly. This currently just returns the value of the ``SESSION_COOKIE_HTTPONLY`` config var. """ return app.config[‘SESSION_COOKIE_HTTPONLY‘] def get_cookie_secure(self, app): """Returns True if the cookie should be secure. This currently just returns the value of the ``SESSION_COOKIE_SECURE`` setting. """ return app.config[‘SESSION_COOKIE_SECURE‘] def get_cookie_samesite(self, app): """Return ``‘Strict‘`` or ``‘Lax‘`` if the cookie should use the ``SameSite`` attribute. This currently just returns the value of the :data:`SESSION_COOKIE_SAMESITE` setting. """ return app.config[‘SESSION_COOKIE_SAMESITE‘] def get_expiration_time(self, app, session): """A helper method that returns an expiration date for the session or ``None`` if the session is linked to the browser session. The default implementation returns now + the permanent session lifetime configured on the application. """ if session.permanent: return datetime.utcnow() + app.permanent_session_lifetime def should_set_cookie(self, app, session): """Used by session backends to determine if a ``Set-Cookie`` header should be set for this session cookie for this response. If the session has been modified, the cookie is set. If the session is permanent and the ``SESSION_REFRESH_EACH_REQUEST`` config is true, the cookie is always set. This check is usually skipped if the session was deleted. .. versionadded:: 0.11 """ return session.modified or ( session.permanent and app.config[‘SESSION_REFRESH_EACH_REQUEST‘] ) def open_session(self, app, request): """This method has to be implemented and must either return ``None`` in case the loading failed because of a configuration error or an instance of a session object which implements a dictionary like interface + the methods and attributes on :class:`SessionMixin`. """ raise NotImplementedError() def save_session(self, app, session, response): """This is called for actual sessions returned by :meth:`open_session` at the end of the request. This is still called during a request context so if you absolutely need access to the request you can do that. """ raise NotImplementedError() session_json_serializer = TaggedJSONSerializer() class SecureCookieSessionInterface(SessionInterface): """The default session interface that stores sessions in signed cookies through the :mod:`itsdangerous` module. """ #: the salt that should be applied on top of the secret key for the #: signing of cookie based sessions. salt = ‘cookie-session‘ #: the hash function to use for the signature. The default is sha1 digest_method = staticmethod(hashlib.sha1) #: the name of the itsdangerous supported key derivation. The default #: is hmac. key_derivation = ‘hmac‘ #: A python serializer for the payload. The default is a compact #: JSON derived serializer with support for some extra Python types #: such as datetime objects or tuples. serializer = session_json_serializer session_class = SecureCookieSession def get_signing_serializer(self, app): if not app.secret_key: return None signer_kwargs = dict( key_derivation=self.key_derivation, digest_method=self.digest_method ) return URLSafeTimedSerializer(app.secret_key, salt=self.salt, serializer=self.serializer, signer_kwargs=signer_kwargs) def open_session(self, app, request): s = self.get_signing_serializer(app) if s is None: return None val = request.cookies.get(app.session_cookie_name) if not val: return self.session_class() max_age = total_seconds(app.permanent_session_lifetime) try: data = s.loads(val, max_age=max_age) return self.session_class(data) except BadSignature: return self.session_class() def save_session(self, app, session, response): domain = self.get_cookie_domain(app) path = self.get_cookie_path(app) # If the session is modified to be empty, remove the cookie. # If the session is empty, return without setting the cookie. if not session: if session.modified: response.delete_cookie( app.session_cookie_name, domain=domain, path=path ) return # Add a "Vary: Cookie" header if the session was accessed at all. if session.accessed: response.vary.add(‘Cookie‘) if not self.should_set_cookie(app, session): return httponly = self.get_cookie_httponly(app) secure = self.get_cookie_secure(app) samesite = self.get_cookie_samesite(app) expires = self.get_expiration_time(app, session) val = self.get_signing_serializer(app).dumps(dict(session)) response.set_cookie( app.session_cookie_name, val, expires=expires, httponly=httponly, domain=domain, path=path, secure=secure, samesite=samesite )
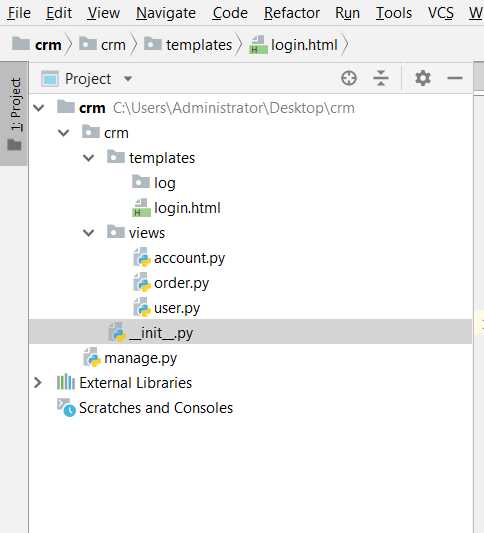
蓝图(blueprint):给目录结构
from flask import Flask
app = Flask(__name__)
app
# 报错 ValueError: urls must start with a leading slash
# 路由注册时 少写了/
@ac.route(‘login‘)
def login():
return ‘login‘
以下是小蓝图 例子
crm
from crm import create_app app = create_app() if __name__ == ‘__main__‘: app.run()
crm folder
from flask import Flask from .views.account import ac from .views.user import uc def create_app(): app = Flask(__name__) @app.before_request def filter(): print(‘过滤全局!全局方法‘) app.register_blueprint(ac,url_prefix=‘/api‘)#加前缀,url_prefix=‘/api‘ #浏览器输入http://127.0.0.1:5000/api/login app.register_blueprint(uc) return app # 过滤全局!全局方法 # 127.0.0.1 - - [01/Oct/2018 00:20:39] "GET /list HTTP/1.1" 200 - # 过滤局部!uc方法 # 过滤全局!全局方法 # 127.0.0.1 - - [01/Oct/2018 00:20:47] "GET /api/login HTTP/1.1" 200 - # 在蓝图里面可以全部加特殊装饰器,也可以是局部的 #例子:before_request #这个 项目目录结构 是小蓝图的例子[小型应用程序] #大蓝图 就和django 基本上一样了[大型应用程序] #
views
from flask import Blueprint uc = Blueprint(‘uc‘,__name__) @uc.before_request def filter(): print(‘过滤局部!uc方法‘) @uc.route(‘/list‘) def list(): return ‘List‘ @uc.route(‘/detail‘) def detail(): return ‘detail‘
#账户相关 from flask import Blueprint,render_template ac = Blueprint(‘ac‘,__name__,template_folder=‘log‘)#设置模板文件夹,优先在templates里面找模板文件,找不到再到template_folder 设置的文件夹里面去找 # ac = Blueprint(‘ac‘,__name__,template_folder=‘log‘,static_url_path=‘‘) #还可以设置静态文件 什么鬼? 如何用的? @ac.route(‘/login‘) def login(): # return render_template(‘/log/login.html‘)#这样可以访问的 return render_template(‘login.html‘) @ac.route(‘/logout‘) def logout(): return ‘logout‘
templates
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> 用户登录 </body> </html>
大蓝图
thread.local 数据隔离 防止数据混乱
import threading
from threading import local
import time
obj = local()
def task(i):
obj.xxxx = i
time.sleep(1.5)
print(obj.xxxx, i)
class o(local):
x = 0
def walk(i):
o.x = i
time.sleep(2)
print(o.x, i)
for i in range(10):
t = threading.Thread(target=task, args=(i,))
# t=threading.Thread(target=walk,args=(i,))
t.start()
# 另外一种线程隔离的方式
dic = {}
def task(i): # 给每个线程开辟独立空间
ident = threading.get_ident() # 获取线程id
if ident in dic:
dic[ident][‘xxx‘] = i
else:
dic[ident] = {‘xxx‘: i}
import greenlet
# 为每个协程开辟空间,做数据隔离
def walk(i):
ident = greenlet.getcurrent() # 获取协程的id
if ident in dic:
dic[ident][‘xxx‘] = i
else:
dic[ident] = {‘xxx‘: i}
自定义Local
class Local(object):
DIC = {
}
def __getattr__(self, item):#获取属性值的时候被触发
print(‘__getattr__‘,item)
ident = threading.get_ident()
if ident in self.DIC:
return self.DIC
return None
def __setattr__(self, key, value):#设置属性值的时候被触发
ident =threading.get_ident()
if ident in self.DIC:
self.DIC[ident][key]=value
else:
self.DIC[ident]={key:value}
通过这个自定义 Local 可以实现相同的功能
在进行升级 改造一下
import threading
try:
import greenlet
get_ident = greenlet.getcurrent
except Exception as e:
get_ident =threading.get_ident
class Loca(object):
DIC ={}
def __getattr__(self, item):
ident = get_ident()
if ident in self.DIC:
return self.DIC[ident].get(item)
return None
def __setattr__(self, key, value):
ident = get_ident()
if ident in self.DIC:
self.DIC[ident][key] = value
else:
self.DIC[ident] ={key:value}
上下文管理流程(第一次)
请求到来的时候
内容回顾
day 117 回顾 day 116
1.django 和 flask 的区别?
不同点:request 操作的机制
共同点:都有视图、路由、都是基于wsgi 协议
flask:扩建性高
2. flask 提供的组件:
- 配置文件:
- 使用
- 原理
- 路由系统:
[过装饰器实现]
[可以不通过装饰器实现]
- 书写方式
- 参数
- 重定向
- 子域名
- 路由本质 装饰器 + 闭包 实现的
- 视图
- CBV class _ view
- 蓝图
- 作用:
- 目录结构的划分
- 前缀
- 应用特殊装饰器
- 特殊装饰器
before_request
after_request [内部做了一个反转]
貌似有六个
???
3. session 实现原理
???
s9day117
前戏:
-偏函数:自动帮你传参数
import functools
def index(a1,a2):
return a1+a2
#new_func = functions.partial(index,“自动帮你传递的参数”)
ret = index(1,2)
print(ret)
new_func = functions.partial(index,“自动帮你传递的参数”)
ret = new_func(‘自己需要传递的参数’)
print(ret)
- 面向对象
- 执行父类的方法
class Base(object):
def func(self):
print(‘Base.func‘)
class Foo(Base):
def func(self):
#方式一:根据mro的顺序执行方法
super(Foo,self).func()
#方式二:主动执行Base类的方法
Base.func(self)
print(‘Foo.func‘)
#注意super 和 Base 两者之间的区别
obj = Foo()
obj.func()
class Base(object):
def func(self):
super(Base,self).func()
print(‘Base.func‘)
class Bar(object):
def func(self):
print(‘Bar.func‘)
class Foo(Base,Bar):
pass
#sample - 1
obj = Foo()
obj.func()
print(Foo.__mro__)
#smaple - 2 #报错
obj = Base()
obj.func()
根据smaple -1 和 sample -2 super 不是找父类的而是根据mro顺序找
class Foo(object):
def __init__(self):
self.storage = {}
def __setattr__(self,key,value):
print(‘self.storage‘)
#这样写直接会报错
#注意执行顺序 和 调用 顺序
#以及属性的存在周期
class Foo(object):
def __init__(self):
object.__setattr__(self,‘storage‘,{})
def __setattr__():
print(self.storage)
#这样调用没毛病
栈:先进先出 [类似弹夹]
class Stack(object):
def __init__(self):
self.data = []
def push(self,val):
self.data.append(val)
def pop(self):#删除
return self.data.pop()
def top(self):#每次都取最后一个
return self.data[-1]
或
if len(data)== 0:
return None
return self.data[len(data)-1]
_statck = Stack()
_stack.push(‘a‘)
_stack.push(‘b‘)
Local 对象
""" { ident:{} } """ from threading import get_ident class Local(object):
def __init__(self): object.__setattr__(self,‘storage‘,{}) def __setattr__(self,key,value): ident = get_ident()#获取唯一标记 if ident not in self.storage: self.storage[ident] = { key : value } else: self.storage[ident][key] = value
def __getattr__(self,item):
ident = get_ident()
if ident in self.storage:
return returnn self.storage[ident].get(item)
#return None
try:
from greenlet import getcurrent as get_ident
except:
from threading import get_ident
from threading import get_ident
class Local(object):
def __init__(self):
object.__setattr__(self,‘storage‘,{})
def __setattr__(self,key,value):
ident = get_ident()#获取唯一标记
if ident not in self.storage:
self.storage[ident] = { key : value }
else:
self.storage[ident][key] = value
def __getattr__(self,item):
ident = get_ident()
if ident in self.storage:
return returnn self.storage[ident].get(item)
#return None
Local 对象
from flask import globals
# context locals
_request_ctx_stack = LocalStack() #在LocalStack() 类 文件上面就是Local()
class Local(object): __slots__ = (‘__storage__‘, ‘__ident_func__‘) def __init__(self): object.__setattr__(self, ‘__storage__‘, {}) object.__setattr__(self, ‘__ident_func__‘, get_ident) def __iter__(self): return iter(self.__storage__.items()) def __call__(self, proxy): """Create a proxy for a name.""" return LocalProxy(self, proxy) def __release_local__(self): self.__storage__.pop(self.__ident_func__(), None) def __getattr__(self, name): try: return self.__storage__[self.__ident_func__()][name] except KeyError: raise AttributeError(name) def __setattr__(self, name, value): ident = self.__ident_func__() storage = self.__storage__ try: storage[ident][name] = value except KeyError: storage[ident] = {name: value} def __delattr__(self, name): try: del self.__storage__[self.__ident_func__()][name] except KeyError: raise AttributeError(name)
LocalStack
上下文管理:request
上下文管理:session
第三方组件:flask-session
代码统计作业
s9day118
代码统计
pymysql
数据库连接池 DBUtils
初步认识:SQLAlchemy
[flask 最有价值的就是上下文管理 ]
内容回归:
falsk :
路由
视图
蓝图
上下文管理:request
__call__
请求进来执行__call__方法
为什么执行__call__方法,因为wsgi
代码统计
[
shutil ???????
class FileStorage(object):
def save(self, dst, buffer_size=16384):
from shutil import copyfileobj
close_dst = False
if isinstance(dst, string_types):
dst = open(dst, ‘wb‘)
close_dst = True
try:
copyfileobj(self.stream, dst, buffer_size)
finally:
if close_dst:
dst.close()
shutil.py
def copyfileobj(fsrc, fdst, length=16*1024):
"""copy data from file-like object fsrc to file-like object fdst"""
while 1:
buf = fsrc.read(length)
if not buf:
break
fdst.write(buf)
]
from flask import Flask
app = Flask(__name__)
app.config[‘MAX_CONTENT_LENGTH‘] = 1024*1024*7 #控制文件上传大小为7m
#假如用户上传文件大小超过7m 会报413的错误
@index.route(‘/upload‘,methods=["GET","POST"])
def upload():
if request.method == "GET":
return render_template(‘upload.html‘)
#from werkzeug.datastructures import FileStorage
file_obj = request.fiels.get(‘code‘)
#print(type(file_obj))
#print(file_obj.filename)#文件名称
#print(file_obj.stream)#文件内容
name_ext = file_obj.filename.rsplite(‘.‘,maxsplit=1)
if len(name_exit) != 2:#说明没有后缀名
return ‘请上传zip压缩文件‘
if name_ext[1] != "zip":
return "请上传zip压缩文件"
file_path = os.path.join(‘files‘,file_obj.filename)#处理保存路径
#从file_obj.stream 中读取内容,在写入文件
file_obj.save(file_path) #保存文件
return “上传成功”
解压zip文件
import shutil
#通过open打开压缩文件,读取内容在进行解压
shutil._unpack_zipfile("需要解压的文件路径","解压之后需要存放的路径")
文件上传与文件解压
3接收用户上传文件,并解压到指定目录
import shutil
shutil._unpack_zipfile(file_obj.stream,‘解压目录‘)
#名称需要做唯一性处理
import uuid
target_path = os.path.join(‘files‘,uuid.uuid4())
#或着每个文件都有唯一性的目录
目录的遍历
#listdir 当前目录所有文件夹
for item in os.listdir(target_path):
print(item)
total_num = 0 #总行数
for base_path ,folder_list,file_list in os.walk(target_path):
for file_name in file_list:
file_path = os.path.join(base_path,file_name)
#单个文件的完整路径
file_ext = file_path.rsplit(‘.‘,maxsplit=1)
if len(file_exit) != 2:
continue
if file_ext[1] != ‘py‘:
continue
file_num = 0
with open(file_path,‘rb‘) as f:
for line in f:
#空格 换行
line = line.strip()#
if not line:
continue
if line.startswith(b‘#‘):#注释
continue
#第三中情况 """ 三引号
file_num += 1
print(file_num,file_path)
total_num += file_num
strip() ??????????
pymysql 操作数据库
helper.py
import pymysql
from ..settings import Config
def connect():
"""
创建连接
:return:
"""
conn = Config.POOL.connection()
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
return conn,cursor
def connect_close(conn,cursor):
"""
释放 连接
:param conn:
:param cursor:
:return:
"""
cursor.close()
conn.close()
def fetch_all(sql,args):
"""
获取所有select *
:param sql:
:param args:
:return:
"""
conn,cursor = connect()
cursor.execute(sql,args)
record_list = cursor.fetchall()
connect_close(conn,cursor)
return record_list
def fetch_one(sql,args):
"""
返回符合sql的第一条数据
:param sql:
:param args:
:return:
"""
conn,cursor = connect()
cursor.execute(sql,args)
result = cursor.fetchone()
connect_close(conn,cursor)
return result
def insert(sql,args):
"""
返回受影响的行数,插入数据
:param sql:
:param args:
:return:
"""
conn,cursor = connect()
row = cursor.execute(sql,args)
conn.commit()
connect_close(conn,cursor)
return row
数据库连接池***
settings.py
from DBUtils.PooledDB import PooledDB,SharedDBConnection
import pymysql
# 加盐
CONFIG_KEYS = {
"SALE": bytes(‘小鸡顿蘑菇‘, encoding=‘utf-8‘)
}
class Config(object):
SALT = bytes(‘小鸡顿蘑菇‘, encoding=‘utf-8‘) #设置password keys
SECREY_KEY = "passlslk。、dflsadk fsaldk" #设置session keys
MAX_CONTENT_LENGTH = 1024*1024*10 #设置上传最大值
POOL = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=5, # 链接池中最多闲置的链接,0和None不限制
maxshared=3,
# 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
# ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always
host=‘127.0.0.1‘,
port=3306,
user=‘root‘,
password=‘‘,
database=‘flask‘,
charset=‘utf8mb4‘
)
s9day119 内容回归
-. django 和 falsk 的认识
-. Flask 基础:
配置文件 app.config.form_object()#两种方式
反射+ importlib
路由系统
装饰器 @app.route()
参数
url
endpoint url_for 默认情况下 等于视图函数名
methods GET/POST [] list
等
自定义加装饰器:
functools.wraps
endpoint 默认是函数名
写路由的两种方式
装饰器:@app.route()
add_url_rule()
自定义支持正则的url
session:
实现原理:以加密的形式存到了浏览器的cookies里面
蓝图:
目录结构的划分
前缀
特殊装饰器:
- 上下文管理
threading.local 数
据隔离[给每个线程开辟内存空间,使得线程之间进行数据隔离]
应用:DBUtils 中为每个线程创建一个数据库连接时使用
面向对象的特殊方法:
getattr
setattr
delattr
偏函数
单例模式
请求上下文的流程:
源码流程:
请求到来执行 __call__
wsgi_app()
ctx = RequestContext(): 封装= 请求数据 + 空session
ctx.push():将ctx 传给LocalStack对象,LocalStack再将数据传给Local 存储起来
问题:Lcoal 中是如何存储?
__storage__={
ident:{}
}
问题:LocalStack 作用?
ident:{stack:[ctx]}
-. 数据库 前端
bootstramp
什么是响应式布局? 根据窗口的不同,显示不同的效果
python 里面那些比较重要:
生成器、 ??????
迭代器、 ??????
装饰器、??????
反射 、 ?????
上下文管理:LocalProxy
上下文管理:
请求上下文:request
App 上下文:app/g
第三方组件:wtforms
使用
原理
Local/LocaStack/LocalProxy
以上是关于flask的主要内容,如果未能解决你的问题,请参考以下文章